
Knowledgebase (2340)
Children categories

HTML parsing is a critical task in Java development, enabling developers to extract structured data, analyze content, and interact with web-based information. Whether you’re building a web scraper, validating HTML content, or extracting text and attributes from web pages, having a reliable tool simplifies the process. In this guide, we’ll explore how to parse HTML in Java using Spire.Doc for Java - a powerful library that combines robust HTML parsing with seamless document processing capabilities.
- Why Use Spire.Doc for Java for HTML Parsing
- Environment Setup & Installation
- Core Guide: Parsing HTML to Extract Elements in Java
- Advanced Scenarios: Parse HTML Files & URLs in Java
- FAQ About Parsing HTML
Why Use Spire.Doc for Java for HTML Parsing
While there are multiple Java libraries for HTML parsing (e.g., Jsoup), Spire.Doc stands out for its seamless integration with document processing and low-code workflow, which is critical for developers prioritizing efficiency. Here’s why it’s ideal for Java HTML parsing tasks:
- Intuitive Object Model: Converts HTML into a navigable document structure (e.g., Section, Paragraph, Table), eliminating the need to manually parse raw HTML tags.
- Comprehensive Data Extraction: Easily retrieve text, attributes, table rows/cells, and even styles (e.g., headings) without extra dependencies.
- Low-Code Workflow: Minimal code is required to load HTML content and process it—reducing development time for common tasks.
- Lightweight Integration: Simple to add to Java projects via Maven/Gradle, with minimal dependencies.
Environment Setup & Installation
To start reading HTML in Java, ensure your environment meets these requirements:
- Java Development Kit (JDK): Version 8 or higher (JDK 11+ recommended for HttpClient support in URL parsing).
- Spire.Doc for Java Library: Latest version (integrated via Maven or manual download).
- HTML Source: A sample HTML string, local file, or URL (for testing extraction).
Install Spire.Doc for Java
Maven Setup: Add the Spire.Doc repository and dependency to your project’s pom.xml file. This automatically downloads the library and its dependencies:
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>14.6.0</version>
</dependency>
</dependencies>
For manual installation, download the JAR from the official website and add it to your project.
Get a Temporary License (Optional)
By default, Spire.Doc adds an evaluation watermark to output. To remove it and unlock full features, you can request a free 30-day trial license.
Core Guide: Parsing HTML to Extract Elements in Java
Spire.Doc parses HTML into a structured object model, where elements like paragraphs, tables, and fields are accessible as Java objects. Below are practical examples to extract key HTML components.
1. Extract Text from HTML in Java
Extracting text (without HTML tags or formatting) is essential for scenarios like content indexing or data analysis. This example parses an HTML string and extracts text from all paragraphs.
Java Code: Extract Text from an HTML String
import com.spire.doc.*;
import com.spire.doc.documents.*;
public class ExtractTextFromHtml {
public static void main(String[] args) {
// Define HTML content to parse
String htmlContent = "<html>" +
"<body>" +
"<h1>Introduction to HTML Parsing</h1>" +
"<p>Spire.Doc for Java simplifies extracting text from HTML.</p>" +
"<ul>" +
"<li>Extract headings</li>" +
"<li>Extract paragraphs</li>" +
"<li>Extract list items</li>" +
"</ul>" +
"</body>" +
"</html>";
// Create a Document object to hold parsed HTML
Document doc = new Document();
// Parse the HTML string into the document
doc.addSection().addParagraph().appendHTML(htmlContent);
// Extract text from all paragraphs
StringBuilder extractedText = new StringBuilder();
for (Section section : (Iterable<Section>) doc.getSections()) {
for (Paragraph paragraph : (Iterable<Paragraph>) section.getParagraphs()) {
extractedText.append(paragraph.getText()).append("\n");
}
}
// Print or process the extracted text
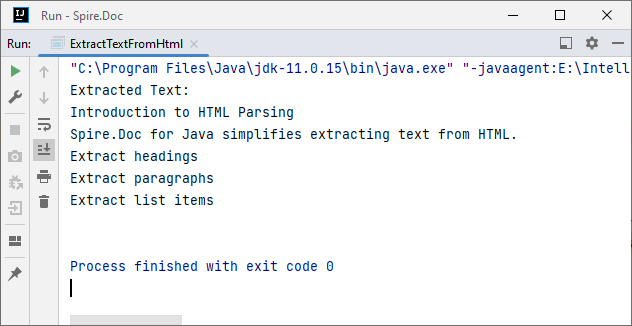
System.out.println("Extracted Text:\n" + extractedText);
}
}
Output:
2. Extract Table Data from HTML in Java
HTML tables store structured data (e.g., product lists, reports). Spire.Doc parses <table> tags into Table objects, making it easy to extract rows and columns.
Java Code: Extract HTML Table Rows & Cells
import com.spire.doc.*;
import com.spire.doc.documents.*;
public class ExtractTableFromHtml {
public static void main(String[] args) {
// HTML content with a table
String htmlWithTable = "<html>" +
"<body>" +
"<table border='1'>" +
"<tr><th>ID</th><th>Name</th><th>Price</th></tr>" +
"<tr><td>001</td><td>Laptop</td><td>$999</td></tr>" +
"<tr><td>002</td><td>Phone</td><td>$699</td></tr>" +
"</table>" +
"</body>" +
"</html>";
// Parse HTML into Document
Document doc = new Document();
doc.addSection().addParagraph().appendHTML(htmlWithTable);
// Extract table data
for (Section section : (Iterable<Section>) doc.getSections()) {
// Iterate through all objects in the section's body
for (Object obj : section.getBody().getChildObjects()) {
if (obj instanceof Table) { // Check if the object is a table
Table table = (Table) obj;
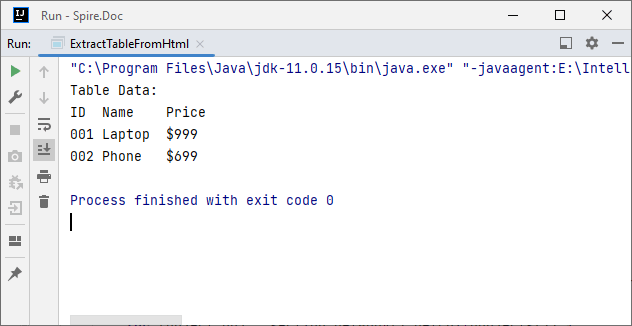
System.out.println("Table Data:");
// Loop through rows
for (TableRow row : (Iterable<TableRow>) table.getRows()) {
// Loop through cells in the row
for (TableCell cell : (Iterable<TableCell>) row.getCells()) {
// Extract text from each cell's paragraphs
for (Paragraph para : (Iterable<Paragraph>) cell.getParagraphs()) {
System.out.print(para.getText() + "\t");
}
}
System.out.println(); // New line after each row
}
}
}
}
}
}
Output:
After parsing the HTML string into a Word document via the appendHTML() method, you can leverage Spire.Doc’s APIs to extract hyperlinks as well.
Advanced Scenarios: Parse HTML Files & URLs in Java
Spire.Doc for Java also offers flexibility to parse local HTML files and web URLs, making it versatile for real-world applications.
1. Read an HTML File in Java
To parse a local HTML file using Spire.Doc for Java, simply load it via the loadFromFile(String filename, FileFormat.Html) method for processing.
Java Code: Read & Parse Local HTML Files
import com.spire.doc.*;
import com.spire.doc.documents.*;
public class ParseHtmlFile {
public static void main(String[] args) {
// Create a Document object
Document doc = new Document();
// Load an HTML file
doc.loadFromFile("input.html", FileFormat.Html);
// Extract and print text
StringBuilder text = new StringBuilder();
for (Section section : (Iterable<Section>) doc.getSections()) {
for (Paragraph para : (Iterable<Paragraph>) section.getParagraphs()) {
text.append(para.getText()).append("\n");
}
}
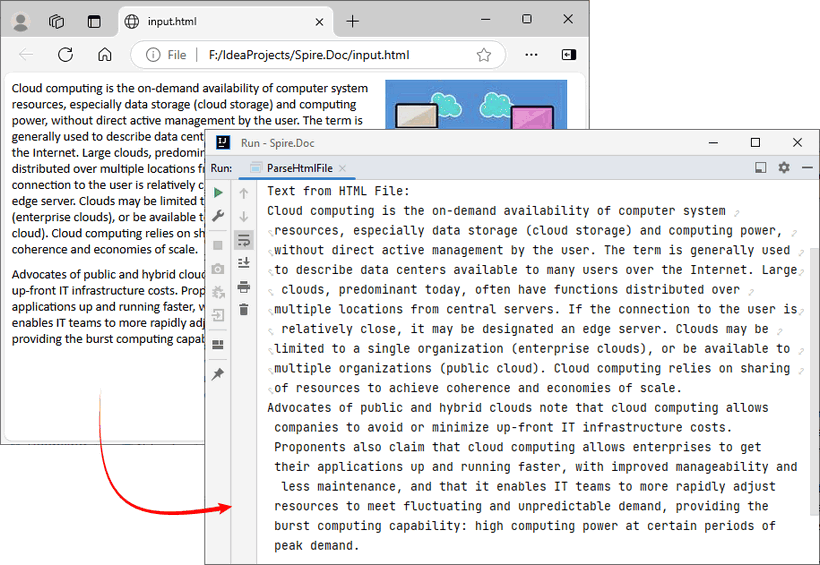
System.out.println("Text from HTML File:\n" + text);
}
}
The example extracts text content from the loaded HTML file. If you need to extract the paragraph style (e.g., "Heading1", "Normal") simultaneously, use the Paragraph.getStyleName() method.
Output:
You may also need: Convert HTML to Word in Java
2. Parse a URL in Java
For real-world web scraping, you'll need to parse HTML from live web pages. Spire.Doc can work with Java’s built-in HttpClient (JDK 11+) to fetch HTML content from URLs, then parse it.
Java Code: Fetch & Parse a Web URL
import com.spire.doc.*;
import com.spire.doc.documents.*;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.time.Duration;
public class ParseHtmlFromUrl {
// Reusable HttpClient (configures timeout to avoid hanging)
private static final HttpClient httpClient = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(10))
.build();
public static void main(String[] args) {
String url = "https://www.e-iceblue.com/privacypolicy.html";
try {
// Fetch HTML content from the URL
System.out.println("Fetching from: " + url);
String html = fetchHtml(url);
// Parse HTML with Spire.Doc
Document doc = new Document();
Section section = doc.addSection();
section.addParagraph().appendHTML(html);
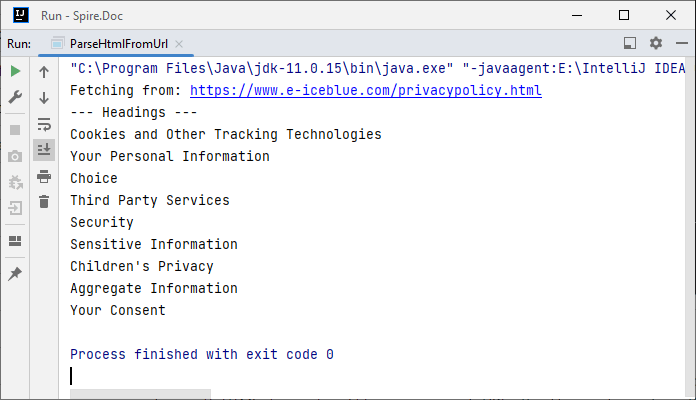
System.out.println("--- Headings ---");
// Extract headings
for (Paragraph para : (Iterable<Paragraph>) section.getParagraphs()) {
// Check if the paragraph style is a heading (e.g., "Heading1", "Heading2")
if (para.getStyleName() != null && para.getStyleName().startsWith("Heading")) {
System.out.println(para.getText());
}
}
} catch (Exception e) {
System.err.println("Error: " + e.getMessage());
}
}
// Helper method: Fetches HTML content from a given URL
private static String fetchHtml(String url) throws Exception {
// Create HTTP request with User-Agent header (to avoid blocks)
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(url))
.header("User-Agent", "Mozilla/5.0")
.timeout(Duration.ofSeconds(10))
.GET()
.build();
// Send request and get response
HttpResponse<String> response = httpClient.send(request, HttpResponse.BodyHandlers.ofString());
// Check if the request succeeded (HTTP 200 = OK)
if (response.statusCode() != 200) {
throw new Exception("HTTP error: " + response.statusCode());
}
return response.body(); // Return the raw HTML content
}
}
Key Steps:
- HTTP Fetching: Uses HttpClient to fetch HTML from the URL, with a User-Agent header to mimic a browser (avoids being blocked).
- HTML Parsing: Creates a Document, adds a Section and Paragraph, then uses appendHTML() to load the fetched HTML.
- Content Extraction: Extracts headings by checking if paragraph styles start with "Heading".
Output:
Conclusion
Parsing HTML in Java is simplified with the Spire.Doc for Java library. Using it, you can extract text, tables, and data from HTML strings, local files, or URLs with minimal code—no need to manually handle raw HTML tags or manage heavy dependencies.
Whether you’re building a web scraper, analyzing web content, or converting HTML to other formats (e.g., HTML to PDF), Spire.Doc streamlines the workflow. By following the step-by-step examples in this guide, you’ll be able to integrate robust HTML parsing into your Java projects to unlock actionable insights from HTML content.
FAQs About Parsing HTML
Q1: Which library is best for parsing HTML in Java?
A: It depends on your needs:
- Use Spire.Doc if you need to extract text/tables and integrate with document processing (e.g., convert HTML to PDF).
- Use Jsoup if you only need basic HTML parsing (but it requires more code for table/text extraction).
Q2: How does Spire.Doc handle malformed or poorly structured HTML?
A: Spire.Doc for Java provides a dedicated approach using the loadFromFile method with XHTMLValidationType.None parameter. This configuration disables strict XHTML validation, allowing the parser to handle non-compliant HTML structures gracefully.
// Load and parse the malformed HTML file
// Parameters: file path, file format (HTML), validation type (None)
doc.loadFromFile("input.html", FileFormat.Html, XHTMLValidationType.None);
However, severely malformed HTML may still cause parsing issues.
Q3: Can I modify parsed HTML content and save it back as HTML?
A: Yes. Spire.Doc lets you manipulate parsed content (e.g., edit paragraph text, delete table rows, or add new elements) and then save the modified document back as HTML:
// After parsing HTML into a Document object:
Section section = doc.getSections().get(0);
Paragraph firstPara = section.getParagraphs().get(0);
firstPara.setText("Updated heading!"); // Modify text
// Save back as HTML
doc.saveToFile("modified.html", FileFormat.Html);
Q4: Is an internet connection required to parse HTML with Spire.Doc?
A: No, unless you’re loading HTML directly from a URL. Spire.Doc can parse HTML from local files or strings without an internet connection. If fetching HTML from a URL, you’ll need an internet connection to retrieve the content first, but parsing itself works offline.

In many modern .NET applications, generating professional-looking PDF documents is a common requirement — especially for invoices, reports, certificates, and forms. Instead of creating PDFs manually, a smarter approach is to use HTML templates . HTML makes it easy to design layouts using CSS, include company branding, and reuse the same structure across multiple documents.
By dynamically inserting data into HTML and converting it to PDF programmatically, you can automate document generation while maintaining design consistency.
In this tutorial, you’ll learn how to generate a PDF from an HTML template in C# .NET using Spire.PDF for .NET. We’ll guide you step-by-step — from setting up your development environment (including the required HTML-to-PDF plugin), preparing the HTML template, inserting dynamic data, and generating the final PDF file.
On this page:
- Why Generate PDFs from HTML Templates in C#?
- Set Up Your .NET Environment
- Prepare an HTML Template
- Insert Dynamic Data into HTML Before Conversion
- Convert Updated HTML Template to PDF in C#
- Best Practices for Generating PDF from HTML in C#
- Final Words
- FAQs About C# HTML Template to PDF Conversion
Why Generate PDFs from HTML Templates in C#?
Using HTML templates for PDF generation offers several advantages:
- Reusability: Design once, reuse anywhere — perfect for reports, receipts, and forms.
- Styling flexibility: HTML + CSS allow rich formatting without complex PDF drawing code.
- Dynamic content: Easily inject runtime data such as customer names, order totals, or timestamps.
- Consistency: Ensure all generated documents follow the same layout and style guidelines.
- Ease of maintenance: You can update the HTML template without changing your C# logic.
Set Up Your .NET Environment
Before you begin coding, make sure your project is properly configured to handle HTML-to-PDF conversion.
1. Install Spire.PDF for .NET
Spire.PDF for .NET is a professional library designed for creating, reading, editing, and converting PDF documents in C# and VB.NET applications—without relying on Adobe Acrobat. It provides powerful APIs for handling text, images, annotations, forms, and HTML-to-PDF conversion.
You can install it via NuGet:
Install-Package Spire.PDF
Or download it directly from the official website and reference the DLL in your project.
2. Install the HTML Rendering Plugin
Spire.PDF relies on an external rendering engine (Qt WebEngine or Chrome) to accurately convert HTML content into PDF. This plugin must be installed separately.
Steps:
- Download the plugin package for your platform.
- Extract the contents to a local folder, such as: C:\plugins-windows-x64\plugins
- In your C# code, register the plugin path before performing the conversion.
HtmlConverter.PluginPath = @"C:\plugins-windows-x64\plugins";
Prepare an HTML Template
Create an HTML file with placeholders for your dynamic data. For example, name it invoice_template.html :
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Invoice</title>
<style>
body { font-family: Arial; margin: 40px; }
.header { font-size: 24px; font-weight: bold; margin-bottom: 20px; }
table { width: 100%; border-collapse: collapse; margin-top: 20px; }
th, td { border: 1px solid #999; padding: 8px; text-align: left; }
</style>
</head>
<body>
<div class="header">Invoice for {CustomerName}</div>
<p>Date: {InvoiceDate}</p>
<table>
<tr><th>Item</th><th>Price</th></tr>
<tr><td>{Item}</td><td>{Price}</td></tr>
</table>
</body>
</html>
Tips:
- Keep CSS inline or embedded within the HTML file.
- Avoid JavaScript or complex animations.
- Use placeholders like {CustomerName} and {InvoiceDate} for data replacement.
Insert Dynamic Data into HTML Before Conversion
You can read your HTML file as text, replace placeholders with real values, and then save it as a new temporary file.
using System;
using System.IO;
string template = File.ReadAllText("invoice_template.html");
template = template.Replace("{CustomerName}", "John Doe");
template = template.Replace("{InvoiceDate}", DateTime.Now.ToShortDateString());
template = template.Replace("{Item}", "Wireless Mouse");
template = template.Replace("{Price}", "$25.99");
File.WriteAllText("invoice_ready.html", template);
This approach lets you generate customized PDFs for each user or transaction dynamically.
Convert Updated HTML Template to PDF in C#
Now that your HTML content is ready, you can use the HtmlConverter.Convert() method to directly convert the HTML string into a PDF file.
Below is a full code example to create PDF from HTML template file in C#:
using System;
using System.Collections.Generic;
using System.Drawing;
using System.IO;
using Spire.Additions.Qt;
using Spire.Pdf.Graphics;
using Spire.Pdf.HtmlConverter;
namespace CreatePdfFromHtmlTemplate
{
class Program
{
static void Main(string[] args)
{
// Path to the HTML template file
string htmlFilePath = "invoice_template.html";
// Step 1: Read the HTML template from file
if (!File.Exists(htmlFilePath))
{
Console.WriteLine("Error: HTML template file not found.");
return;
}
string htmlTemplate = File.ReadAllText(htmlFilePath);
// Step 2: Define dynamic data for invoice placeholders
Dictionary<string, string> invoiceData = new Dictionary<string, string>()
{
{ "INVOICE_NUMBER", "INV-2025-001" },
{ "INVOICE_DATE", DateTime.Now.ToString("yyyy-MM-dd") },
{ "BILLER_NAME", "John Doe" },
{ "BILLER_ADDRESS", "123 Main Street, New York, USA" },
{ "BILLER_EMAIL", "[email protected]" },
{ "ITEM_DESCRIPTION", "Consulting Services" },
{ "ITEM_QUANTITY", "10" },
{ "ITEM_UNIT_PRICE", "$100" },
{ "ITEM_TOTAL", "$1000" },
{ "SUBTOTAL", "$1000" },
{ "TAX_RATE", "5" },
{ "TAX", "$50" },
{ "TOTAL", "$1050" }
};
// Step 3: Replace placeholders in the HTML template with real values
string populatedInvoice = PopulateInvoice(htmlTemplate, invoiceData);
// Optional: Save the populated HTML for debugging or review
File.WriteAllText("invoice_ready.html", populatedInvoice);
// Step 4: Specify the plugin path for the HTML to PDF conversion
string pluginPath = @"C:\plugins-windows-x64\plugins";
HtmlConverter.PluginPath = pluginPath;
// Step 5: Define output PDF file path
string outputFile = "InvoiceOutput.pdf";
try
{
// Step 6: Convert the HTML string to PDF
HtmlConverter.Convert(
populatedInvoice,
outputFile,
enableJavaScript: true,
timeout: 100000, // 100 seconds
pageSize: new SizeF(595, 842), // A4 size in points
margins: new PdfMargins(20), // 20-point margins
loadHtmlType: LoadHtmlType.SourceCode
);
Console.WriteLine($"PDF generated successfully: {outputFile}");
}
catch (Exception ex)
{
Console.WriteLine($"Error during PDF generation: {ex.Message}");
}
}
/// <summary>
/// Helper method: Replaces placeholders in the HTML with actual data values.
/// </summary>
private static string PopulateInvoice(string template, Dictionary<string, string> data)
{
string result = template;
foreach (var entry in data)
{
result = result.Replace("{" + entry.Key + "}", entry.Value);
}
return result;
}
}
}
How it works :
- Create an invoice template with placeholder variables in {VARIABLE_NAME} format.
- Set up a dictionary with key-value pairs containing actual invoice data that matches the template placeholders.
- Replace all placeholders in the HTML template with actual values from the data dictionary.
- Use Spire.PDF with the Qt plugin to render the HTML content as a PDF file.
Result:

Best Practices for Generating PDF from HTML in C#
- Use fixed-width layouts: Avoid fluid or responsive designs to maintain consistent rendering.
- Embed or inline CSS: Ensure your styles are self-contained.
- Use standard fonts: Arial, Times New Roman, or other supported fonts convert reliably.
- Keep images lightweight: Compress large images to improve performance.
- Test with different page sizes: A4 and Letter are the most common formats.
- Avoid unsupported tags: Elements relying on JavaScript (like <canvas>) won’t render.
Final Words
Generating PDFs from HTML templates in C# .NET is a powerful way to automate document creation while preserving visual consistency. By combining Spire.PDF for .NET with the HTML rendering plugin , you can easily transform styled HTML layouts into print-ready PDF files that integrate seamlessly with your applications.
Whether you’re building a reporting system, an invoicing tool, or a document automation service, this approach saves time, reduces complexity, and produces professional results with minimal code.
FAQs About C# HTML Template to PDF Conversion
Q1: Can I use Google Chrome for HTML rendering instead of Qt WebEngine?
Absolutely. For advanced HTML, CSS, or modern JavaScript, we recommend using the Google Chrome engine via the ChromeHtmlConverter class for more precise and reliable PDF results.
For a complete guide, see our article: Convert HTML to PDF using ChromeHtmlConverter
Q2: Do I need to install a plugin for every machine running my application?
Yes, each environment must have access to the HTML rendering plugin (Qt or Chrome engine) for successful HTML-to-PDF conversion.
Q3: Does Spire.PDF support external CSS files or online resources?
Yes, but inline or embedded CSS is recommended for better rendering accuracy.
Q4: Can I use this approach in ASP.NET or web APIs?
Absolutely. You can generate PDFs server-side and return them as downloadable files or streams.
Q5: Is JavaScript supported during HTML rendering?
Limited support. Static elements are rendered correctly, but scripts and dynamic DOM manipulations are not executed.
Get a Free License
To fully experience the capabilities of Spire.PDF for .NET without any evaluation limitations, you can request a free 30-day trial license.
Generate PDFs from Templates in Java (HTML-to-PDF Explained)
2025-10-17 09:43:21 Written by zaki zou
In many Java applications, you’ll need to generate PDF documents dynamically — for example, invoices, reports, or certificates. Creating PDFs from scratch can be time-consuming and error-prone, especially with complex layouts or changing content. Using templates with placeholders that are replaced at runtime is a more maintainable and flexible approach, ensuring consistent styling while separating layout from data.
In this article, we’ll explore how to generate PDFs from templates in Java using Spire.PDF for Java, including practical examples for both HTML and PDF templates. We’ll also highlight best practices, common challenges, and tips for creating professional, data-driven PDFs efficiently.
Table of Contents
- Why Use Templates for PDF Generation
- Choosing the Right Template Format (HTML, PDF, or Word)
- Setting Up the Environment
- Generating PDFs from Templates in Java
- Best Practices for Template-Based PDF Generation
- Final Thoughts
- FAQs
Why Use Templates for PDF Generation
- Maintainability : Designers or non-developers can edit templates (HTML, PDF, or Word) without touching code.
- Separation of concerns : Your business logic is decoupled from document layout.
- Consistency : Templates enforce consistent styling, branding, and layout across all generated documents.
- Flexibility : You can switch or update templates without major code changes.
Choosing the Right Template Format (HTML, PDF, or Word)
Each template format has strengths and trade-offs. Understanding them helps you pick the best one for your use case.
| Template Format | Pros | Cons / Considerations | Ideal Use Cases |
|---|---|---|---|
| HTML | Full control over layout via CSS, tables, responsive design; easy to iterate | Needs an HTML-to-PDF conversion engine (e.g. Qt WebEngine, headless Chrome) | Invoices, reports, documents with variable-length content, tables, images |
| You can take an existing branded PDF and replace placeholders | Only supports simple inline text replacements (no reflow for multiline content) | Templates with fixed layout and limited dynamic fields (e.g. contracts, certificates) | |
| Word (DOCX) | Familiar to non-developers; supports rich editing | Requires library (like Spire.Doc) to replace placeholders and convert to PDF | Organizations with existing Word-based templates or documents maintained by non-technical staff |
In practice, for documents with rich layout and dynamic content, HTML templates are often the best choice. For documents where layout must be rigid and placeholders are few, PDF templates can suffice. And if your stakeholders prefer Word-based templates, converting from Word to PDF may be the most comfortable workflow.
Setting Up the Environment
Before you begin coding, set up your project for Spire.PDF (and possibly Spire.Doc) usage:
- Download / add dependency
- (If using HTML templates) Install HTML-to-PDF engine / plugin
Spire.PDF needs an external engine or plugin (e.g. Qt WebEngine or a headless Chrome /Chromium) to render HTML + CSS to PDF.
- Download the appropriate plugin for your platform (Windows x86, Windows x64, Linux, macOS).
- Unzip to a local folder and locate the plugins directory, e.g.: C:\plugins-windows-x64\plugins
- Configure the plugin path in code:
- Prepare your templates
To get started, download Spire.PDF for Java from our website and add the JAR files to your project's build path. If you’re using Maven, include the following dependency in your pom.xml.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<version>12.6.1</version>
</dependency>
</dependencies>
HtmlConverter.setPluginPath("C:\\plugins-windows-x64\\plugins");
- For HTML: define placeholders (e.g. {{PLACEHOLDER}}) in your template HTML / CSS.
- For PDF: build or procure a base PDF that includes placeholder text (e.g. {PROJECT_NAME}) in the spots you want replaced.
Generating PDFs from Templates in Java
From an HTML Template
Here’s how you can use Spire.PDF to convert an HTML template into a PDF document, replacing placeholders with actual data.
Sample Code (HTML → PDF)
import com.spire.pdf.graphics.PdfMargins;
import com.spire.pdf.htmlconverter.LoadHtmlType;
import com.spire.pdf.htmlconverter.qt.HtmlConverter;
import com.spire.pdf.htmlconverter.qt.Size;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.HashMap;
import java.util.Map;
public class GeneratePdfFromHtmlTemplate {
public static void main(String[] args) throws Exception {
// Path to the HTML template file
String htmlFilePath = "template/invoice_template.html";
// Read HTML content from file
String htmlTemplate = new String(Files.readAllBytes(Paths.get(htmlFilePath)));
// Sample data for invoice
Map invoiceData = new HashMap<>();
invoiceData.put("INVOICE_NUMBER", "12345");
invoiceData.put("INVOICE_DATE", "2025-08-25");
invoiceData.put("BILLER_NAME", "John Doe");
invoiceData.put("BILLER_ADDRESS", "123 Main St, Anytown, USA");
invoiceData.put("BILLER_EMAIL", "[email protected]");
invoiceData.put("ITEM_DESCRIPTION", "Consulting Services");
invoiceData.put("ITEM_QUANTITY", "10");
invoiceData.put("ITEM_UNIT_PRICE", "$100");
invoiceData.put("ITEM_TOTAL", "$1000");
invoiceData.put("SUBTOTAL", "$1000");
invoiceData.put("TAX_RATE", "5");
invoiceData.put("TAX", "$50");
invoiceData.put("TOTAL", "$1050");
// Replace placeholders with actual values
String populatedHtml = populateTemplate(htmlTemplate, invoiceData);
// Output PDF file
String outputFile = "output/Invoice.pdf";
// Set the QT plugin path for HTML conversion
HtmlConverter.setPluginPath("C:\\plugins-windows-x64\\plugins");
// Convert HTML string to PDF
HtmlConverter.convert(
populatedHtml,
outputFile,
true, // Enable JavaScript
100000, // Timeout (ms)
new Size(595, 842), // A4 size
new PdfMargins(20), // Margins
LoadHtmlType.Source_Code // Load HTML from string
);
System.out.println("PDF generated successfully: " + outputFile);
}
/**
* Replace placeholders in HTML template with actual values.
*/
private static String populateTemplate(String template, Map data) {
String result = template;
for (Map.Entry entry : data.entrySet()) {
result = result.replace("{{" + entry.getKey() + "}}", entry.getValue());
}
return result;
}
}How it work:
- Design an HTML file using CSS, tables, images, etc., with placeholders (e.g. {{NAME}}).
- Store data values in a Map<String, String>.
- Replace placeholders with actual values at runtime.
- Use HtmlConverter.convert to generate a styled PDF.
This approach works well when your content may grow or shrink (tables, paragraphs), because HTML rendering handles flow and wrapping.
Output:

From a PDF Template
If you already have a branded PDF template with placeholder text, you can open it and replace inline text within.
Sample Code (PDF placeholder replacement)
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.texts.PdfTextReplaceOptions;
import com.spire.pdf.texts.PdfTextReplacer;
import com.spire.pdf.texts.ReplaceActionType;
import java.util.EnumSet;
import java.util.HashMap;
import java.util.Map;
public class GeneratePdfFromPdfTemplate {
public static void main(String[] args) {
// Create a PdfDocument object
PdfDocument doc = new PdfDocument();
// Load a PDF file
doc.loadFromFile("C:\\Users\\Administrator\\Desktop\\Template.pdf");
// Create a PdfTextReplaceOptions object and specify the options
PdfTextReplaceOptions textReplaceOptions = new PdfTextReplaceOptions();
textReplaceOptions.setReplaceType(EnumSet.of(ReplaceActionType.WholeWord));
// Get a specific page
PdfPageBase page = doc.getPages().get(0);
// Create a PdfTextReplacer object based on the page
PdfTextReplacer textReplacer = new PdfTextReplacer(page);
textReplacer.setOptions(textReplaceOptions);
// Dictionary for old and new strings
Map<String, String> replacements = new HashMap<>();
replacements.put("{PROJECT_NAME}", "New Website Development");
replacements.put("{PROJECT_NO}", "2023-001");
replacements.put("{PROJECT MANAGER}", "Alice Johnson");
replacements.put("{PERIOD}", "Q3 2023");
replacements.put("{PERIOD}", "Q3 2023");
replacements.put("{START_DATE}", "Jul 1, 2023");
replacements.put("{END_DATE}", "Sep 30, 2023");
// Loop through the dictionary to replace text
for (Map.Entry<String, String> pair : replacements.entrySet()) {
textReplacer.replaceText(pair.getKey(), pair.getValue());
}
// Save the document to a different PDF file
doc.saveToFile("output/FromPdfTemplate.pdf");
doc.dispose();
}
}
How it works:
- Load an existing PDF template .
- Use PdfTextReplacer to find and replace placeholder text.
- Save the updated file as a new PDF.
This method works only for inline, simple text replacement . It does not reflow or adjust layout if the replacement text is longer or shorter.
Output:

Best Practices for Template-Based PDF Generation
Here are some tips and guidelines to ensure reliability, maintainability, and quality of your generated PDFs:
- Use HTML templates for rich content : If your document includes tables, variable-length sections, images, or requires responsive layouts, HTML templates offer more flexibility.
- Use PDF templates for stable, fixed layouts : When your document layout is tightly controlled and only a few placeholders change, PDF templates can save you the effort of converting HTML.
- Support Word templates if your team relies on them : If your design team uses Word, use Spire.Doc for Java to replace placeholders in DOCX and export to PDF.
- Unique placeholder markers : Use distinct delimiters (e.g. {FIELD_NAME}, or {FIELD_DATE}) to avoid accidental partial replacements.
- Keep templates external and versioned : Don’t embed template strings in code. Store them in resource files or external directories.
- Test with real data sets : Use realistic data to validate layout — e.g. long names, large tables, multilingual text.
Final Thoughts
Generating PDFs from templates is a powerful, maintainable approach — especially in Java applications. Depending on your needs:
- Use HTML templates when you require dynamic layout, variable-length content, and rich styling.
- Use PDF templates when your layout is fixed and you only need to swap a few fields.
- Leverage Word templates (via Spire.Doc) if your team already operates in that environment.
By combining a clean template system with Spire.PDF (and optionally Spire.Doc), you can produce high-quality, data-driven PDFs in a maintainable, scalable way.
FAQs
Q1. Can I use Word templates (DOCX) in Java for PDF generation?
Yes. Use Spire.Doc for Java to load a Word document, replace placeholders, and export to PDF. This workflow is convenient if your organization already maintains templates in Word.
Q2. Can I insert images or charts into templates?
Yes. Whether you generate PDFs from HTML templates or modify PDF templates, you can embed images, charts, shapes, etc. Just ensure your placeholders or template structure allow space for them.
Q3. Why do I need Qt WebEngine or Chrome for HTML-to-PDF conversion?
The HTML-to-PDF conversion must render CSS, fonts, and layout precisely. Spire.PDF delegates the heavy lifting to an external engine (e.g. Qt WebEngine or Chrome). Without a plugin, styles may not render correctly.
Q4. Does Spire.PDF support multiple languages / international text in templates?
Yes. Spire.PDF supports Unicode and can render multilingual content (English, Chinese, Arabic, etc.) without losing formatting.
Get a Free License
To fully experience the capabilities of Spire.PDF for Java without any evaluation limitations, you can request a free 30-day trial license.
