
Spire.Doc for Java
Java Word Library – Create Read Modify Print Convert Word Documents in Java
- Overview
- Features
- Support
- What's New
- Live Demo
Over 1,000,000 Developers Are Already Using Our Libraries
To Create Their Amazing Applications.
To Create Their Amazing Applications.
Spire.Doc for Java is a professional Word API that empowers Java applications to create, convert, manipulate and print Word documents without dependency on Microsoft Word.
By using this multifunctional library, developers are able to process copious tasks effortlessly, such as inserting image, hyperlink, digital signature, bookmark and watermark, setting header and footer, creating table, setting background image, and adding footnote and endnote.
In addition, Spire.Doc for Java supports file format conversions from Word to PDF, XPS, Image, EPUB, HTML, TXT, ODT, RTF, WordML, WordXML and many more.
-

Convert
-

Compare
-

Extract
-

eSign
-

Watermark
-

Replace
-

Mail Merge
-

Highlight
-

Header
-

Form
Convert Word to PDF
PDF files are preferred over Word documents because they are safe, simple to open, and easy to manage on any device. PDF is the most popular file format that users would convert Word to.
Compare Documents
If you receive two nearly-identical Word documents, the ideal way to determine whether there are any differences between them is to compare the two documents.

Extract Text and Images
When you just need to get the information in a Word document regardless of its format and structure, you can simply extract the text and images from the document.

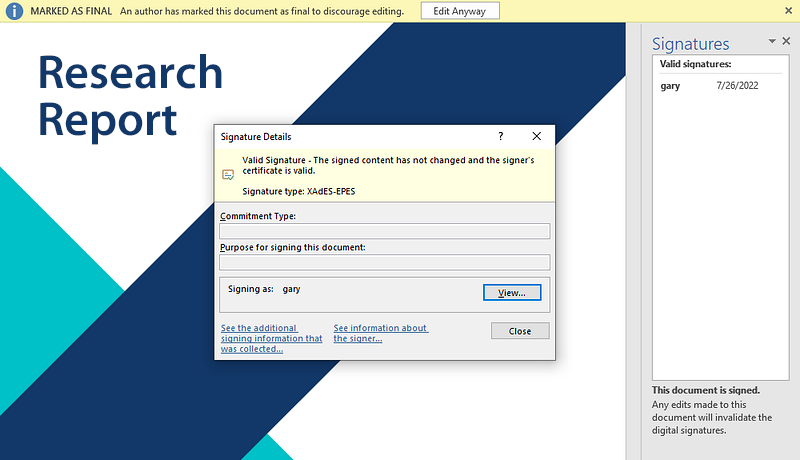
Digitally Sign Documents
A digital signature provides assurances about the validity and authenticity of your Word documents. Once a Word document is digitally signed, any changes to the document will invalidate the signature.
Add a Watermark
A watermark is used to declare confidentiality, copyright, or other attributes of the document, or as a decoration to make the document more attractive. You can add either text or image watermarks to Word documents.

Replace Text
The ability to replace existing text (or placeholders) in a Word document makes it possible for programmers to quickly generate Word reports or documents based on a template.

Mail Merge
Mail Merge is a handy feature that allows you to quickly produce multiple documents, such as letters or emails, using information stored in a list, spreadsheet or database.

Find and Highlight
If you want to emphasize some words, you can find and highlight them in a bright color so that the readers could catch them easily.

Headers and Footers
Headers and footers are useful for including information that you want to appear on every page of a document, such as company logo or page number.

Create a Form
Form fields make it easier to collect information. Users can enter information by choosing an item from a drop-down list, inserting text in a combo box, or checking a check box.

JAVA
Standalone Java Component
100% independent Java Word class library
Doesn't require Microsoft Office installed on system.
VERSION
- Word 97-03
- Word 2007
- Word 2010
- Word 2013
- Word 2016
- Word 2019
OPERATION
Powerful Toolset, Multichannel Support
-

Mail Merge, Create Field, Fill Field, Update Field
-

Protect, Encrypt, Decrypt
-

Find Replace Highlight
-

Insert, Edit, remove bookmark
-

Image and Shape
-

Merge and Split Word document
-

Header and Footer
-

Insert, Reply, remove comment
-

Create & Update Table
-

Print Word Document
-

Create, Modify, Remove hyperlink
CONVERSION
Conversion File Documents with High Quality
-
PDF
-
XPS
-
EPUB
-
SVG
-
PCL
-
Image

Doc/Docx
-
ODT
-
XML
-
HTML
-
RTF
-
TXT
-
PNG
-
BMP
-
JPEG



MAIN FUNCTION
Only Spire.Doc for Java, No Microsoft Office
Spire.Doc for Java is a totally independent Word component, Microsoft Office is not required in order to use Spire.Doc for Java.High Quality File Conversion
Spire.Doc for Java allows converting popular file formats like HTML, RTF, ODT, TXT, WordML, WordXML to Word and exporting Word to commonly used file formats such as PDF, XPS, Image, EPUB, HTML, TXT, ODT, RTF, WordML, WordXML in high quality. Moreover, conversion between Doc and Docx is supported as well.Support a Rich Set of Word Elements
Spire.Doc for Java supports a rich set of Word elements, including section, header, footer, footnote, endnote, paragraph, list, table, text, TOC, form field, mail merge, hyperlink, bookmark, watermark, image, style, shape, textbox, ole, WordArt, background settings, digital signature, document encryption and many more.Easy Integration
Spire.Doc for Java can be easily integrated into Java applications.Commercial Edition $999
Compared with Free Spire.Doc for Java, the commercial edition of Spire.Doc for Java has no limitation on the number of paragraphs and tables and is more comprehensive in processing Word files.
Free Edition $0
Free Spire.Doc for Java is limited to 500 paragraphs and 25 tables. This limitation is enforced during reading or writing files. When converting Word documents to PDF and XPS files, you can only get the first 3 pages of PDF file.
GET STARTED
Free Trials for All Progress Solutions
Here is a brief summary of Spire.Doc for Java features.
Generating, Writing, Editing and Saving
Spire.Doc for Java enables quick generating, saving, writing and editing Word documents.- Generate and save Word documents (Word 97-2003, Word 2007, Word 2010, Word 2013, Word 2016 and Word 2019).
- Load and save document with macros, including .doc (Word 97-2003) document with macros and .docm(Word 2007, Word 2010, Word 2013, Word 2016 and Word 2019) document.
- Write and edit text and paragraphs.
Converting
Spire.Doc for Java enables converting Word documents to most common and popular formats.- Bi-directional conversion Doc-Docx: Convert .doc document (Word 97-2003) to .docx document (Word 2007, Word 2010, Word 2013, Word 2016 and Word 2019) and vice versa.
- Bi-directional conversion Doc(x)-RTF: Convert .doc(x) document to RTF (Rich Text Format) and vice versa.
- Bi-directional conversion Doc(x)-TXT: Convert .doc(x) document to TXT (Plain Text) and enable to load TXT file and save as .doc(x) document.
- Bi-directional conversion Doc(x)-HTML: Convert .doc(x) document to HTML file and enable to load HTML file and save as .doc(x) document.
- Bi-directional conversion Doc(x)-Dot: Convert .doc(x) document to Dot and vice versa.
- Bi-directional conversion Doc(x)-XML: Convert .doc(x) document to XML and enable to load XML file and save as .doc(x) document.
- Unidirectional Conversion Doc(x)-XPS: Convert .doc(x) document to XPS document.
- Unidirectional Conversion: Doc(x)-EPUB: Convert .doc(x) document to EPUB (Digital Publishing).
- Unidirectional Conversion: Doc(x)-PDF: Convert .doc(x) document to PDF in high quality, including contents and formats.
Inserting, Editing and Removing Objects
Spire.Doc for Java enables to inserting, editing and removing external objects in Word.- Find and replace specified string.
- Insert and remove comment, bookmark, table, text, paragraph or section.
- Merge multiple Word documents into one.
- Protect documents to prevent from opening, editing, printing etc.
- Open and decrypt documents in protection.
- Extract text, images etc. from document.
- Load and save document with macros. Remove macros in document.
- Create form field including elements: cells, texts, radio button, dropdown list, checkbox etc.
- Fill form field by connecting data from xml file.
- Create and edit document properties.
- Clear macros in .doc and .docm document.
Formatting
Spire.Doc for Java enables formatting contents in documents, including character, paragraphs, pages and whole document.- Format all characters in document, including fonts, sizes, colors, effects etc.
- Format paragraphs, including built-in styles, indents, spacing, bullets, alignment, headings and number list style etc.
- Format Word tables, including cell fonts and colors, cell background color, cell alignment, cell borders and column width/row height setting.
- Format Word page, including page breaks, border, margins, paper size and orientation.
- View document with different document view types, zoom percent and zoom types.
Mail Merge
Spire.Doc for Java enables executing mail merge function to create records, orders and reports.- Perform simple mail merge fields (name and value) to create single item.
- Execute mail merge to create a group of data records with connecting customized data source.
|
Frequently asked question for Spire.Doc for Java of technical and function issues. |
We guarantee one business day Forum questions Reply. |
We guarantee one business day E-mail response. |
|||||||||||
|
Free Customized service for OEM Users. |
Skype name: iceblue.support |
Apply for a Free Trial License File. |
|||||||||||
To help you get started quickly, we offer free customized demos to our customers. Please contact support@e-iceblue.com for the free demo. Make sure the demo you want meets the below requirements.
- It relates to our components stored on E-iceblue online store.
- It costs less than 2 hours for us to complete it. If it costs more than 2 hours, please contact our sales@e-iceblue.com
If you have tried out Spire.Doc for Java and found it useful, please consider sharing your experience with others. By sharing your testimonial with us, you will not only help others to make the right decision but will also to earn rewards from us. Please send your testimonials to sales@e-iceblue.com.
This is the list of changelogs of Spire.Doc for Java New release and hotfix. You can get the detail information of each version's new features and bug solutions.
Download Spire.Doc for Java to start a free trial:
Version: 12.7.6
| Category | ID | Description |
| Bug | SPIREDOC-10082 SPIREDOC-10362 |
Fixes the issue that the content layout was not correct after converting RTF to PDF and Word. |
| Bug | SPIREDOC-10444 | Fixes the issue that the content was lost after loading and saving RTF. |
| Bug | SPIREDOC-10461 | Fixes the issue that the program threw "For input string: 20" error when loading RTF. |
| Bug | SPIREDOC-10462 | Fixes the issue that the program threw "Index 4 out of bounds for length 4" error when loading RTF. |
Version: 12.6.2
| Category | ID | Description |
| New feature | SPIREDOC-10465 | Supports displaying a prompt message when a corresponding font is not found during Word conversion.
Document doc = ConvertUtil.GetNewEngineDocument();
doc.loadFromFile(input);
HandleDocumentSubstitutionWarnings substitutionWarningHandler = new HandleDocumentSubstitutionWarnings();
doc.setWarningCallback(substitutionWarningHandler);
doc.saveToFile(output_1);
StringBuilder sb = new StringBuilder();
Iterator iterator = substitutionWarningHandler.FontWarnings.iterator();
while(iterator.hasNext()){
System.out.println(((WarningInfo)iterator.next()).getDescription());
}
String s = substitutionWarningHandler.FontWarnings.get(0).getDescription();
WarningSource warningSource = substitutionWarningHandler.FontWarnings.get(0).getSource();
substitutionWarningHandler.FontWarnings.clear();
class HandleDocumentSubstitutionWarnings implements IWarningCallback
{
public void warning(WarningInfo info) {
if(info.getWarningType() == WarningType.Font_Substitution)
FontWarnings.warning(info);
}
public WarningInfoCollection FontWarnings = new WarningInfoCollection();
}
|
| Bug | SPIREDOC-10413 | Fixes the issue that the text shifted upwards when converting a Word document to PDF. |
| Bug | SPIREDOC-10486 | Fixes the issue that the content layout was inconsistent when converting a Word document to PDF. |
| Bug | SPIREDOC-10504 | Fixes the issue that the application threw a "'td' is expected" error when converting an HTML to Word. |
| Bug | SPIREDOC-10589 | Fixes the issue that text content was partially lost when converting a Word document to an image. |
| Bug | SPIREDOC-10592 | Fixes the issue that the application threw a "String index out of range: -1" error when converting a Word document to PDF |
Version: 12.5.1
| Category | ID | Description |
| New feature | SPIREDOC-10156 | Supports ignoring headers and footers when comparing PDF documents.
CompareOptions options=new CompareOptions(); Options.IgnoreHeadersAndFooters=true;//Default is false |
| Bug | SPIREDOC-9330 SPIREDOC-10446 |
Fixes the issue that the text was garbled after converting a DOCX document to a PDF document. |
| Bug | SPIREDOC-9309 | Fixes the issue that the content was messed up after converting a DOCX document to a PDF document. |
| Bug | SPIREDOC-9349 | Fixes the issue that the content appeared different when it was opened with WPS tool after loading and saving the document. |
| Bug | SPIREDOC-10137 | Fix the issue that the text direction of the vertical text box was incorrect after converting a Word document to a PDF document. |
| Bug | SPIREDOC-10373 | Fix the issue that the program threw "cannot be cast to java.lang.Float" exception when comparing Word documents. |
| Bug | SPIREDOC-10383 | Fixed the issue that the paragraph alignment was incorrect after converting HTML to Word documents. |
| Bug | SPIREDOC-10408 | Fixed the issue that the program threw "Specified argument was out of the range of valid values" exception when loading Word documents. |
| Bug | SPIREDOC-10455 | Fix the issue that paging was incorrect after converting Word documents to PDF documents using WPS rules. |
| Bug | SPIREDOC-10459 | Fixed the issue that images were rotated after converting Word documents to PDF documents. |
| Bug | SPIREDOC-10466 | Fix the issue that extra content appeared after converting Word documents to PDF documents. |
| Bug | SPIREDOC-10481 | Fix the problem that the program threw a "NullPointerException" when converting Word documents to PDF documents. |
| Bug | SPIREDOC-10485 | Fix the issue that extra blank pages appeared after converting Word documents to PDF documents using WPS rules. |
| Bug | SPIREDOC-10513 | Fix the issue that the content of the drop-down box was garbled after converting a Word document to a PDF document. |
Version: 12.4.14
| Category | ID | Description |
| Bug | SPIREDOC-9330 SPIREDOC-10446 |
Fixes the issue that the text was garbled after converting a DOCX document to a PDF document. |
| Bug | SPIREDOC-9309 | Fixes the issue that the content was messed up after converting a DOCX document to a PDF document. |
| Bug | SPIREDOC-9349 | Fixes the issue that the content appeared different when it was opened with WPS tool after loading and saving the document. |
Version: 12.4.6
| Category | ID | Description |
| New feature | SPIREDOC-10091 | Supports loading and operating MarkDown documents, or converting word documents to MarkDown.
Document doc = new Document();
//load .md file
doc.loadFromFile("input.md");
//save to .md file
doc.saveToFile("output.md", com.spire.doc.FileFormat.Markdown);
//save to .docx file
//doc.saveToFile("output.docx", com.spire.doc.FileFormat.Docx);
//save to .doc file
//doc.saveToFile("output.doc", com.spire.doc.FileFormat.Doc);
//save to .pdf file
//doc.saveToFile("output.pdf", com.spire.doc.FileFormat.PDF);
doc.close();
Document doc = new Document();
//load .docx file
doc.loadFromFile("input.docx");
//load .doc file
//doc.loadFromFile("input.doc");
//save to .md file
doc.saveToFile("output.md", com.spire.doc.FileFormat.Markdown);
doc.close();
|
| Bug | SPIREDOC-9801 | Fixes the issue that the content format was inconsistent after converting Word to PDF. |
| Bug | SPIREDOC-10038 | Fixes the issue that the rest content of the document was changed after replacing the content of bookmarks. |
| Bug | SPIREDOC-10073 | Optimizes the document size of Word to PDF conversion results. |
| Bug | SPIREDOC-10183 | Fixes the issue that the result document of comparison reported an error when opening. |
| Bug | SPIREDOC-10237 | Fixes the issue that the content was not formatted correctly after converting Word to HTML. |
| Bug | SPIREDOC-10283 | Fixes the issue that it reported "Cannot found font insatlled on the system" error when converting Word to PDF on linux environment without any fonts installed. |
| Bug | SPIREDOC-10292 | Fixes the issue that the number of pages was incorrect after converting Word to SVG. |
| Bug | SPIREDOC-10364 | Fixes the issue that it reported "Error loading file: Unsupported file format" error when loading ODT file. |
| Bug | SPIREDOC-10369 | Fixes the issue that the generated Word documents could not be opened by WeChat on Apple mobile devices. |
| Bug | SPIREDOC-10387 | Optimizes FixedLayoutLine.getRectangle() method to get its height and width, i.e. FixedLayoutLine.getRectangle().width and FixedLayoutLine.getRectangle().height. |
Version: 12.3.1
| Category | ID | Description |
| Improvement | SPIREDOC-10325 | Optimizes the file size of the resulting document of Word to OFD conversion. |
| New feature | - | Adds the setImageLink() in MergeImageFieldEventArgs event to support adding hyperlinks to the mail merge images.
Document document = new Document();
document.loadFromFile(inputFile);
String[] fieldNames = new String[]{"ImageFile"};
String[] fieldValues = new String[]{inputFile_img};
document.getMailMerge().MergeImageField = new MergeImageFieldEventHandler() {
@Override
public void invoke(Object sender, MergeImageFieldEventArgs args) {
mailMerge_MergeImageField(sender, args);
}
};
document.getMailMerge().execute(fieldNames, fieldValues);
document.saveToFile(outputFile, FileFormat.Docx);
private static void mailMerge_MergeImageField(Object sender, MergeImageFieldEventArgs field) {
String filePath = field.getImageFileName();
if (filePath != null && !"".equals(filePath)) {
try {
field.setImage(filePath);
field.setImageLink("https://www.baidu.com/");
} catch (Exception e) {
e.printStackTrace();
}
}
|
| New feature | SPIREDOC-9369 | Adds the getFieldOptions() method to support setting field properties when updating a field.
document.getFieldOptions().setCultureSource(FieldCultureSource.CurrentThread); |
| New feature | - | Adds the hasDigitalSignature() method to support determining whether a document has a digital signature.
Document.hasDigitalSignature("filepath");
|
| New feature | SPIREDOC-9455 | Adds the integrateFontTableTo method to support copying Fonttable data from source document to target document.
sourceDoc.integrateFontTableTo(Document destDoc); |
| New feature | SPIREDOC-9869 | Adds the HtmlUrlLoadEvent event to support the control of loading URLs in the file when loading HTML files.
public static void main(String[] args) {
Document document = new Document();
document.HtmlUrlLoadEvent = new MyDownloadEvent();
document.loadFromFile(inputFile, FileFormat.Html, XHTMLValidationType.None);
document.saveToFile(outputFile, FileFormat.PDF);
}
static class MyDownloadEvent extends HtmlUrlLoadHandler {
@Override
public void invoke(Object o, HtmlUrlLoadEventArgs htmlUrlLoadEventArgs) {
try {
byte[] bytes = downloadBytesFromURL(htmlUrlLoadEventArgs.getUrl());
htmlUrlLoadEventArgs.setDataBytes(bytes);
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static byte[] downloadBytesFromURL(String urlString) throws Exception {
URL url = new URL(urlString);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(5000);
connection.setReadTimeout(5000);
int responseCode = connection.getResponseCode();
if (responseCode == HttpURLConnection.HTTP_OK) {
InputStream inputStream = connection.getInputStream();
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int bytesRead;
while ((bytesRead = inputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, bytesRead);
}
outputStream.close();
return outputStream.toByteArray();
} else {
throw new Exception("Failed to download content. Response code: " + responseCode);
}
}
|
| New feature | - | Adds the setCustomFonts(InputStream[] fontStreamList) method to support setting custom fonts by stream.
document.setCustomFonts(InputStream[] fontStreamList); |
| New feature | - | Replaces the clearCustomFontsFolders() method with the new clearCustomFonts() method.
document.clearCustomFonts(); |
| New feature | - | Replaces the setGlobalCustomFontsFolders(InputStream[] fontStreamList) method with the new setGlobalCustomFonts(InputStream[] fontStreamList) method.
Document.setGlobalCustomFonts(InputStream[] fontStreamList); |
| New feature | - | Replaces the clearGlobalCustomFontsFolders() method with the new clearGlobalCustomFonts() method.
Document.clearGlobalCustomFonts(); |
Version: 12.2.2
| Category | ID | Description |
| Bug | SPIREDOC-9689 | Fixes the issue that extra red vertical lines appeared after converting a Word document to a PDF document. |
| Bug | SPIREDOC-9911 | Fixes the issue that text loss occurred after converting an RTF document to a PDF document. |
| Bug | SPIREDOC-10009 | Fixes the issue that the program threw java.lang.NullPointerException when converting the same Word document to PDF document more than once under multi-threading. |
| Bug | SPIREDOC-10018 | Fixes the issue that the content was incorrect after converting a Word document to a PDF document. |
| Bug | SPIREDOC-10031 | Fixes the issue that the size of the PDF file was inconsistent when converting the same Word document to PDF document multiple times under multi-threading. |
| Bug | SPIREDOC-10130 | Fixes the issue that the numbers in the header were displayed incorrectly after converting a Word document to a PDF document. |
| Bug | SPIREDOC-10216 | Fixes the issue that the content of the updated table of contents was incorrect. |
| Bug | SPIREDOC-10236 | Fixes the issue that the program threw java.lang.NullPointerException when converting Word documents to PDF documents. |
| Bug | SPIREDOC-10238 | Fixes the issue that the text was garbled after converting a Doc document to a Docx document. |
| Bug | SPIREDOC-10258 | Fixes the issue that the program threw multiple exceptions when loading multiple files in a folder under multi-threading. |
| Bug | SPIREDOC-10274 | Fixes the issue that extra slashes appeared after converting a Word document to a PDF document. |
| Bug | SPIREDOC-10276 | Fixes the issue that the content of the header was displayed repeatedly after unlinking the header to the previous section. |
Version: 12.1.16
| Category | ID | Description |
| New feature | SPIREDOC-10090 | Addes the Bookmark.getFirstColumn() method and the Bookmark.getLastColumn() method. |
| New feature | SPIREDOC-10163 | Optimizes the exception catching mechanism when loading non-existent document paths. |
| Bug | SPIREDOC-8257 | Fixed the issue that the paging was incorrect when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-8568 SPIREDOC-9172 |
Fixed the issue that the content was incorrect when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-8586 | Fixed the issue that the header moved down when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-8797 | Fixed the issue that combined graphics were drawn incorrectly when converting Docx documents to HTML documents. |
| Bug | SPIREDOC-9069 | Fixed the issue that checkbox checkmarks were missing and an extra page occurred when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-9577 | Fixed the issue that the program threw java.lang.ArrayIndexOutOfBoundsException when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-9611 | Fixed the issue that some contents were lost and the formatting was incorrect when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-9709 | Fixed the issue that the program threw "No have this value 63" error when loading Doc documents. |
| Bug | SPIREDOC-9713 | Fixed the issue that the position of pictures was wrong when converting Doc documents to PDF documents. |
| Bug | SPIREDOC-9763 | Fixed the issue that the effect of accepting revisions was incorrect. |
| Bug | SPIREDOC-9783 | Fixed the issue that images and text overlapped when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-9799 | Fixed the issue that fonts and paragraph styles were changed after replacing the contents of bookmarks. |
| Bug | SPIREDOC-10011 | Fixed the issue that header contents were displayed incorrectly after converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10015 | Fixed the issue that table styles were incorrect when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10040 | Fix the issue that the program threw an "Argument path cannot be empty" error when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10054 | Fixed the issue that images are displayed incorrectly when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10074 | Fixed the issue that tables were lost and table height was increased when converting Doc documents to PDF documents. |
| Bug | SPIREDOC-10143 | Fixed the issue that the program threw "java.lang.IllegalStateException: Wrong Word version" error when loading Docx documents encrypted with WPS. |
| Bug | SPIREDOC-10148 | Fixed the issue that directory jumps were incorrect when converting Docx documents to PDF documents. |
| Bug | SPIREDOC-10157 | Fixed an issue that the markup adding to a document using the BuiltinDocumentProperties.setKeyWord() method failed. |
| Bug | SPIREDOC-10179 | Fixed the issue that page number formatting changed after converting a Docx document to a PDF document. |
| Request free customized demo just for you. |
Tab 1
Upload
Maximum file size: 1 MB. Files accepted: doc, docx, txt, rtf.
 Click here to browse files.
Click here to browse files.fileerrors
Convert to
Source file:
filename
Target file type:
Tab 2
Upload
Maximum file size: 1 MB. Files accepted: doc, docx, txt, rtf.
Click here to browse files.
fileerrors
Convert to
Source file:
filename
Search Text:
Tab 3
Word Document
Maximum file size: 1 MB. Files accepted: doc, docx, txt, rtf.
Click here to browse files.fileerrors
Page Size
Source file:
filename
Target file type:
Page Header
| Header Text: | Header Image: |
Click here to browse files
|
||
| Header Font: | Font Size: | |||
| Color: | Alignment : |
Page Footer
| Footer Text: | Footer Image: |
Click here to browse files
|
||
| Footer Font: | Font Size: | |||
| Color: | Alignment: |
Tab 4
Data
e-iceblue
Option
downloads
Tab 5
| Agreement Start Date: | |
| Agreement End Date: | |
| Agreement Extension Date: | |
| Documentation Start Date: | |
| Documentation End Date: | |
|
downloads
|
|
Tab 6
Upload
Maximum file size: 1 MB. Files accepted: doc, docx, txt, rtf.
Click here to browse files.Source file:
filename
fileerrors
Set text watermark
| Text: | |
| Font: | |
| Font Size: | |
| Color: | |
|
downloads
|
|
Set image watermark
| Image: |
Click here to browse files
|
 |
|
|
downloads
|
|
If you don't find the function you want, please fill in a form to request a free demo from us. Make sure the demo you want meets the following requirements:
- It is a small project that implements a particular scenario.
- It relates to our libraries stored on E-iceblue online store.
- It costs less than 2 hours for us to complete it.
- It is not a bug report.
- It is not a feature request.