
Knowledgebase (2070)
Charts are an essential tool for visualizing data stored in Excel spreadsheets. Creating charts from your spreadsheet data can reveal trends, patterns, and insights that might be missed in a simple table of numbers. With Spire.Cloud.Excel, an online spreadsheet editor, you can easily convert your Excel data to various types of charts. This guide will walk you through the process of how to convert Excel data with charts online using Spire.Cloud.Excel.
- Spire.Cloud.Excel Spreadsheet Editor
- Chart Types Supported by Spire.Cloud.Excel Spreadsheet Editor
- Convert Excel Data to Charts Online
Spire.Cloud.Excel Spreadsheet Editor
Spire.Cloud.Excel is one of the key components of the Spire.Cloud.Office online suite. This robust online spreadsheet editor empowers users to create, view, edit, convert and collaborate on Excel-compatible spreadsheets directly in their web browsers. It offers a wide range of features, including data analysis tools, formula support, chart creation, and formatting options. With a variety of chart types and customization options, Spire.Cloud.Excel makes data visualization straightforward and effective.
To utilize the services offered by Spire.Cloud.Excel, you first need to install Spire.Cloud.Office on your system:
- Install Spire.Cloud.Office for .NET on Windows
- Install Spire.Cloud.Office for Linux on Ubuntu
- Install Spire.Cloud.Office for Linux on CentOS
After the installation is complete, you can integrate Spire.Cloud.Office in your own web application or visit the example application hosted on port 3000 (as shown in the image below) to explore the editor's functionality.

Chart Types Supported by Spire.Cloud.Excel Spreadsheet Editor
Spire.Cloud.Excel Spreadsheet Editor supports a wide range of chart types, allowing you to choose the best visual representation for your data. Here are some of the chart types you can use:
- Column Chart: Ideal for comparing quantities across different categories. Each category is represented by a vertical bar, making it easy to see differences at a glance. This type of chart is perfect for displaying data like sales figures or population statistics.
- Line Chart: Perfect for showing trends over time. Line charts plot data points connected by a straight line, making them great for tracking changes over periods such as months or years. They are commonly used for financial data, such as stock prices or revenue growth.
- Pie Chart: Useful for displaying proportions and percentages. A pie chart divides a circle into slices to illustrate numerical proportions. Each slice represents a category's contribution to the whole, making it easy to compare parts of a whole.
- Bar Chart: Similar to column charts but with horizontal bars. Bar charts are useful for comparing quantities across categories, especially when the category names are long or there are many categories. They are often used for survey data or inventory levels.
- Area Chart: Great for emphasizing the magnitude of change over time. Area charts are similar to line charts, but the area below the line is filled with color, highlighting the volume of change. They are ideal for showing cumulative totals over time, such as total sales or production levels.
- XY (Scatter) Chart: Used for showing the relationship between two variables. Scatter charts plot individual data points on a grid, with one variable on the x-axis and the other on the y-axis. This type of chart is excellent for identifying correlations or trends between two datasets, such as height versus weight.
- Stock Chart: Suitable for financial data, representing stock prices and market trends. Stock charts can display various financial metrics, such as opening, closing, high, and low prices for a particular period. They are essential for investors and analysts who need to track market movements and make informed decisions.
Each chart type comes with customization options to enhance your data visualization further, allowing you to adjust colors, labels, and other elements to create the most informative and visually appealing charts for your needs.
Convert Excel Data to Chart Online
To convert Excel data to charts online using Spire.Cloud.Excel, you can follow the steps below.
1. Open Your Excel File
- First, you need to upload your Excel file by clicking the "Upload File" button on the example page.

- Once the file is uploaded, click the "Edit" button to open it in the Spire.Cloud.Excel Spreadsheet Editor.
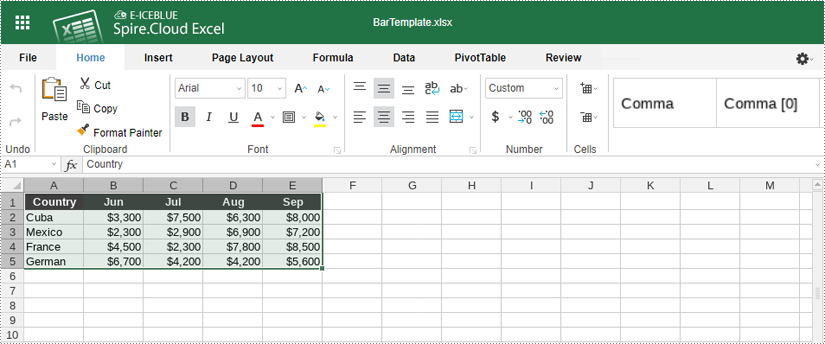
2. Select Your Data
To create a chart, you need to select the data that you want to visualize:
- Click and drag to highlight the cells containing the data you want to include in your chart.
- Ensure you include headers in your selection if you want them to appear in the chart's legend.
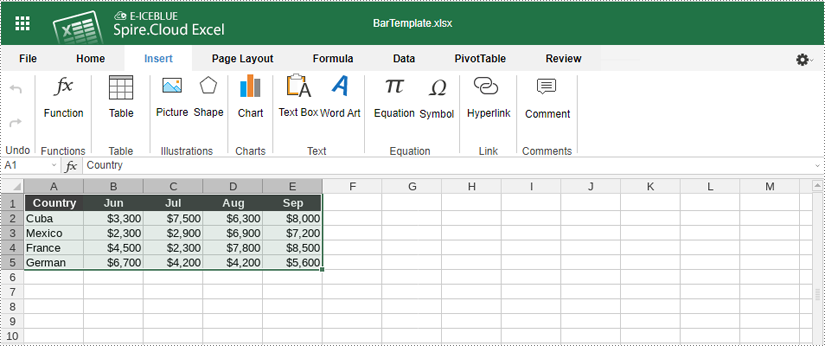
3. Insert a Chart
With your data selected, follow these steps to insert a chart:
- Go to the "Insert" tab in the toolbar of Spire.Cloud.Excel Spreadsheet Editor.
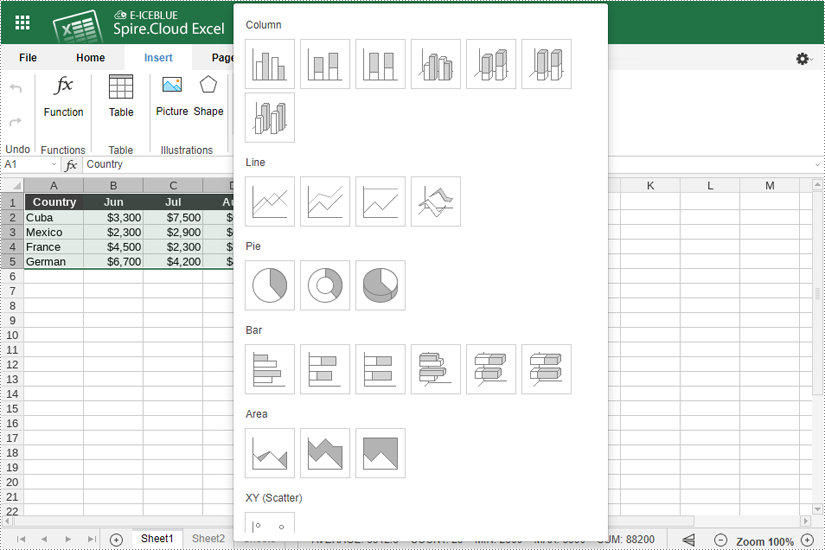
- Click the "Chart" icon. This will open a menu with various chart types. Then Choose the chart type that best represents your data (e.g., bar chart, line chart, pie chart, column chart, XY (scatter chart), area chart).
4. Customize Your Chart
Spire.Cloud.Excel provides numerous options to customize your chart:
- After inserting the chart, click the "Chart Title" to add a title for it.
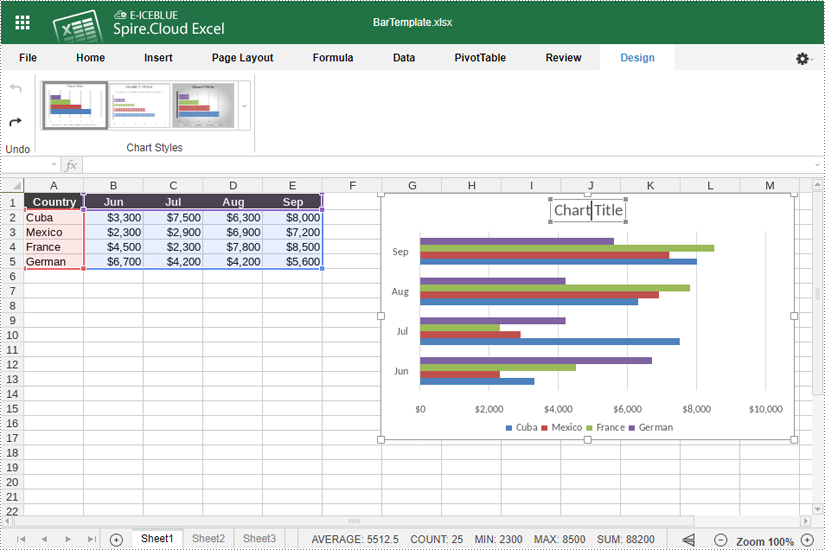
- Right-click the chart and select "Chart Advanced Settings".
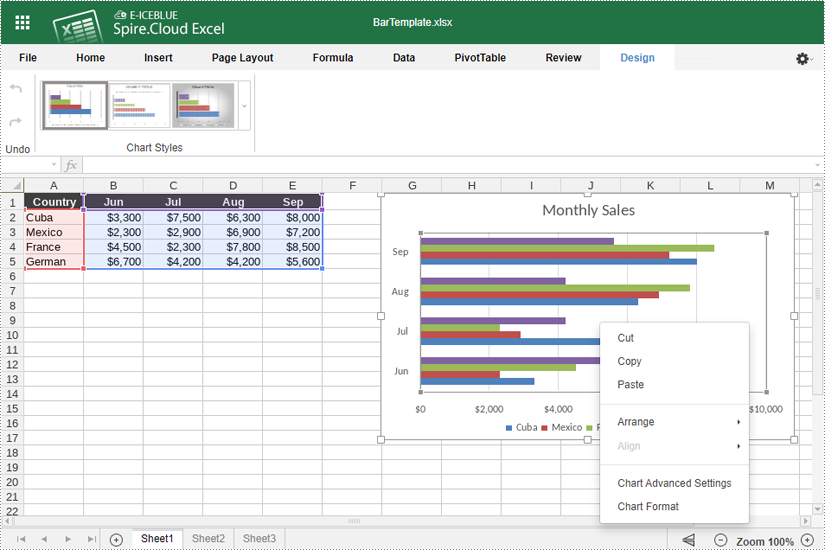
- Use the options available to modify the chart's design, such as changing the chart title and legend position, adding data labels, and adjusting horizontal and vertical axes.
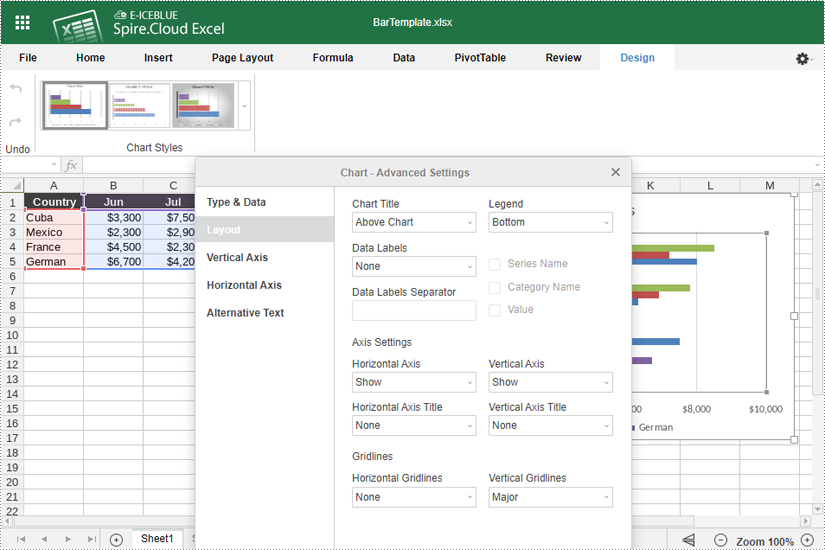
- If you want to change the chart type, right-click the chart and select "Chart Format". Then click "Chart" > "Change Chart Type".
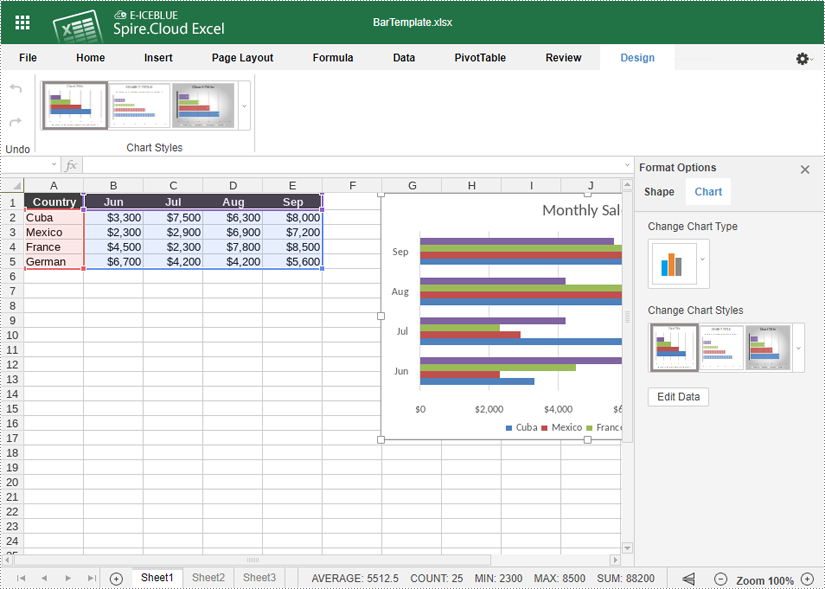
- You can also resize and move the chart within your spreadsheet by clicking and dragging.
5. Save Your Chart
- Once you are satisfied with your chart, you can save your document by pressing "Ctrl + S" or clicking on the "File" menu and selecting "Save" to save your changes.
- Your file has been saved and can be accessed on the example page.
In Microsoft Word, adding, modifying, and removing page borders are essential document formatting settings that can significantly enhance the visual appeal and professionalism of a document. Adding borders defines the boundaries of the document, enhancing its structure; by adjusting the color, width, and style of the borders, users can customize the document's style to fit specific themes or branding requirements. Removing borders helps simplify page design, reducing visual clutter, especially when the emphasis is on content rather than decoration. This article will introduce how to add, modify, or remove Word page borders in Java projects using Spire.Doc for Java.
Install Spire.Doc for Java
First, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>12.7.6</version>
</dependency>
</dependencies>
Java Add Word Page Borders
Spire.Doc offers a comprehensive set of APIs for setting Word page borders, primarily utilizing the Section.getPageSetup().getBorders() property. Here are the detailed steps:
- Create a Document object.
- Load a document using the Document.loadFromFile() method.
- Use a for loop to iterate through each section (Section) in the document.
- Set the borders to apply to all pages by calling Section.getPageSetup().setPageBordersApplyType(PageBordersApplyType.All_Pages).
- Set the page border style to double line by invoking Section.getPageSetup().getBorders().setBorderType(BorderStyle.Double).
- Define the border width as 1pt by setting Section.getPageSetup().getBorders().setLineWidth(1).
- Set the border color using Section.getPageSetup().getBorders().setColor(new Color(0, 85, 170)).
- Adjust the distance between the border and the page content to 20pt by setting properties such as Section.getPageSetup().getBorders().getTop().setSpace(20), getBottom().setSpace(20), getLeft().setSpace(20), and getRight().setSpace(20).
- Save the changes to a Word document using the Document.saveToFile() method.
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import java.awt.*;
public class AddPageBorders {
public static void main(String[] args) {
// Create a Document object
Document doc = new Document();
// Load an existing Word document
doc.loadFromFile("Sample01.docx");
// Iterate through all sections in the document
for (int i = 0; i < doc.getSections().getCount(); i++) {
// Set page borders to apply to all pages in the current section
doc.getSections().get(i).getPageSetup().setPageBordersApplyType(PageBordersApplyType.All_Pages);
// Set border style
doc.getSections().get(i).getPageSetup().getBorders().setBorderType(BorderStyle.Double);
// Set border width
doc.getSections().get(i).getPageSetup().getBorders().setLineWidth(1);
// Set border color
doc.getSections().get(i).getPageSetup().getBorders().setColor(new Color(0, 85, 170));
// Set distance from top border to page content
doc.getSections().get(i).getPageSetup().getBorders().getTop().setSpace(20);
// Set distance from bottom border to page content
doc.getSections().get(i).getPageSetup().getBorders().getBottom().setSpace(20);
// Set distance from left border to page content
doc.getSections().get(i).getPageSetup().getBorders().getLeft().setSpace(20);
// Set distance from right border to page content
doc.getSections().get(i).getPageSetup().getBorders().getRight().setSpace(20);
}
// Save the modified document to a new file
doc.saveToFile("AddWordPageBorders.docx", FileFormat.Docx);
// Release resources used by the Document object
doc.dispose();
}
}

Java Modify Word Page Borders
Spire.Doc library offers rich options for customizing page borders in Word documents, allowing developers deep control over the visual presentation of borders. This includes, but is not limited to, border styles, color selection, line thickness, and even more detailed aesthetic adjustments. Below are the detailed steps:
- Create a Document object.
- Load a document using the Document.loadFromFile() method.
- Retrieve the first section of the document with Document.getSections().get(0).
- Change the style of the page border using Section.getPageSetup().getBorders().setBorderType(BorderStyle.Triple).
- Change the color of the page border using Section.getPageSetup().getBorders().setColor(new Color(205, 133, 63)).
- Adjust the width of the page border using Section.getPageSetup().getBorders().setLineWidth(2).
- Save to a Word document using the Document.saveToFile() method.
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import java.awt.*;
public class ModifyPageBorders {
public static void main(String[] args) {
// Create a Document object
Document doc = new Document();
// Load an existing Word document
doc.loadFromFile("Sample02.docx");
// Get the first section
Section section = doc.getSections().get(0);
// Set border style
section.getPageSetup().getBorders().setBorderType(BorderStyle.Triple);
// Set border color
section.getPageSetup().getBorders().setColor(new Color(205, 133, 63));
// Set border width
section.getPageSetup().getBorders().setLineWidth(2);
// Save the modified document to a new file
doc.saveToFile("ModifyWordPageBorders.docx", FileFormat.Docx);
// Release the resources occupied by the Document object
doc.dispose();
}
}

Java Remove Word Page Borders
Removing page borders in a Word document can be easily accomplished using Section.getPageSetup().getBorders().setBorderType(BorderStyle.None). Here are the detailed steps:
- Create a Document object.
- Load a document using the Document.loadFromFile() method.
- Use a for loop to iterate through each section (Section) in the document.
- Remove page borders by applying Section.getPageSetup().getBorders().setBorderType(BorderStyle.None).
- Save the changes to the document using the Document.saveToFile() method.
- Java
import com.spire.doc.*;
import com.spire.doc.documents.*;
import java.io.ByteArrayInputStream;
public class RemovePageBorders {
public static void main(String[] args) {
// Create a Document object
Document doc = new Document();
// Load an existing Word document
doc.loadFromFile("Sample02.docx");
// Iterate through all sections in the document
for (int i = 0; i < doc.getSections().getCount(); i++) {
// Remove page borders
doc.getSections().get(i).getPageSetup().getBorders().setBorderType(BorderStyle.None);
}
// Save the modified document to a new file
doc.saveToFile("RemoveWordPageBorders.docx", FileFormat.Docx);
// Release resources used by the Document object
doc.dispose();
}
}

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Adjusting the column widths in a Word table is crucial for making the document look neat and easy to read. Particularly in tables with a lot of text, appropriate column widths can facilitate smoother reading. Word offers two approaches: percentage-based and fixed widths. Setting column widths by percentage can adapt to various screen sizes, keeping content neatly formatted and more pleasant to read. Using fixed widths stabilizes the table structure, precisely aligning each section, which is especially suitable for tables requiring strict alignment of numbers or complex designs. This article will introduce how to set Word table column widths based on percentage or fixed values using Spire.Doc for Java in Java projects.
Install Spire.Doc for Java
First, you're required to add the Spire.Doc.jar file as a dependency in your Java program. The JAR file can be downloaded from this link. If you use Maven, you can easily import the JAR file in your application by adding the following code to your project's pom.xml file.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>https://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>e-iceblue</groupId>
<artifactId>spire.doc</artifactId>
<version>12.7.6</version>
</dependency>
</dependencies>
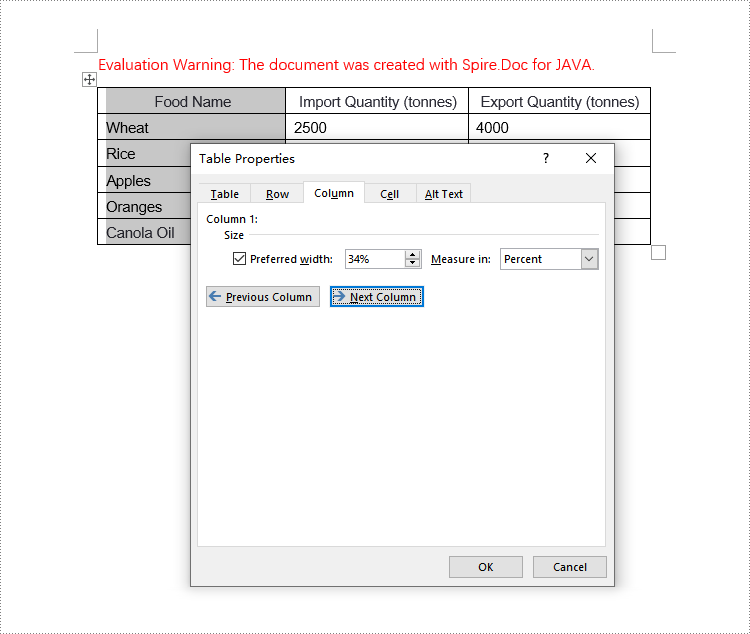
Set Column Width Based on Percentage in Java
To set column widths in a Word table using percentage values, you first need to define the table's width type as percentage. This can be achieved with Table.SetPreferredWidth(new PreferredWidth(WidthType.Percentage, (short)100)). Then, iterate through each column and set their widths to either the same or different percentage values. Here are the detailed steps:
- Create a Document object.
- Load a document using the Document.loadFromFile() method.
- Retrieve the first section of the document using Document.getSections().get(0).
- Get the first table within the section using Section.getTables().get(0).
- Use a for loop to iterate through all rows in the table.
- Set the column width for cells in different columns to percentage values using the TableRow.getCells().get(index).setCellWidth(value, CellWidthType.Percentage) method, where value is the percentage width you wish to apply.
- Save the changes to the Word document using the Document.saveToFile() method.
- Java
import com.spire.doc.*;
public class PercentageColumnWidth {
public static void main(String[] args) {
// Create a new Document object
Document doc = new Document();
// Load the document
doc.loadFromFile("Sample.docx");
// Get the first Section of the document
Section section = doc.getSections().get(0);
// Cast the first Table in the Section to a Table type
Table table = section.getTables().get(0);
// Create a PreferredWidth object, set the width type to Percentage, and set the width value to 100%
PreferredWidth percentageWidth = new PreferredWidth(WidthType.Percentage, (short) 100);
// Set the Table's preferred width to the PreferredWidth object created above
table.setPreferredWidth(percentageWidth);
// Define a variable of type TableRow
TableRow tableRow;
// Iterate over all rows in the Table
for (int i = 0; i < table.getRows().getCount(); i++) {
// Get the current row
tableRow = table.getRows().get(i);
// Set the width of the first cell to 34%, type as Percentage
tableRow.getCells().get(0).setCellWidth(34, CellWidthType.Percentage);
// Set the width of the second cell to 33%, type as Percentage
tableRow.getCells().get(1).setCellWidth(33, CellWidthType.Percentage);
// Set the width of the third cell to 33%, type as Percentage
tableRow.getCells().get(2).setCellWidth(33, CellWidthType.Percentage);
}
// Save the modified document, specifying the file format as Docx2016
doc.saveToFile("SetColumnWidthsWithPercentageValues.docx", FileFormat.Docx_2016);
// Close the document
doc.close();
}
}
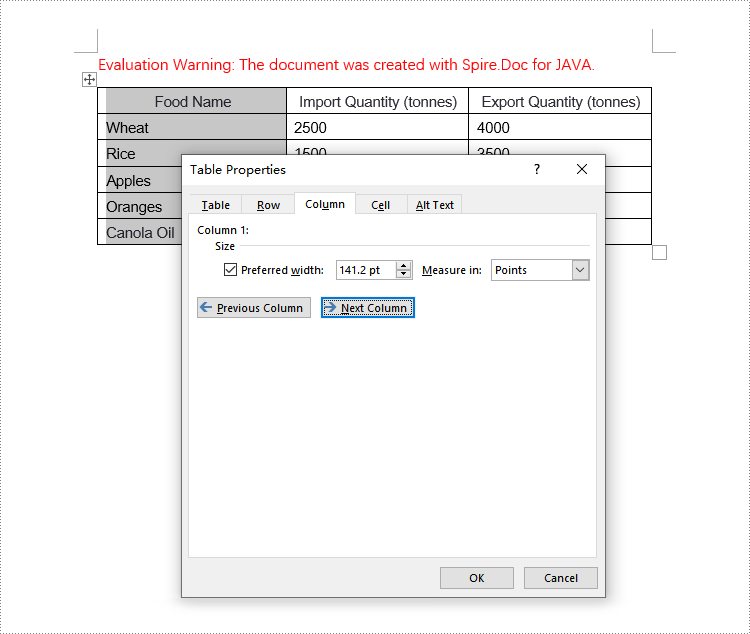
Set Column Width Based on Fixed Value in Java
When setting column widths in a Word table using fixed values, you first need to set the table to a fixed layout. This is done with Table.getTableFormat().setLayoutType(LayoutType.Fixed), then iterate through each column and set the width to the same or different fixed values as required. Here are the detailed steps:
- Create a Document object.
- Load a document using the Document.loadFromFile() method.
- Retrieve the first section of the document using Document.getSections().get(0).
- Get the first table within the section using Section.getTables().get(0).
- Use a for loop to iterate through all rows in the table.
- Set the column width for cells in different columns to fixed values using the TableRow.getCells().get(index).setCellWidth(value, CellWidthType.Point) method.
- Save the changes to the Word document using the Document.saveToFile() method.
- Java
import com.spire.doc.*;
public class FixedColumnWidth {
public static void main(String[] args) {
// Create a new Document object
Document doc = new Document();
// Load the document
doc.loadFromFile("Sample.docx");
// Get the first Section of the document
Section section = doc.getSections().get(0);
// Cast the first Table in the Section to a Table type
Table table = section.getTables().get(0);
// Set the table layout type to Fixed
table.getTableFormat().setLayoutType(LayoutType.Fixed);
// Set the table resizing method to not Auto
table.getTableFormat().isAutoResized(false);
// Get the left margin
float leftMargin = section.getPageSetup().getMargins().getLeft();
// Get the right margin
float rightMargin = section.getPageSetup().getMargins().getRight();
// Calculate the page width minus left and right margins
double pageWidth = section.getPageSetup().getPageSize().getWidth() - leftMargin - rightMargin;
// Define a variable of type TableRow
TableRow tableRow;
// Iterate through all rows in the Table
for (int i = 0; i < table.getRows().getCount(); i++) {
// Get the current row
tableRow = table.getRows().get(i);
// Set the first column cell width to 34% of the page width
tableRow.getCells().get(0).setCellWidth((float) (pageWidth * 0.34), CellWidthType.Point);
// Set the second column cell width to 33% of the page width
tableRow.getCells().get(1).setCellWidth((float) (pageWidth * 0.33), CellWidthType.Point);
// Set the third column cell width to 33% of the page width
tableRow.getCells().get(2).setCellWidth((float) (pageWidth * 0.33), CellWidthType.Point);
}
// Save the modified document, specifying the file format as Docx2016
doc.saveToFile("SetColumnWidthsWithFixedValues.docx", FileFormat.Docx_2016);
// Close the document
doc.close();
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
