Get Paragraphs by Style Name in Word in C#, VB.NET
By using Spire.Doc, you can not only retrieve the style names of all paragraphs in a Word document, but also get the paragraphs with a specific style name. This is useful especially when you need to get the text in Title, Heading 1, Subtitle, etc.
| Paragraph Style Names in Word | Paragraph Style Names in Spire.Doc |
| Title | Title |
| Heading 1 | Heading1 |
| Heading 2 | Heading2 |
| Heading 3 | Heading3 |
| Heading 4 | Heading3 |
| Subtitle | Subtitle |
Step 1: Load a sample Word file when initializing the Document object.
Document doc = new Document("sample.docx");
Step 2: Traverse the sections and paragraphs in the document and determine if the paragraph style name is "Heading1", if so, write the paragraph text on screen.
foreach (Section section in doc.Sections)
{
foreach (Paragraph paragraph in section.Paragraphs)
{
if (paragraph.StyleName == "Heading1")
{
Console.WriteLine(paragraph.Text);
}
}
}
Output:
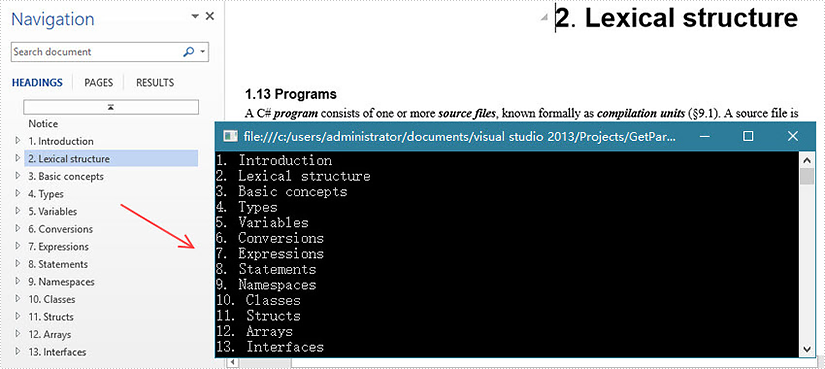
Full Code:
using Spire.Doc;
using Spire.Doc.Documents;
using System;
namespace GetParagh
{
class Program
{
static void Main(string[] args)
{
Document doc = new Document("sample.docx");
foreach (Section section in doc.Sections)
{
foreach (Paragraph paragraph in section.Paragraphs)
{
if (paragraph.StyleName == "Heading1")
{
Console.WriteLine(paragraph.Text);
}
}
}
}
}
}
Imports Spire.Doc
Imports Spire.Doc.Documents
Namespace GetParagh
Class Program
Private Shared Sub Main(args As String())
Dim doc As New Document("sample.docx")
For Each section As Section In doc.Sections
For Each paragraph As Paragraph In section.Paragraphs
If paragraph.StyleName = "Heading1" Then
Console.WriteLine(paragraph.Text)
End If
Next
Next
End Sub
End Class
End Namespace
Replace Bookmark with a Table in Word Documents in C#, VB.NET
Bookmarks are a great way to specify important locations on a Word document. Spire.Doc supports to access the bookmarks within the document and insert objects such as text, image and table at the bookmark location. This article will show you how to access a specific bookmark and replace the current bookmark content with a table.
Step 1: Load a template Word document.
Document doc = new Document(); doc.LoadFromFile(@"C:\Users\Administrator\Desktop\employee.docx");
Step 2: Create a Table object.
Table table = new Table(doc,true);
Step 3: Fill the table with sample data.
DataTable dt = new DataTable();
dt.Columns.Add("id", typeof(string));
dt.Columns.Add("name", typeof(string));
dt.Columns.Add("job", typeof(string));
dt.Columns.Add("email", typeof(string));
dt.Columns.Add("salary", typeof(string));
dt.Rows.Add(new string[] { "Emp_ID", "Name", "Job", "E-mail", "Salary" });
dt.Rows.Add(new string[] { "0241","Andrews", "Engineer", "[email protected]" ,"3.8K"});
dt.Rows.Add(new string[] { "0242","White", "Manager", "[email protected]","4.2K" });
dt.Rows.Add(new string[] { "0243","Martin", "Secretary", "[email protected]", "3.5K" });
table.ResetCells(dt.Rows.Count, dt.Columns.Count);
for (int i = 0; i < dt.Rows.Count; i++)
{
for (int j = 0; j < dt.Columns.Count; j++)
{
table.Rows[i].Cells[j].AddParagraph().AppendText(dt.Rows[i][j].ToString());
}
}
Step 4: Get the specific bookmark by its name.
BookmarksNavigator navigator = new BookmarksNavigator(doc);
navigator.MoveToBookmark("bookmark_employee");
Step 5: Create a TextBodyPart instance and add the table to it.
TextBodyPart part = new TextBodyPart(doc); part.BodyItems.Add(table);
Step 6: Replace the current bookmark content with the TextBodyPart object.
navigator.ReplaceBookmarkContent(part);
Step 7: Save the file.
doc.SaveToFile("output.docx", FileFormat.Docx2013);
Result:
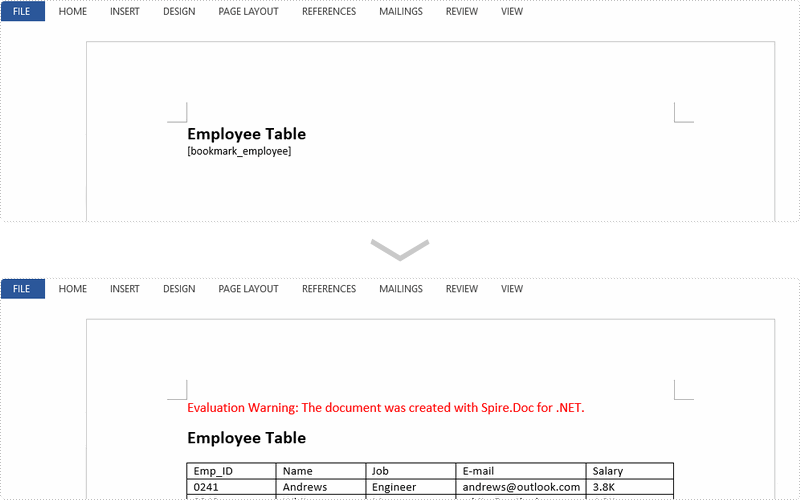
Full Code:
using Spire.Doc;
using Spire.Doc.Documents;
using System.Data;
namespace ReplaceBookmark
{
class Program
{
static void Main(string[] args)
{
Document doc = new Document();
doc.LoadFromFile(@"C:\Users\Administrator\Desktop\employee.docx");
Table table = new Table(doc, true);
DataTable dt = new DataTable();
dt.Columns.Add("id", typeof(string));
dt.Columns.Add("name", typeof(string));
dt.Columns.Add("job", typeof(string));
dt.Columns.Add("email", typeof(string));
dt.Columns.Add("salary", typeof(string));
dt.Rows.Add(new string[] { "Emp_ID", "Name", "Job", "E-mail", "Salary" });
dt.Rows.Add(new string[] { "0241", "Andrews", "Engineer", "[email protected]", "3.8K" });
dt.Rows.Add(new string[] { "0242", "White", "Manager", "[email protected]", "4.2K" });
dt.Rows.Add(new string[] { "0243", "Martin", "Secretary", "[email protected]", "3.5K" });
table.ResetCells(dt.Rows.Count, dt.Columns.Count);
for (int i = 0; i < dt.Rows.Count; i++)
{
for (int j = 0; j < dt.Columns.Count; j++)
{
table.Rows[i].Cells[j].AddParagraph().AppendText(dt.Rows[i][j].ToString());
}
}
BookmarksNavigator navigator = new BookmarksNavigator(doc);
navigator.MoveToBookmark("bookmark_employee");
TextBodyPart part = new TextBodyPart(doc);
part.BodyItems.Add(table);
navigator.ReplaceBookmarkContent(part);
doc.SaveToFile("output.docx", FileFormat.Docx2013);
System.Diagnostics.Process.Start("output.docx");
}
}
}
Imports Spire.Doc
Imports Spire.Doc.Documents
Imports System.Data
Namespace ReplaceBookmark
Class Program
Private Shared Sub Main(args As String())
Dim doc As New Document()
doc.LoadFromFile("C:\Users\Administrator\Desktop\employee.docx")
Dim table As New Table(doc, True)
Dim dt As New DataTable()
dt.Columns.Add("id", GetType(String))
dt.Columns.Add("name", GetType(String))
dt.Columns.Add("job", GetType(String))
dt.Columns.Add("email", GetType(String))
dt.Columns.Add("salary", GetType(String))
dt.Rows.Add(New String() {"Emp_ID", "Name", "Job", "E-mail", "Salary"})
dt.Rows.Add(New String() {"0241", "Andrews", "Engineer", "[email protected]", "3.8K"})
dt.Rows.Add(New String() {"0242", "White", "Manager", "[email protected]", "4.2K"})
dt.Rows.Add(New String() {"0243", "Martin", "Secretary", "[email protected]", "3.5K"})
table.ResetCells(dt.Rows.Count, dt.Columns.Count)
For i As Integer = 0 To dt.Rows.Count - 1
For j As Integer = 0 To dt.Columns.Count - 1
table.Rows(i).Cells(j).AddParagraph().AppendText(dt.Rows(i)(j).ToString())
Next
Next
Dim navigator As New BookmarksNavigator(doc)
navigator.MoveToBookmark("bookmark_employee")
Dim part As New TextBodyPart(doc)
part.BodyItems.Add(table)
navigator.ReplaceBookmarkContent(part)
doc.SaveToFile("output.docx", FileFormat.Docx2013)
System.Diagnostics.Process.Start("output.docx")
End Sub
End Class
End Namespace
Detect if a PDF file is PDF/A in C#
Spire.PDF provides developers two methods to detect if a PDF file is PDF/A. The one is to use PdfDocument.Conformance property, the other is to use PdfDocument.XmpMetaData property. The following examples demonstrate how we can detect if a PDF file is PDF/A using these two methods.
Below is the screenshot of the sample file we used for demonstration:
Using PdfDocument.Conformance
using Spire.Pdf;
using System;
namespace Detect
{
class Program
{
static void Main(string[] args)
{
//Initialize a PdfDocument object
PdfDocument pdf = new PdfDocument();
//Load the PDF file
pdf.LoadFromFile("Example.pdf");
//Get the conformance level of the PDF file
PdfConformanceLevel conformance = pdf.Conformance;
Console.WriteLine("This PDF file is " + conformance.ToString());
}
}
}
Output:
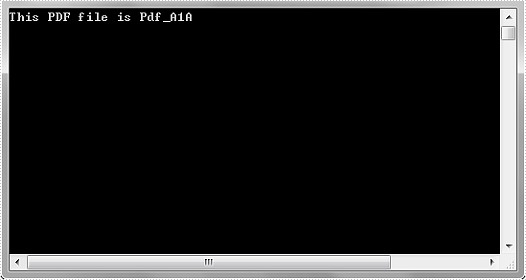
Create a Cross-Reference to Bookmark in Word in C#, VB.NET
A cross-reference refers to related information elsewhere in the same document. You can create cross-references to any existing items such as headings, footnotes, bookmarks, captions, and numbered paragraphs. This article will show you how to create a cross-reference to bookmark using Spire.Doc with C# and VB.NET.
Step 1: Create a Document instance.
Document doc = new Document(); Section section = doc.AddSection();
Step 2: Insert a bookmark.
Paragraph paragraph = section.AddParagraph();
paragraph.AppendBookmarkStart("MyBookmark");
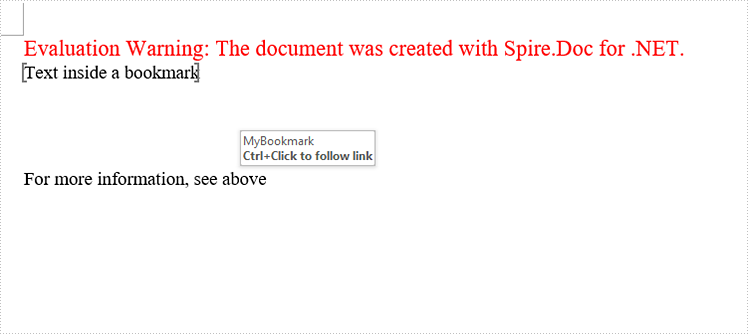
paragraph.AppendText("Text inside a bookmark");
paragraph.AppendBookmarkEnd("MyBookmark");
Step 3: Create a cross-reference field, and link it to the bookmark through bookmark name.
Field field = new Field(doc); field.Type = FieldType.FieldRef; field.Code = @"REF MyBookmark \p \h";
Step 4: Add a paragraph, and insert the field to the paragraph.
paragraph = section.AddParagraph();
paragraph.AppendText("For more information, see ");
paragraph.ChildObjects.Add(field);
Step 5: Insert a FieldSeparator object to the paragraph, which works as separator in a field.
FieldMark fieldSeparator= new FieldMark(doc, FieldMarkType.FieldSeparator); paragraph.ChildObjects.Add(fieldSeparator);
Step 6: Set the display text of the cross-reference field.
TextRange tr = new TextRange(doc); tr.Text = "above"; paragraph.ChildObjects.Add(tr);
Step 7: Insert a FieldEnd object to the paragraph, which is used to mark the end of a field.
FieldMark fieldEnd = new FieldMark(doc, FieldMarkType.FieldEnd); paragraph.ChildObjects.Add(fieldEnd);
Step 8: Save to file.
doc.SaveToFile("output.docx", FileFormat.Docx2013);
Output:
The cross-reference appears as a link that takes the reader to the referenced item.
Full Code:
using Spire.Doc;
using Spire.Doc.Documents;
using Spire.Doc.Fields;
namespace CreatCR
{
class Program
{
static void Main(string[] args)
{
Document doc = new Document();
Section section = doc.AddSection();
//create a bookmark
Paragraph paragraph = section.AddParagraph();
paragraph.AppendBookmarkStart("MyBookmark");
paragraph.AppendText("Text inside a bookmark");
paragraph.AppendBookmarkEnd("MyBookmark");
//insert line breaks
for (int i = 0; i < 4; i++)
{
paragraph.AppendBreak(BreakType.LineBreak);
}
//create a cross-reference field, and link it to bookmark
Field field = new Field(doc);
field.Type = FieldType.FieldRef;
field.Code = @"REF MyBookmark \p \h";
//insert field to paragraph
paragraph = section.AddParagraph();
paragraph.AppendText("For more information, see ");
paragraph.ChildObjects.Add(field);
//insert FieldSeparator object
FieldMark fieldSeparator = new FieldMark(doc, FieldMarkType.FieldSeparator);
paragraph.ChildObjects.Add(fieldSeparator);
//set display text of the field
TextRange tr = new TextRange(doc);
tr.Text = "above";
paragraph.ChildObjects.Add(tr);
//insert FieldEnd object to mark the end of the field
FieldMark fieldEnd = new FieldMark(doc, FieldMarkType.FieldEnd);
paragraph.ChildObjects.Add(fieldEnd);
//save file
doc.SaveToFile("output.docx", FileFormat.Docx2013);
}
}
}
Imports Spire.Doc
Imports Spire.Doc.Documents
Imports Spire.Doc.Fields
Namespace CreatCR
Class Program
Private Shared Sub Main(args As String())
Dim doc As New Document()
Dim section As Section = doc.AddSection()
'create a bookmark
Dim paragraph As Paragraph = section.AddParagraph()
paragraph.AppendBookmarkStart("MyBookmark")
paragraph.AppendText("Text inside a bookmark")
paragraph.AppendBookmarkEnd("MyBookmark")
'insert line breaks
For i As Integer = 0 To 3
paragraph.AppendBreak(BreakType.LineBreak)
Next
'create a cross-reference field, and link it to bookmark
Dim field As New Field(doc)
field.Type = FieldType.FieldRef
field.Code = "REF MyBookmark \p \h"
'insert field to paragraph
paragraph = section.AddParagraph()
paragraph.AppendText("For more information, see ")
paragraph.ChildObjects.Add(field)
'insert FieldSeparator object
Dim fieldSeparator As New FieldMark(doc, FieldMarkType.FieldSeparator)
paragraph.ChildObjects.Add(fieldSeparator)
'set display text of the field
Dim tr As New TextRange(doc)
tr.Text = "above"
paragraph.ChildObjects.Add(tr)
'insert FieldEnd object to mark the end of the field
Dim fieldEnd As New FieldMark(doc, FieldMarkType.FieldEnd)
paragraph.ChildObjects.Add(fieldEnd)
'save file
doc.SaveToFile("output.docx", FileFormat.Docx2013)
End Sub
End Class
End Namespace
Highlight Duplicate and Unique Values in Excel Using C#
Using Excel conditional formatting, we can quickly find and highlight the duplicate and unique values in a selected cell range. In this article, we’re going to show you how to programmatically highlight duplicate and unique values with different colors using Spire.XLS and conditional formatting.
Detail steps:
Step 1: Initialize an object of Workbook class and Load the Excel file.
Workbook workbook = new Workbook();
workbook.LoadFromFile("Input.xlsx");
Step 2: Get the first worksheet.
Worksheet sheet = workbook.Worksheets[0];
Step 3: Use conditional formatting to highlight duplicate values in range "A2:A10" with IndianRed color.
XlsConditionalFormats xcfs1 = sheet.ConditionalFormats.Add(); xcfs1.AddRange(sheet.Range["A2:A10"]); IConditionalFormat format1 = xcfs1.AddCondition(); format1.FormatType = ConditionalFormatType.DuplicateValues; format1.BackColor = Color.IndianRed;
Step 4: Use conditional formatting to highlight unique values in range "A2:A10" with Yellow color.
IConditionalFormat format2 = xcfs1.AddCondition(); format2.FormatType = ConditionalFormatType.UniqueValues; format2.BackColor = Color.Yellow;"
Step 5: Save the file.
workbook.SaveToFile("HighlightDuplicates.xlsx", ExcelVersion.Version2013);
Screenshot:
Full code:
using Spire.Xls;
using Spire.Xls.Core;
using Spire.Xls.Core.Spreadsheet.Collections;
using System.Drawing;
namespace HighlightDuplicateandUniqueValues
{
class Program
{
static void Main(string[] args)
{
//Load the Excel file
Workbook workbook = new Workbook();
workbook.LoadFromFile("Input.xlsx");
//Get the first worksheet
Worksheet sheet = workbook.Worksheets[0];
//Use conditional formatting to highlight duplicate values in range "A2:A10" with IndianRed color
XlsConditionalFormats xcfs1 = sheet.ConditionalFormats.Add();
xcfs1.AddRange(sheet.Range["A2:A10"]);
IConditionalFormat format1 = xcfs1.AddCondition();
format1.FormatType = ConditionalFormatType.DuplicateValues;
format1.BackColor = Color.IndianRed;
//Use conditional formatting to highlight unique values in range "A2:A10" with Yellow color
IConditionalFormat format2 = xcfs1.AddCondition();
format2.FormatType = ConditionalFormatType.UniqueValues;
format2.BackColor = Color.Yellow;
//Save the file
workbook.SaveToFile("HighlightDuplicates.xlsx", ExcelVersion.Version2013);
}
}
}
PDF Security: Encrypt or Decrypt PDF Files in C# .NET
Before diving into the full tutorial, watch this short demonstration video to learn how PDF encryption and decryption works in C#:
In today's digital landscape, PDFs carry sensitive contracts, financial reports, and personal data. A single breach can lead to compliance violations or intellectual property theft. To protect your PDFs from unauthorized access, it’s necessary to encrypt them.
Spire.PDF for .NET provides enterprise-grade PDF security solution, enabling developers to easily implement PDF encryption/decryption workflows in .NET applications. This article will provide practical examples to show you how to use C# to encrypt PDF or decrypt PDF.
- .NET Library for PDF Security
- What is Involved in PDF Encryption?
- How to Encrypt a PDF in C# (Code Example)
- How to Decrypt a PDF in C# (Steps & Code)
- FAQs
.NET Library for PDF Security
Why Use Spire.PDF?
Spire.PDF is a robust, standalone .NET library designed to create, edit, convert and secure PDF documents without Adobe Acrobat. Speaking of its security features, it enables developers to:
- Apply AES/RC4 encryption with password protection
- Restrict printing/copying/editing permissions
- Support .NET Framework, ASP.NET Core, and .NET 5+
Installation Guide
Method 1: NuGet Package Manager (Recommended)
- Open your project in Visual Studio
- Go to “Tools -> NuGet Package Manager -> Package Manager Console”
- Run the following:
PM> Install-Package Spire.PDF
Method 2: Manual Installation
- Download DLL from Spire.PDF Official Site
- Right-click your project in Solution Explorer
- Go to “Add-> Reference -> Browse -> Select Spire.PDF.dll”.
What is Involved in PDF Encryption?
Spire.PDF allows developers to encrypt PDF with passwords, set encryption algorithm, and set permissions. Below is a comprehensive technical breakdown:
User & Owner Passwords
- User Password (Open Password): Required to open and view the PDF.
- Owner Password (Permissions Password): Controls security permissions (printing, copying, editing)
Critical Security Rule: The owner password overrides user password restrictions. If a PDF file is encrypted with both passwords, it can be opened with either one. 
Example code:
PdfSecurityPolicy securityPolicy = new PdfPasswordSecurityPolicy(
"user123", // Open password
"e-iceblue" // Permission password
);
Encryption Algorithms (RC4 and AES Encrypt)
Spire.PDF supports industry-standard encryption methods with varying key strengths:
| Algorithm | Key Length | Security Level | Use Case |
|---|---|---|---|
| AES | 128/256-bit | Military-grade | Sensitive documents (Default) |
| RC4 | 40/128-bit | Legacy | Backward compatibility |
Example code:
securityPolicy.EncryptionAlgorithm = PdfEncryptionAlgorithm.AES_256;
Permission Flags
Permission flags control user actions on encrypted PDF documents after opening. These flags are controlled via the properties of the PdfDocumentPrivilege class. Here are some common permission flags.
| Properties | Description |
|---|---|
| AllowContentCopying | Gets or sets the permission which allow copy contents or not. |
| AllowPrint | Gets or sets the permission which allow print or not. |
| AllowModifyContents | Gets or sets the permission which allow modify contents or not. |
| AllowFillFormFields | Gets or sets the permission which allow fill in form fields or not. |
| AllowAll | All allowed. |
| ForbidAll | All forbidden. |
Example code:
securityPolicy.DocumentPrivilege.AllowPrint = false; // Disable printing
securityPolicy.DocumentPrivilege.AllowContentCopying = false; // Disable copying
How to Encrypt a PDF in C# (Code Example)
The following C# code password protects a PDF file with AES-256 encryption and restrict permissions.
using Spire.Pdf;
namespace EncryptPDF
{
class Program
{
static void Main(string[] args)
{
// Create a PdfDocument object
PdfDocument pdf = new PdfDocument();
// Load a sample PDF file
pdf.LoadFromFile("sample.pdf");
// Specify the user and owner passwords
string userPassword = "user123";
string ownerPassword = "e-iceblue";
// Create a PdfSecurityPolicy object with the two passwords
PdfSecurityPolicy securityPolicy = new PdfPasswordSecurityPolicy(userPassword, ownerPassword);
// Set encryption algorithm
securityPolicy.EncryptionAlgorithm = PdfEncryptionAlgorithm.AES_256;
// Set document permissions (If you do not set, the default is ForbidAll)
securityPolicy.DocumentPrivilege = PdfDocumentPrivilege.AllowAll;
// Restrict printing and content copying
securityPolicy.DocumentPrivilege.AllowPrint = false;
securityPolicy.DocumentPrivilege.AllowContentCopying = false;
// Encrypt the PDF file
pdf.Encrypt(securityPolicy);
// Save the result file
pdf.SaveToFile("EncryptPDF.pdf", FileFormat.PDF);
}
}
}
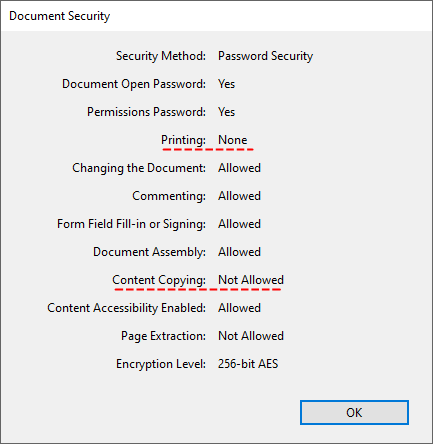
The encrypted PDF will:
- Require a password to open.

- Block printing and copying content. Retain all other permissions (editing, form filling, etc.).
How to Decrypt a PDF in C# (Steps & Code)
Decrypt PDF removes passwords and restrictions, allowing full access to the document. With Spire.PDF, you can decrypt a password-protected PDF file in C# with <5 lines of code.
Main Steps:
- Open Encrypted PDF: Load your encrypted PDF file with the owner password.
- Remove Encryption: Invoke the Decrypt() method to remove all security restrictions.
- Save Decrypted PDF: Call the SaveToFile() method to save the decrypted PDF to the specified file path.
Code Example:
The following C# code removes the PDF passwords and restores access.
using Spire.Pdf;
namespace DecryptPDF
{
class Program
{
static void Main(string[] args)
{
// Create a PdfDocument object
PdfDocument pdf = new PdfDocument();
// Load a sample PDF file with owner password
pdf.LoadFromFile("EncryptPDF.pdf", "e-iceblue");
// Decrypt the PDF file
pdf.Decrypt();
// Save the Decrypted PDF
pdf.SaveToFile("DecryptPDF.pdf");
}
}
}
Open the decrypted PDF:

Conclusion
Securing PDFs with encryption is essential for protecting sensitive data. With Spire.PDF for .NET, developers can effortlessly encrypt, decrypt, and manage permissions in PDF files using C#. The .NET PDF library’s comprehensive features and straightforward implementation make it an ideal choice for enhancing document security in enterprise applications.
Next Steps:
- Getting started with Spire.PDF and request a free 30-day trial license to fully evaluate it.
- Explore the Online Documentation for more PDF protection features such as adding digital signatures, adding watermarks, and more.
FAQs
Q1: Can I encrypt a PDF without a user password?
A: Yes. Set the user password to an empty string and use the owner password to control permissions.
Q2: What encryption standards are supported?
A: Spire.PDF supports:
- 40-bit RC4 (legacy)
- 128-bit RC4/AES (standard)
- 256-bit AES (highest security)
Recommend 256-bit AES for sensitive data compliance (e.g., HIPAA, GDPR).
Q3: How to handle incorrect passwords when decrypting?
A: Use try-catch blocks to handle exceptions:
try
{
pdf.LoadFromFile("EncryptPDF.pdf", " wrongPassword");
}
catch (Exception ex)
{
Console.WriteLine($"Error: {ex.Message}");
}
Q4. How to check if a PDF is encrypted?
A: Use the PdfDocument.IsPasswordProtected(string fileName) method. A comprehensive guide can be found at: Check Whether a PDF is Password Protected in C#
Convert PDF to SVG with Custom Width and Height in C#, VB.NET
We've have demonstrated how to convert PDF page to SVG file format in the previous post. This guidance shows you how we can specify the width and height of output file using the latest version of Spire.PDF with C# and VB.NET.
Step 1: Load a sample PDF document to PdfDocument instance.
PdfDocument document = new PdfDocument();
document.LoadFromFile("pdf-sample.pdf");
Step 2: Specify the output file size through ConvertOptions.SetPdfToSvgOptions() method.
PdfToSvgConverter converter = new PdfToSvgConverter(inputFile);
converter.SvgOptions.ScaleX = (float)0.5;
converter.SvgOptions.ScaleY = (float)0.5;
converter.Convert(outputFile);
Step 3: Save PDF to SVG file format.
document.SaveToFile("result.svg", FileFormat.SVG);
Output:
Full Code:
using Spire.Pdf;
using Spire.Pdf.Conversion;
namespace ConvertPDFtoSVG
{
class Program
{
static void Main(string[] args)
{
PdfDocument document = new PdfDocument();
PdfToSvgConverter converter = new PdfToSvgConverter(inputFile);
converter.SvgOptions.ScaleX = (float)0.5;
converter.SvgOptions.ScaleY = (float)0.5;
converter.Convert(outputFile);
}
}
}
Imports Spire.Pdf
Imports Spire.Pdf.Conversion
Namespace ConvertPDFtoSVG
Class Program
Private Shared Sub Main(args As String())
Dim document As New PdfDocument()
document.LoadFromFile("pdf-sample.pdf")
' Specify the width And height of output SVG file
Dim Converter As New PdfToSvgConverter(inputFile)
Converter.SvgOptions.ScaleX = CSng(0.5)
Converter.SvgOptions.ScaleY = CSng(0.5)
Converter.Convert(outputFile)
document.SaveToFile("result.svg", FileFormat.SVG)
End Sub
End Class
End Namespace
How to toggle the visibility of PDF layer in C#
We have already demonstrated how to use Spire.PDF to add multiple layers to PDF file and delete layer in PDF in C#. We can also toggle the visibility of a PDF layer while creating a new page layer with the help of Spire.PDF. In this section, we're going to demonstrate how to toggle the visibility of layers in new PDF document in C#.
Step 1: Create a new PDF document and add a new page to the PDF document.
PdfDocument pdf = new PdfDocument(); PdfPageBase page = pdf.Pages.Add();
Step 2: Add a layer named "Blue line" to the PDF page and set the layer invisible.
PdfLayer layer = pdf.Layers.AddLayer(""Green line"", PdfVisibility.Off);
PdfPen pen = new PdfPen(Color.Green, 1f);
PdfCanvas pcA = layer.CreateGraphics(page.Canvas);
pcA.DrawLine(pen, new PointF(0, 30), new PointF(300, 30));
Step 3: Add a layer named "Ellipse" to the PDF page and set the layer visible.
layer = pdf.Layers.AddLayer(""Ellipse"", PdfVisibility.On);
PdfPen pen2 = new PdfPen(Color.Green, 1f);
PdfBrush brush2 = new PdfSolidBrush(Color.Green);
PdfCanvas pcB = layer.CreateGraphics(page.Canvas);
pcB.DrawEllipse(pen2, brush2, 50, 70, 200, 60);
Step 4: Save the document to file.
pdf.SaveToFile("LayerVisibility.pdf", FileFormat.PDF);
Effective screenshot after toggle the visibility of PDF layer:
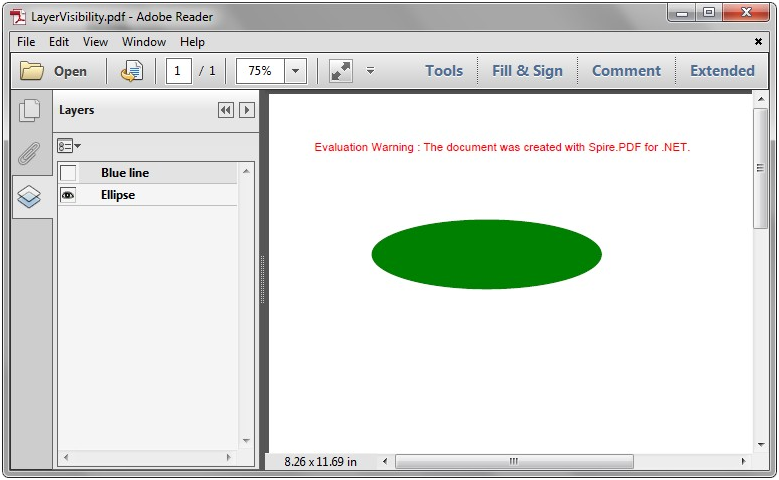
Full codes:
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
namespace LayerVisibility
{
class Program
{
static void Main(string[] args)
{
PdfDocument pdf = new PdfDocument();
PdfPageBase page = pdf.Pages.Add();
PdfLayer layer = pdf.Layers.AddLayer("Green line", PdfVisibility.Off);
PdfPen pen = new PdfPen(Color.Green, 1f);
PdfCanvas pcA = layer.CreateGraphics(page.Canvas);
pcA.DrawLine(pen,new PointF(0, 30), new PointF(300, 30));
layer = pdf.Layers.AddLayer("Ellipse", PdfVisibility.On);
PdfPen pen2 = new PdfPen(Color.Green, 1f);
PdfBrush brush2 = new PdfSolidBrush(Color.Green);
PdfCanvas pcB = layer.CreateGraphics(page.Canvas);
pcB.DrawEllipse(pen2, brush2, 50, 70, 200, 60);
pdf.SaveToFile("LayerVisibility.pdf", FileFormat.PDF);
}
}
}
Remove conditional format from Excel in C#
With the help of Spire.XLS, we can set the conditional format the Excel cell in C# and VB.NET. We can also use Spire.XLS to remove the conditional format from a specific cell or the entire Excel worksheet. This article will demonstrate how to remove conditional format from Excel in C#.
Firstly, view the original Excel worksheet with conditional formats:
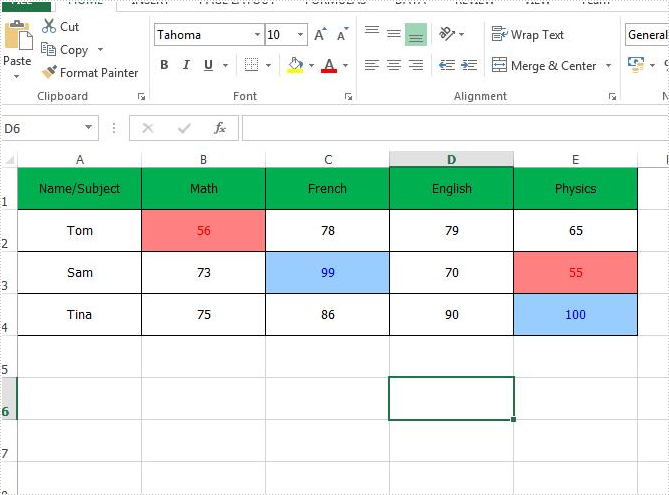
Step 1: Create an instance of Excel workbook and load the document from file.
Workbook workbook = new Workbook();
workbook.LoadFromFile("Sample.xlsx");
Step 2: Get the first worksheet from the workbook.
Worksheet sheet = workbook.Worksheets[0];
Step 3: Remove the first conditional format.
sheet.ConditionalFormats.RemoveAt(0);
Step 4: Remove all the conditional formats from the whole Excel worksheet.
for (int i = sheet.ConditionalFormats.Count-1; i >= 0; i--)
{
sheet.ConditionalFormats.RemoveAt(i);
}
Step 5: Save the document to file.
workbook.SaveToFile("Result.xlsx", ExcelVersion.Version2010);
Remove the conditional format from a special Excel range B2:
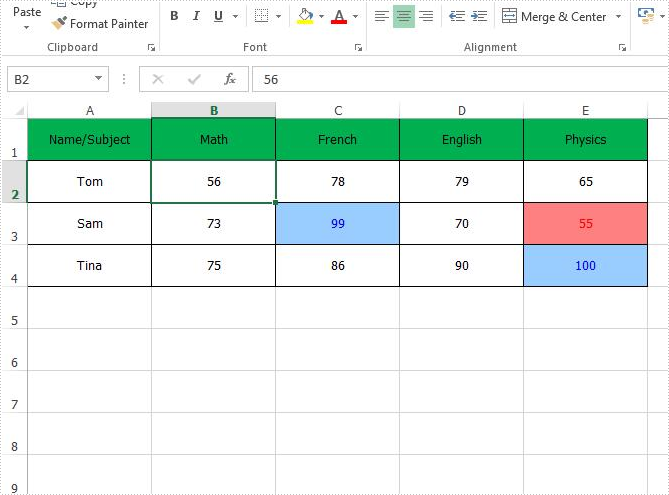
Remove all the conditional formats from the entire Excel worksheet:
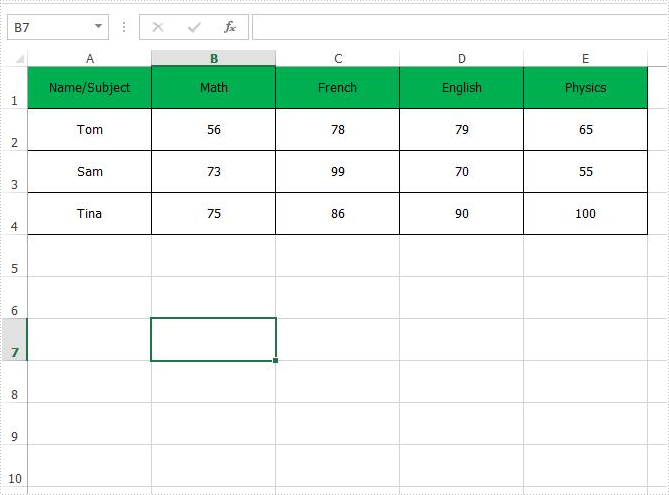
Full codes of how to remove the conditional formats from Excel worksheet:
using Spire.Xls;
namespace RemoveConditionalFormat
{
class Program
{
static void Main(string[] args)
{
Workbook workbook = new Workbook();
workbook.LoadFromFile("Sample.xlsx");
Worksheet sheet = workbook.Worksheets[0];
// Remove the first conditional format
//sheet.ConditionalFormats.RemoveAt(0);
// Remove all conditional formats
for (int i = sheet.ConditionalFormats.Count-1; i >= 0; i--)
{
sheet.ConditionalFormats.RemoveAt(i);
}
workbook.SaveToFile("Result.xlsx", ExcelVersion.Version2010);
}
}
}
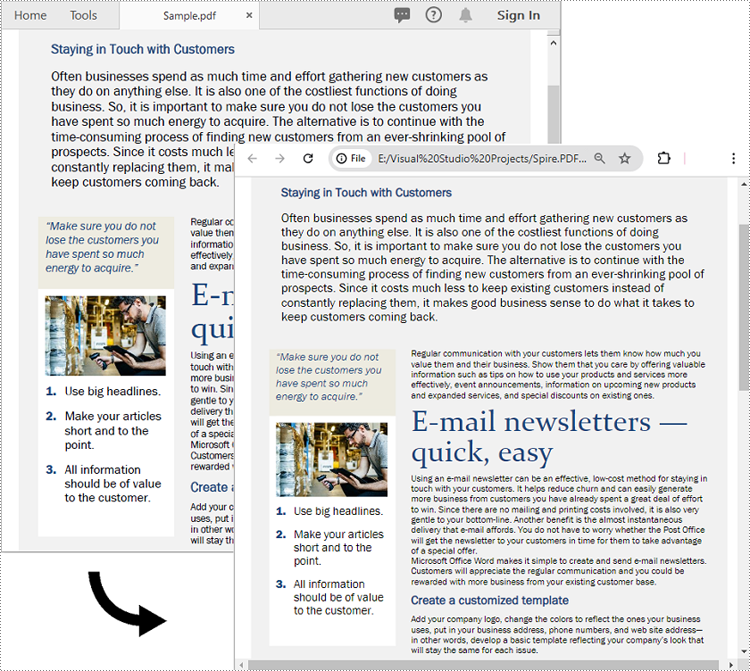
C#: Convert PDF to HTML
PDF documents have been a popular choice for sharing information due to their cross-platform compatibility and ability to preserve the original layout and formatting. However, as the web continues to evolve, there is an increasing demand for content that can be easily integrated into websites and other online platforms. In this context, converting PDF to HTML format has become highly valuable. By converting PDF files to more flexible and accessible HTML, users gain the ability to better utilize, share, and reuse PDF-based information within the web environment. In this article, we will demonstrate how to convert PDF files to HTML format in C# using Spire.PDF for .NET.
- Convert PDF to HTML in C#
- Set Conversion Options When Converting PDF to HTML in C#
- Convert PDF to HTML Stream in C#
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.PDF
Convert PDF to HTML in C#
To convert a PDF document to HTML format, you can use the PdfDocument.SaveToFile(string fileName, FileFormat.HTML) method provided by Spire.PDF for .NET. The detailed steps are as follows.
- Create an instance of the PdfDocument class.
- Load a PDF document using the PdfDocument.LoadFromFile(string fileName) method.
- Save the PDF document to HTML format using the PdfDocument.SaveToFile(string fileName, FileFormat.HTML) method.
- C#
using Spire.Pdf;
namespace ConvertPdfToHtml
{
internal class Program
{
static void Main(string[] args)
{
// Create an instance of the PdfDocument class
PdfDocument doc = new PdfDocument();
// Load a PDF document
doc.LoadFromFile("Sample.pdf");
// Save the PDF document to HTML format
doc.SaveToFile("PdfToHtml.html", FileFormat.HTML);
doc.Close();
}
}
}
Set Conversion Options When Converting PDF to HTML in C#
The PdfConvertOptions.SetPdfToHtmlOptions() method allows you to customize the conversion options when transforming PDF files to HTML. This method takes several parameters that you can use to configure the conversion process, such as:
- useEmbeddedSvg (bool): Indicates whether to embed SVG in the resulting HTML file.
- useEmbeddedImg (bool): Indicates whether to embed images in the resulting HTML file. This option is applicable only when useEmbeddedSvg is set to false.
- maxPageOneFile (int): Specifies the maximum number of pages to be included per HTML file. This option is applicable only when useEmbeddedSvg is set to false.
- useHighQualityEmbeddedSvg (bool): Indicates whether to use high-quality embedded SVG in the resulting HTML file. This option is applicable when useEmbeddedSvg is set to true.
The following steps explain how to customize the conversion options when transforming a PDF to HTML using Spire.PDF for .NET.
- Create an instance of the PdfDocument class.
- Load a PDF document using the PdfDocument.LoadFromFile(string fileName) method.
- Get the PdfConvertOptions object using the PdfDocument.ConvertOptions property.
- Set the PDF to HTML conversion options using PdfConvertOptions.SetPdfToHtmlOptions(bool useEmbeddedSvg, bool useEmbeddedImg, int maxPageOneFile, bool useHighQualityEmbeddedSvg) method.
- Save the PDF document to HTML format using PdfDocument.SaveToFile(string fileName, FileFormat.HTML) method.
- C#
using Spire.Pdf;
namespace ConvertPdfToHtmlWithCustomOptions
{
internal class Program
{
static void Main(string[] args)
{
// Create an instance of the PdfDocument class
PdfDocument doc = new PdfDocument();
// Load a PDF document
doc.LoadFromFile("Sample.pdf");
// Set the conversion options to embed images in the resulting HTML and limit one page per HTML file
PdfConvertOptions pdfToHtmlOptions = doc.ConvertOptions;
pdfToHtmlOptions.SetPdfToHtmlOptions(false, true, 1);
// Save the PDF document to HTML format
doc.SaveToFile("PdfToHtmlWithCustomOptions.html", FileFormat.HTML);
doc.Close();
}
}
}
Convert PDF to HTML Stream in C#
Instead of saving a PDF document to an HTML file, you can save it to an HTML stream by using the PdfDocument.SaveToStream(Stream stream, FileFormat.HTML) method. The detailed steps are as follows.
- Create an instance of the PdfDocument class.
- Load a PDF document using the PdfDocument.LoadFromFile(string fileName) method.
- Create an instance of the MemoryStream class.
- Save the PDF document to an HTML stream using the PdfDocument.SaveToStream(Stream stream, FileFormat.HTML) method.
- C#
using Spire.Pdf;
using System.IO;
namespace ConvertPdfToHtmlStream
{
internal class Program
{
static void Main(string[] args)
{
// Create an instance of the PdfDocument class
PdfDocument doc = new PdfDocument();
// Load a PDF document
doc.LoadFromFile("Sample.pdf");
// Save the PDF document to HTML stream
using (var fileStream = new MemoryStream())
{
doc.SaveToStream(fileStream, FileFormat.HTML);
// You can now do something with the HTML stream, such as Write it to a file
using (var outputFile = new FileStream("PdfToHtmlStream.html", FileMode.Create))
{
fileStream.Seek(0, SeekOrigin.Begin);
fileStream.CopyTo(outputFile);
}
}
doc.Close();
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.