
Splitting PDF files programmatically is a crucial step for automating document management in many C# and .NET applications. Whether you need to extract specific pages, divide PDFs by defined ranges, or organize large reports, using code to segment PDFs saves time and improves accuracy.
This comprehensive guide shows how to programmatically split or divide PDF files in C# using the Spire.PDF for .NET library, with practical methods and clear code examples to help developers easily integrate PDF splitting into their applications.
Table of Contents
- Why Split a PDF Programmatically in C#?
- What You Need to Get Started
- Installing Spire.PDF for .NET Library
- How to Split PDF Files in C# (Methods and Code Examples)
- Split PDF in VB.NET
- Conclusion
- Frequently Asked Questions (FAQs)
Why Split a PDF Programmatically in C#?
Splitting PDFs through code offers significant advantages over manual processing. It enables:
- Automated report generation
- Faster document preparation in enterprise workflows
- Easy content extraction for archiving or redistribution
- Dynamic document handling based on user or system input
It also reduces the risk of human error and ensures consistency across repetitive tasks.
What You Need to Get Started
Before diving into the code, make sure you have:
- .NET Framework or .NET Core installed
- Visual Studio or another C# IDE
- Spire.PDF for .NET library installed
- Basic familiarity with C# programming
Installing Spire.PDF for .NET Library
Spire.PDF for .NET is a professional .NET library that enables developers to create, read, edit, and manipulate PDF files without Adobe Acrobat. It supports advanced PDF operations like splitting, merging, extracting text, adding annotations, and more.
You can install Spire.PDF for .NET NuGet Package via NuGet Package Manager:
Install-Package Spire.PDF
Or through the NuGet UI in Visual Studio:
- Right-click your project > Manage NuGet Packages
- Search for Spire.PDF
- Click Install
How to Split PDF Files in C# (Methods and Code Examples)
Breaking PDF by Every Page
When you want to break a PDF into multiple single-page files, the Split method is the easiest way. By specifying the output file name pattern, you can automatically save each page of the PDF as a separate file. This method simplifies batch processing or distributing pages individually.
using Spire.Pdf;
namespace SplitPDF
{
internal class Program
{
static void Main(string[] args)
{
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("Sample.pdf");
// Split each page into separate PDF files.
// The first parameter is the output file pattern.
// {0} will be replaced by the page number starting from 1.
pdf.Split("Output/Page_{0}.pdf", 1);
pdf.Close();
}
}
}
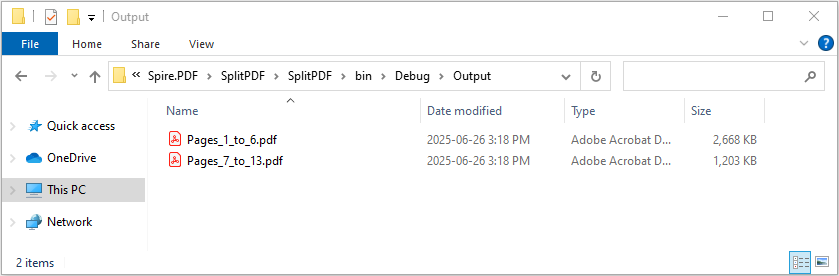
Dividing PDF by Page Ranges
To divide a PDF into multiple sections based on specific page ranges, the InsertPageRange method is ideal. This example shows how to define page ranges using zero-based start and end page indices, and then extract those ranges into separate PDF files efficiently.
using Spire.Pdf;
namespace SplitPDF
{
internal class Program
{
static void Main(string[] args)
{
// Load the PDF
PdfDocument document = new PdfDocument();
document.LoadFromFile("Sample.pdf");
// Define two ranges — pages 1–6 and 7–13 (0-based index)
int[][] ranges = new int[][]
{
new int[] { 0, 5 },
new int[] { 6, 12 }
};
// Split the PDF into smaller files by the predefined page ranges
for (int i = 0; i < ranges.Length; i++)
{
int startPage = ranges[i][0];
int endPage = ranges[i][1];
PdfDocument rangePdf = new PdfDocument();
rangePdf.InsertPageRange(document, startPage, endPage);
rangePdf.SaveToFile($"Output/Pages_{startPage + 1}_to_{endPage + 1}.pdf");
rangePdf.Close();
}
document.Close();
}
}
}
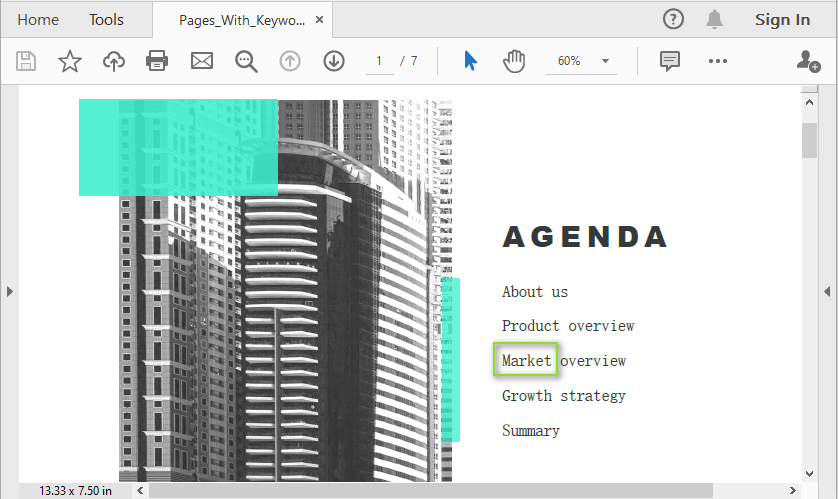
Splitting PDF by Text or Keywords
To perform content-based PDF splitting, use the Find method of the PdfTextFinder class to locate pages containing specific keywords. Once identified, you can extract these pages and insert them into new PDF files using the InsertPage method. This approach enables precise page extraction based on document content instead of fixed page numbers.
using Spire.Pdf;
using Spire.Pdf.Texts;
using System.Collections.Generic;
namespace SplitPDF
{
internal class Program
{
static void Main(string[] args)
{
// Load the PDF document
PdfDocument document = new PdfDocument();
document.LoadFromFile("Sample.pdf");
// Create a new PDF to hold extracted pages
PdfDocument resultDoc = new PdfDocument();
string keyword = "Market";
// Loop through all pages to find the keyword
for (int i = 0; i < document.Pages.Count; i++)
{
PdfPageBase page = document.Pages[i];
PdfTextFinder finder = new PdfTextFinder(page);
// Set search options
finder.Options.Parameter = TextFindParameter.WholeWord;
finder.Options.Parameter = TextFindParameter.IgnoreCase;
// Find keyword on the page
List<PdfTextFragment> fragments = finder.Find(keyword);
// If keyword found, append the page to result PDF
if (fragments.Count > 0)
{
resultDoc.InsertPage(document, page);
}
}
// Save the result PDF
resultDoc.SaveToFile("Pages_With_Keyword.pdf");
// Dispose resources
document.Dispose();
resultDoc.Dispose();
}
}
}
Extracting Specific Pages from PDF
Sometimes you only need to extract one or a few individual pages from a PDF instead of splitting the whole document. This example demonstrates how to use the InsertPage method of the PdfDocument class to extract a specific page and save it as a new PDF. This method is useful for quickly pulling out important pages for review or distribution.
using Spire.Pdf;
namespace SplitPDF
{
internal class Program
{
static void Main(string[] args)
{
// Load the PDF file
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("Sample.pdf");
// Create a new PDF to hold the extracted page
PdfDocument newPdf = new PdfDocument();
// Insert the third page (index 2, zero-based) from the PDF into the new PDF
newPdf.InsertPage(pdf, pdf.Pages[2]);
// Save the new PDF
newPdf.SaveToFile("ExtractPage.pdf");
newPdf.Close();
pdf.Close();
}
}
}
Split PDF in VB.NET
If you're working with VB.NET instead of C#, you don't need to worry about translating the code manually. You can easily convert the C# code examples in this article to VB.NET using our C# to VB.NET code converter. This tool ensures accurate syntax conversion, saving time and helping you stay focused on development.
Conclusion
Splitting PDF files programmatically in C# using Spire.PDF offers a reliable and flexible solution for automating document processing. Whether you're working with invoices, reports, or dynamic content, Spire.PDF supports various splitting methods—by page, page range, or keyword—allowing you to tailor the logic to fit any business or technical requirement.
Frequently Asked Questions (FAQs)
Q1: Is Spire.PDF free to use?
A1: Spire.PDF offers a free version suitable for small-scale or non-commercial use. For full functionality and advanced features, the commercial version is recommended.
Q2: Can I split encrypted PDFs?
A2: Yes, as long as you provide the correct password when loading the PDF files.
Q3: Does Spire.PDF support .NET Core?
A3: Yes, Spire.PDF is compatible with both .NET Framework and .NET Core.
Q4: Can I split and merge PDFs in the same project?
A4: Absolutely. Spire.PDF provides comprehensive support for both splitting and merging operations.
Get a Free License
To fully experience the capabilities of Spire.PDF for .NET without any evaluation limitations, you can request a free 30-day trial license.
