
Page Setting (8)
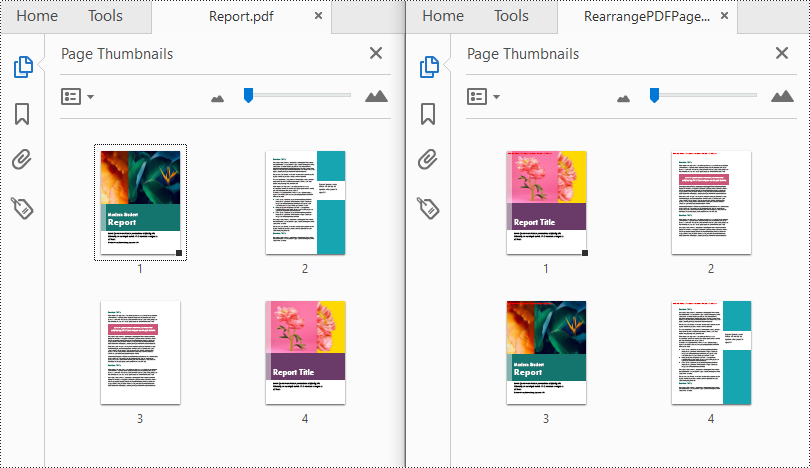
Typically, the content of a PDF document needs to follow a logical flow, such as a report is usually structured with chapters, sections, and subsections. When the pages within a PDF are not arranged in the correct sequence, the coherence of the document will be affected. By reordering the pages, you can ensure that the information is presented in a clear and understandable manner. In this article, you will learn how to reorder the pages in a PDF file with Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Reorder PDF Pages with Python
Spire.PDF for Python provides the PdfDocument.Pages.ReArrange(orderArray: List[int]) method to rearrange the pages in a PDF file. The parameter orderArray is a list of integers which allows you to reorder the PDF pages by specifying the page index in the desired order.
The following are the detailed steps to rearrange the PDF page order with Python:
- Create a PdfDocument instance.
- Load a sample PDF file using PdfDocument.LoadFromFile() method.
- Rearrange the page order of the PDF file using PdfDocument.Pages.ReArrange(orderArray: List[int]) method.
- Save the result file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import * from spire.pdf import * inputFile = "Report.pdf" outputFile = "RearrangePDFPageOrder.pdf" # Create a PdfDocument instance pdf = PdfDocument() # Load a PDF file pdf.LoadFromFile(inputFile) # Reorder pages in the PDF file pdf.Pages.ReArrange([3, 2, 0, 1]) # Save the result file pdf.SaveToFile(outputFile, FileFormat.PDF) pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Margins in a PDF document refer to the blank spaces surrounding the content on each page. They act as a buffer zone between the text or images and the edges of the page. Changing the margins of a PDF document can be a useful task when you want to adjust the layout, accommodate annotations or comments, or prepare the document for printing or presentation.
This article introduces how to modify the margins of a PDF document using the Spire.PDF for Python library. You will discover techniques to both increase and reduce the margins of your PDFs, enabling you to customize the layout according to your specific requirements.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Increase the Margins of a PDF Document in Python
In Spire.PDF for Python, there isn't a direct method to modify the margins of an existing PDF document. However, you can increase the margins by creating a new PDF document with a page size equal to the original document's page size plus the increased margin values. Then, copy and paste (draw) each page of the original document into the appropriate place on the new document page.
The following are the steps to increase the margins of a PDF document using Python.
- Create a PdfDocument object called "originalPdf" and load the original PDF document.
- Create another PdfDocument object called "newPdf" for creating a new PDF document.
- Specify the desired increase values for the top, bottom, left, and right margins.
- Calculate the new page size by adding the margin increase values to the original page dimensions.
- Create a template based on the original PDF page using PdfPageBase.CreateTemplate() method.
- Add a new page to the "newPdf" document with the calculated page size using PdfDocument.Pages.Add() method.
- Draw the template onto the new page at the appropriate location to using PdfTemplate.Draw() method.
- Repeat steps 5-7 for each page in the original PDF document.
- Save the "newPdf" object to a PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
originalPdf = PdfDocument()
# Load a PDF file
originalPdf.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf")
# Get the first page
firstPage = originalPdf.Pages[0]
# Create another PdfDocument object for creating new document
newPdf = PdfDocument()
# Set the increase values of the margins
marginsToAdd = newPdf.PageSettings.Margins
marginsToAdd.Top = 40
marginsToAdd.Bottom = 40
marginsToAdd.Left = 40
marginsToAdd.Right = 40
# Calculate the new page size
sizeF = SizeF(firstPage.Size.Width + marginsToAdd.Left + marginsToAdd.Right, firstPage.Size.Height + marginsToAdd.Top + marginsToAdd.Bottom)
# Iterate through the pages in the original document
for i in range(originalPdf.Pages.Count):
# Create a template based on a specific page
pdfTemplate = originalPdf.Pages[i].CreateTemplate()
# Add a page to the new PDF
page = newPdf.Pages.Add(sizeF)
# Draw template on the page
pdfTemplate.Draw(page, 0.0, 0.0)
# Save the new document
newPdf.SaveToFile("Output/IncreaseMargins.pdf", FileFormat.PDF)
# Dispose resources
originalPdf.Dispose()
newPdf.Dispose()

Reduce the Margins of a PDF Document in Python
Similarly, you can reduce the margins by creating a new PDF document with a page size equal to the page size of the original document minus the margin value to be reduced. Then, copy and paste (draw) each page of the original document into the appropriate place on the new document page.
To reduce the margins of a PDF document using Python, follow these steps:
- Create a PdfDocument object called "originalPdf" and load the original PDF document.
- Create another PdfDocument object called "newPdf" for creating a new PDF document.
- Specify the desired reduction values for the top, bottom, left, and right margins.
- Calculate the new page size by subtracting the margin value to be reduced from the original page size.
- Create a template based on the original PDF page using PdfPageBase.CreateTemplate() method.
- Add a new page to the "newPdf" document with the calculated page size using PdfDocument.Pages.Add() method.
- Draw the template onto the new page at the appropriate location using PdfTemplate.Draw() method.
- Repeat steps 5-7 for each page in the original PDF document.
- Save the "newPdf" object to a PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
originalPdf = PdfDocument()
# Load a PDF file
originalPdf.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Input.pdf")
# Get the first page
firstPage = originalPdf.Pages[0]
# Create another PdfDocument object
newPdf = PdfDocument()
# Set the reduction value of the margins
topToReduce = 20.0
bottomToReduce = 20.0
leftToReduce = 20.0
rightToReduce = 20.0
# Calculate the new page size
sizeF = SizeF(firstPage.Size.Width - leftToReduce - rightToReduce, firstPage.Size.Height - topToReduce - bottomToReduce)
# Iterate through the pages in the original document
for i in range(originalPdf.Pages.Count):
# Create a template based on a specific page
pdfTemplate = originalPdf.Pages[i].CreateTemplate()
# Add a page to the new PDF
page = newPdf.Pages.Add(sizeF, PdfMargins(0.0))
# Draw template on the page
pdfTemplate.Draw(page, -leftToReduce, -topToReduce)
# Save the new document
newPdf.SaveToFile("Output/ReduceMargins.pdf", FileFormat.PDF)
# Dispose resources
originalPdf.Dispose()
newPdf.Dispose()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Modifying PDF documents to suit various usage scenarios is a common task for PDF document creators and managers. Among these operations, splitting and merging PDF pages can assist in reorganizing PDF content for printing, typesetting, etc. By using Python programs, developers can easily split one page from a PDF document to several pages or merge multiple PDF pages into a single page. This article will demonstrate how to use Spire.PDF for Python for splitting and merging PDF pages in Python programs.
- Split One PDF Page into Several PDF Pages with Python
- Merge Multiple PDF Pages into a Single Page with Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to: How to Install Spire.PDF for Python on Windows
Split One PDF Page into Several PDF Pages with Python
With Spire.PDF for Python, developers draw a PDF page on a new PDF page using the PdfPageBase.CreateTemplate().Draw(newPage PdfPageBase, PointF) method. When drawing, if the current new page cannot fully accommodate the content of the original page, a new page is automatically created, and the remaining content is drawn on it. Therefore, we can create a new PDF document and control the drawing result by specifying the page size to achieve specified division of PDF pages horizontally or vertically.
Here are the steps to vertically split a PDF page into two separate PDF pages:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get the first page of the document using PdfDocument.Pages.get_Item() method.
- Create a new PDF document by creating an object of PdfDocument class.
- Set the margins of the new document to 0 through PdfDocument.PageSettings.Margins.All property.
- Get the width and height of the retrieved page through PdfPageBase.Size.Width property and PdfPageBase.Size.Height property.
- Set the width of the new PDF document to the same as the retrieved page through PdfDocument.PageSettings.Width property and its height to half of the retrieved page's height through PdfDocument.PageSettings.Height property.
- Add a new page in the new document using PdfDocument.Pages.Add() method.
- Draw the content of the retrieved page onto the new page using PdfPageBase.CreateTemplate().Draw() method.
- Save the new document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
from spire.pdf.common import *
# Create an object of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Get the first page of the document
page = pdf.Pages.get_Item(0)
# Create a new PDF document
newPdf = PdfDocument()
# Set the margins of the new PDF document to 0
newPdf.PageSettings.Margins.All = 0.0
# Get the width and height of the retrieved page
width = page.Size.Width
height = page.Size.Height
# Set the width of the new PDF document to the same as the retrieved page and its height to half of the retrieved page's height
newPdf.PageSettings.Width = width
newPdf.PageSettings.Height = height / 2
# Add a new page to the new PDF document
newPage = newPdf.Pages.Add()
# Draw the content of the retrieved page onto the new page
page.CreateTemplate().Draw(newPage, PointF(0.0, 0.0))
# Save the new PDF document
newPdf.SaveToFile("output/SplitPDFPage.pdf")
pdf.Close()
newPdf.Close()
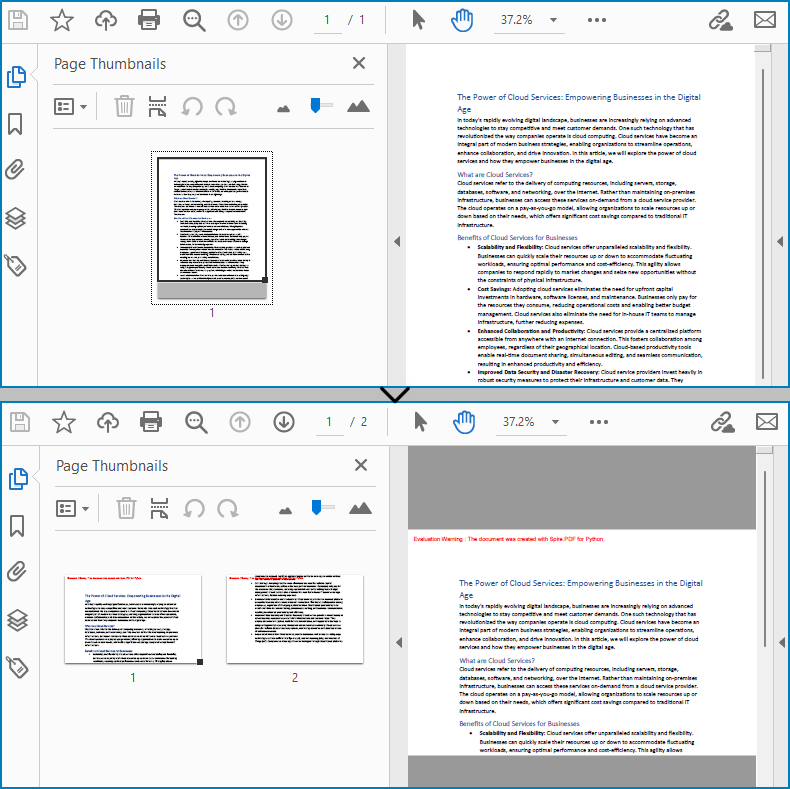
Merge Multiple PDF Pages into a Single Page with Python
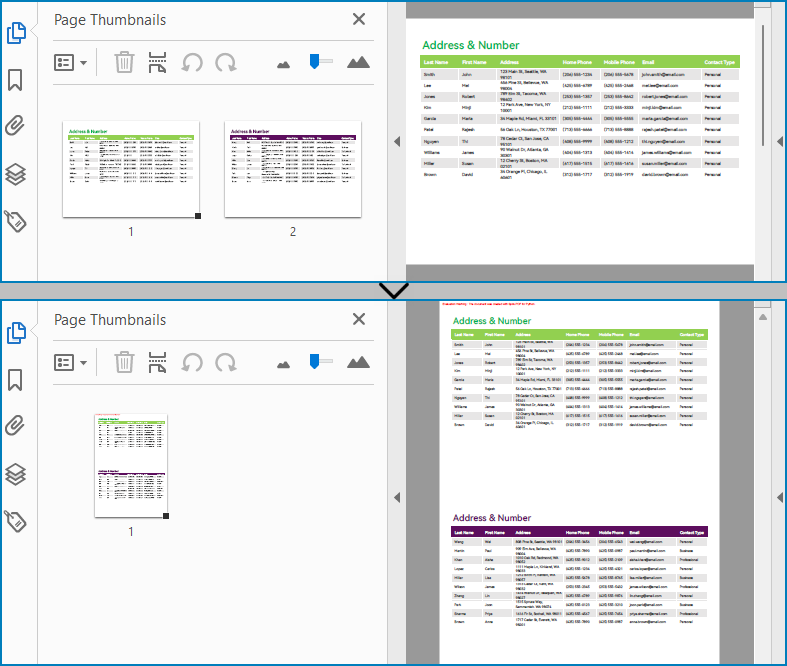
Similarly, developers can merge PDF pages by drawing different pages on the same PDF page. It should be noted that the pages to be merged are preferably in the same width or height, otherwise it is necessary to take the maximum value to ensure correct drawing.
The detailed steps for merging two PDF pages into a single PDF page are as follows:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get the first and second pages of the document using PdfDocument.Pages.get_Item() method.
- Create a new PDF document by creating an object of PdfDocument class.
- Set the margins of the new document to 0 through PdfDocument.PageSettings.Margins.All property.
- Get the width and height of the two retrieved pages through PdfPageBase.Size.Width property and PdfPageBase.Size.Height property.
- Set the width of the new PDF document to the same as the retrieved pages through PdfDocument.PageSettings.Width property and its height to the sum of the two retrieved pages' heights through PdfDocument.PageSettings.Height property.
- Draw the content of the two retrieved pages onto the new page using PdfPageBase.CreateTemplate().Draw() method.
- Save the new document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
from spire.pdf.common import *
# Create an object of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample1.pdf")
# Get the first page and the second page of the document
page = pdf.Pages.get_Item(0)
page1 = pdf.Pages.get_Item(0)
# Create a new PDF document
newPdf = PdfDocument()
# Set the margins of the new PDF document to 0
newPdf.PageSettings.Margins.All = 0.0
# Set the page width of the new document to the same as the retrieved page
newPdf.PageSettings.Width = page.Size.Width
# Set the page height of the new document to the sum of the heights of the two retrieved pages
newPdf.PageSettings.Height = page.Size.Height + page1.Size.Height
# Add a new page to the new PDF document
newPage = newPdf.Pages.Add()
# Draw the content of the retrieved pages onto the new page
page.CreateTemplate().Draw(newPage, PointF(0.0, 0.0))
page1.CreateTemplate().Draw(newPage, PointF(0.0, page.Size.Height))
# Save the new document
newPdf.SaveToFile("output/MergePDFPages.pdf")
pdf.Close()
newPdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
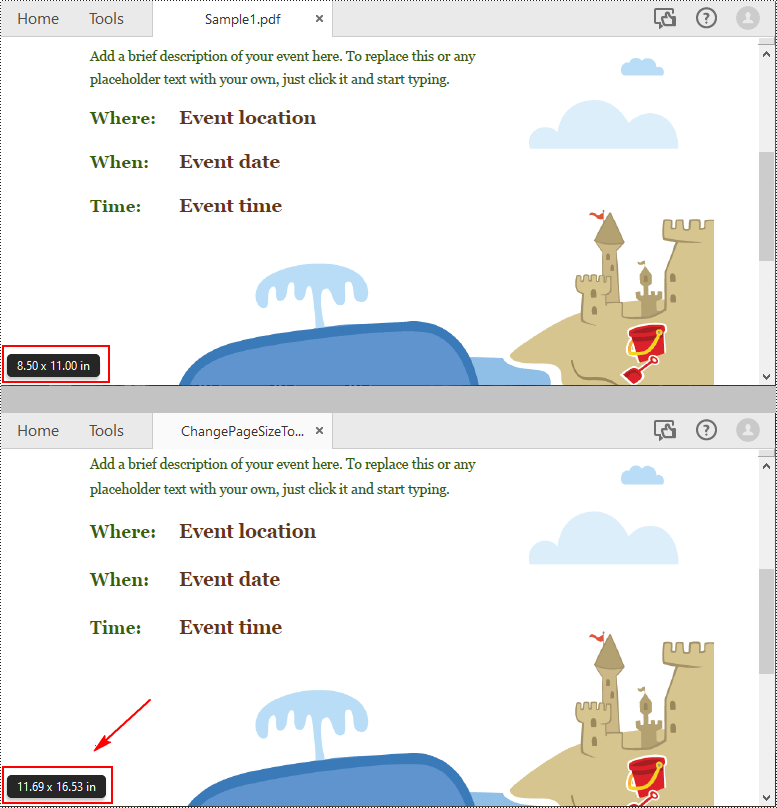
In PDF, you can change the page size to make the document meet different needs. For example, a smaller page size is required when creating handouts or compact versions of documents, while a larger page size could be useful for designing posters or graphics-intensive materials. In some cases, you may also need to get the page dimensions (width and height) to determine if the document is resized optimally. In this article, you will learn how to change or get PDF page size programmatically in Python using Spire.PDF for Python.
- Change PDF Page Size to a Standard Paper Size with Python
- Change PDF Page Size to a Custom Paper Size with Python
- Get PDF Page Size with Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Change PDF Page Size to a Standard Paper Size with Python
The way to change the page size of a PDF file is to create a new PDF file and add pages of the desired size to it, then create templates based on the pages in the original PDF file and draw the templates onto the pages in the new PDF file. This process will preserve text, images, and other elements present in the original PDF file.
Spire.PDF for Python supports a variety of standard paper size, such as letter, legal, A0, A1, A2, A3, A4, B0, B1, B2, B3, B4 and so on. The following are the steps to change the page size of a PDF file to a standard paper size:
- Initialize a PdfDocument instance and load the original PDF file using PdfDocument.LoadFromFile() method.
- Initialize another PdfDocument instance to create a new PDF file.
- Loop through the pages in the original PDF.
- Add pages of the desired size to the new PDF file using PdfDocument.Pages.Add() method.
- Initialize a PdfTextLayout instance and set the text layout as one page through PdfTextLayout.Layout property.
- Create templates based on the pages in the original PDF using PdfPageBase.CreateTemplate() method.
- Draw the templates onto the pages in the new PDF file with the specified text layout using PdfTemplate.Draw() method.
- Save the result file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
inputFile = "Sample1.pdf"
outputFile = "ChangePageSizeToA3.pdf"
# Create a PdfDocument instance
originalPdf = PdfDocument()
# Load the original PDF document
originalPdf.LoadFromFile(inputFile)
# Create a new PDF document
newPdf = PdfDocument()
# Loop through the pages in the original PDF
for i in range(originalPdf.Pages.Count):
page = originalPdf.Pages.get_Item(i)
# Add pages of size A3 to the new PDF
newPage = newPdf.Pages.Add(PdfPageSize.A3(), PdfMargins(0.0))
# Create a PdfTextLayout instance
layout = PdfTextLayout()
# Set text layout as one page (if not set the content will not scale to fit page size)
layout.Layout = PdfLayoutType.OnePage
# Create templates based on the pages in the original PDF
template = page.CreateTemplate()
# Draw the templates onto the pages in the new PDF
template.Draw(newPage, PointF.Empty(), layout)
# Save the result document
newPdf.SaveToFile(outputFile)
newPdf.Close()
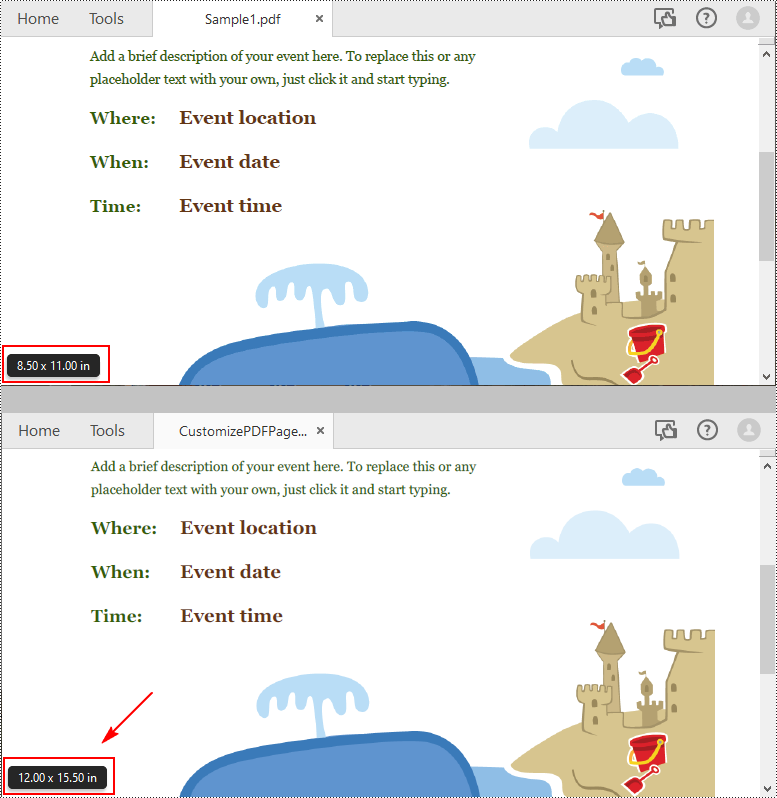
Change PDF Page Size to a Custom Paper Size with Python
Spire.PDF for Python uses point (1/72 of an inch) as the unit of measure. If you need to change the page size of a PDF to a custom paper size in other units of measure like inches or millimeters, you can use the PdfUnitConvertor class to convert them to points.
The following are steps to change the page size of a PDF file to a custom paper size in inches:
- Initialize a PdfDocument instance and load the original PDF file using PdfDocument.LoadFromFile() method.
- Initialize another PdfDocument instance to create a new PDF file.
- Initialize a PdfUnitConvertor instance, then convert the custom size in inches to points using PdfUnitConvertor.ConvertUnits() method.
- Initialize a SizeF instance from the custom size.
- Loop through the pages in the original PDF.
- Add pages of the custom size to the new PDF file using PdfDocument.Pages.Add() method.
- Initialize a PdfTextLayout instance and set the text layout as one page through PdfTextLayout.Layout property.
- Create templates based on the pages in the original PDF using PdfPageBase.CreateTemplate() method.
- Draw the templates onto the pages in the new PDF file with the specified text layout using PdfTemplate.Draw() method.
- Save the result file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
inputFile = "Sample1.pdf"
outputFile = "CustomizePdfPageSize.pdf"
# Create a PdfDocument instance
originalPdf = PdfDocument()
# Load the original PDF document
originalPdf.LoadFromFile(inputFile)
# Create a new PDF document
newPdf = PdfDocument()
# Create a PdfUnitConvertor instance
unitCvtr = PdfUnitConvertor()
# Convert the custom size in inches to points
width = unitCvtr.ConvertUnits(12.0, PdfGraphicsUnit.Inch, PdfGraphicsUnit.Point)
height = unitCvtr.ConvertUnits(15.5, PdfGraphicsUnit.Inch, PdfGraphicsUnit.Point)
#Create a new SizeF instance from the custom size, then it will be used as the page size of the new PDF
size = SizeF(width, height)
# Loop through the pages in the original PDF
for i in range(originalPdf.Pages.Count):
page = originalPdf.Pages.get_Item(i)
# Add pages of the custom size (12.0*15.5 inches) to the new PDF
newPage = newPdf.Pages.Add(size, PdfMargins(0.0))
# Create a PdfTextLayout instance
layout = PdfTextLayout()
# Set text layout as one page (if not set the content will not scale to fit page size)
layout.Layout = PdfLayoutType.OnePage
# Create templates based on the pages in the original PDF
template = page.CreateTemplate()
# Draw the templates onto the pages in the new PDF
template.Draw(newPage, PointF.Empty(), layout)
# Save the result document
newPdf.SaveToFile(outputFile)
newPdf.Close()
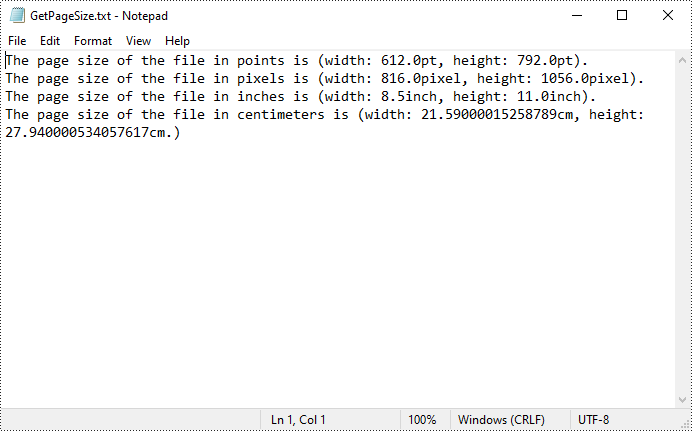
Get PDF Page Size with Python
Spire.PDF for Python offers the PdfPageBase.Size.Width and PdfPageBase.Size.Height properties to get the width and height of a PDF page in points. If you want to convert the default unit of measure to other units, you can use the PdfUnitConvertor class.
The following are the steps to get the PDF page size:
- Initialize a PdfDocument instance.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get a specified page using PdfDocument.Pages[] property.
- Get the width and height of the PDF page using PdfPageBase.Size.Width and PdfPageBase.Size.Height properties.
- Initialize a PdfUnitConvertor instance, and then convert the size units from points to other units of measure using PdfUnitConvertor.ConvertUnits() method.
- Add the size information to a StringBuilder instance, and then save the result to a TXT file.
- Python
from spire.pdf.common import *
from spire.pdf import *
def AppendAllText(fname: str, text: List[str]):
fp = open(fname, "w")
for s in text:
fp.write(s + "\n")
fp.close()
inputFile = "Sample1.pdf"
outputFile = "GetPageSize.txt"
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a sample PDF from disk
pdf.LoadFromFile(inputFile)
# Get the first page of the file
page = pdf.Pages[0]
# Get the width and height of page based on "point"
pointWidth = page.Size.Width
pointHeight = page.Size.Height
# Create PdfUnitConvertor to convert the unit
unitCvtr = PdfUnitConvertor()
# Convert size units from points to pixels
pixelWidth = unitCvtr.ConvertUnits(pointWidth, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel)
pixelHeight = unitCvtr.ConvertUnits(pointHeight, PdfGraphicsUnit.Point, PdfGraphicsUnit.Pixel)
# Convert size units from points to inches
inchWidth = unitCvtr.ConvertUnits(pointWidth, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch)
inchHeight = unitCvtr.ConvertUnits(pointHeight, PdfGraphicsUnit.Point, PdfGraphicsUnit.Inch)
# Convert size units from points to centimeters
centimeterWidth = unitCvtr.ConvertUnits(pointWidth, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter)
centimeterHeight = unitCvtr.ConvertUnits(pointHeight, PdfGraphicsUnit.Point, PdfGraphicsUnit.Centimeter)
# Add the size information to a StringBuilder instance
content = []
content.append("The page size of the file in points is (width: " +
str(pointWidth) + "pt, height: " + str(pointHeight) + "pt).")
content.append("The page size of the file in pixels is (width: " +
str(pixelWidth) + "pixel, height: " + str(pixelHeight) + "pixel).")
content.append("The page size of the file in inches is (width: " +
str(inchWidth) + "inch, height: " + str(inchHeight) + "inch).")
content.append("The page size of the file in centimeters is (width: " +
str(centimeterWidth) + "cm, height: " + str(centimeterHeight) + "cm.)")
# Save to a txt file
AppendAllText(outputFile, content)
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
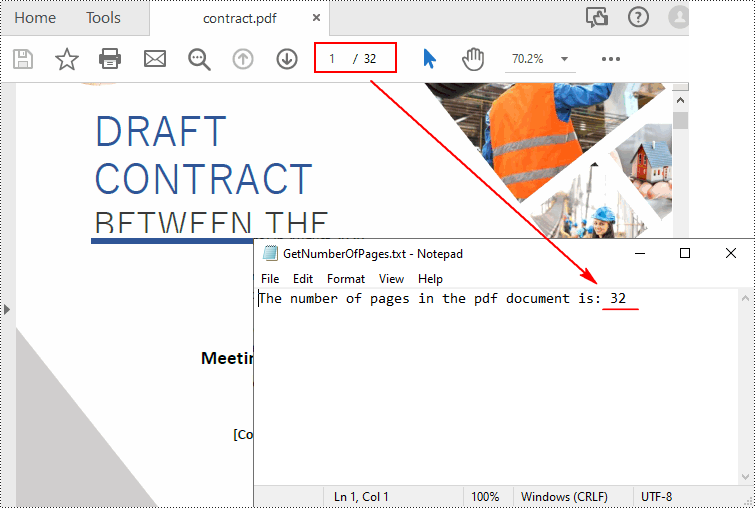
To get the number of pages in a PDF file, you can open the file in a PDF viewer such as Adobe, which has a built-in page count feature. However, when there is a batch of PDF files, opening each file to check how many pages it contains is a time-consuming task. In this article, you will learn how to quicky count the number of pages in a PDF file through programming using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Count the Number of Pages in a PDF File in Python
Spire.PDF for Python offers the PdfDocument.Pages.Count property to quickly count the number of pages in a PDF file without opening it. The following are the detailed steps.
- Create a PdfDocument object.
- Load a sample PDF document using PdfDocument.LoadFromFile() method.
- Count the number of pages in the PDF document using PdfDocument.Pages.Count property.
- Write the result to a TXT file or print it out directly.
- Python
from spire.pdf.common import *
from spire.pdf import *
def AppendText(fname: str, text: str):
fp = open(fname, "w")
fp.write(text + "\n")
fp.close()
# Specify the input and output files
inputFile = "contract.pdf"
outputFile = "GetNumberOfPages.txt"
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF document from disk
pdf.LoadFromFile(inputFile)
# Count the number of pages in the document
count = pdf.Pages.Count
# Print the result
print("Total Pages:", count)
# Write the result to a TXT file
AppendText(
outputFile, "The number of pages in the pdf document is: " + str(count))
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Pages are the most fundamental components of a PDF document. If you want to add new information or supplemental material to an existing PDF, it is necessary to add new pages. Conversely, if there are some pages that contain incorrect or irrelevant content, you can remove them to create a more professional document. In this article, you will learn how to programmatically add or delete pages in PDF using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
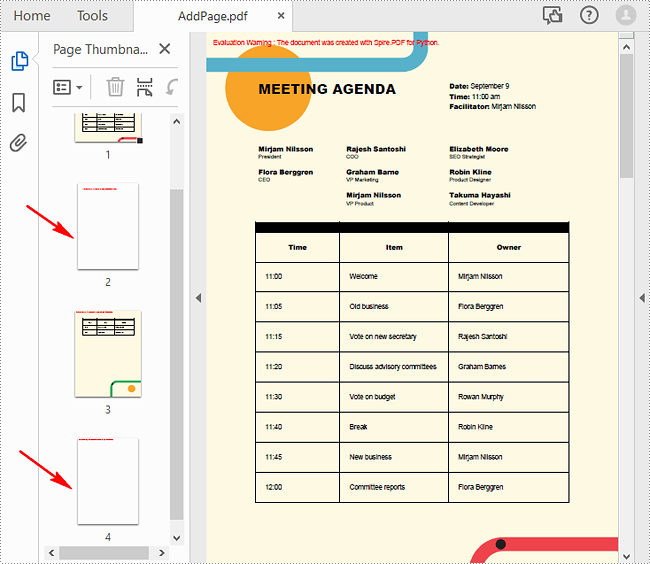
Add Empty Pages to a PDF Document in Python
With Spire.PDF for Python, you can easily add a blank page to a specific position or to the end of the document using PdfDocument.Pages.Insert() or PdfDocument.Pages.Add(SizeF, PdfMargins) methods. The following are the detailed steps.
- Create a PdfDocument object.
- Load a sample PDF document using PdfDocument.LoadFromFile() method.
- Create a new blank page and insert it into a specific position of the document using PdfDocument.Pages.Insert() method.
- Create another new blank page with the specified size and margins, and then append it to the end of the document using PdfDocument.Pages.Add(SizeF, PdfMargins) method.
- Save the result document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Test.pdf")
# Insert a blank page to the document as the second page
pdf.Pages.Insert(1)
# Add an empty page to the end of the document
pdf.Pages.Add(PdfPageSize.A4(), PdfMargins(0.0, 0.0))
# Save the result document
pdf.SaveToFile("AddPage.pdf")
pdf.Close()
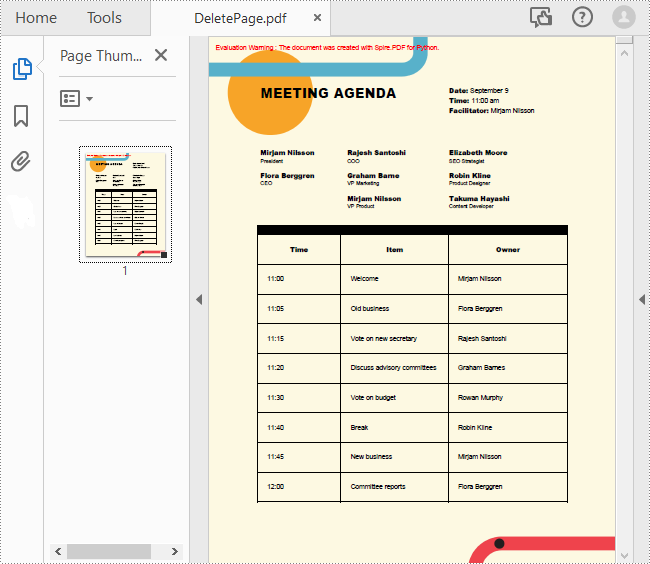
Delete an Existing Page in a PDF Document in Python
To remove a specified page from a PDF, you can use the PdfDocument.Pages.RemoveAt() method. The following are the detailed steps.
- Create a PdfDocument object.
- Load a sample PDF document using PdfDocument.LoadFromFile() method.
- Remove a specified page from the document using PdfDocument.Pages.RemoveAt() method.
- Save the result document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Test.pdf")
# Delete the second page of the document
pdf.Pages.RemoveAt(1)
# Save the result document
pdf.SaveToFile("DeletePage.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Applying a background color or image to a PDF can be an effective way to enhance its visual appeal, create a professional look, or reinforce branding elements. By adding a background, you can customize the overall appearance of your PDF document and make it more engaging for readers. Whether you want to use a solid color or incorporate a captivating image, this feature allows you to personalize your PDFs and make them stand out. In this article, you will learn how to set a background color or image for a PDF document in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
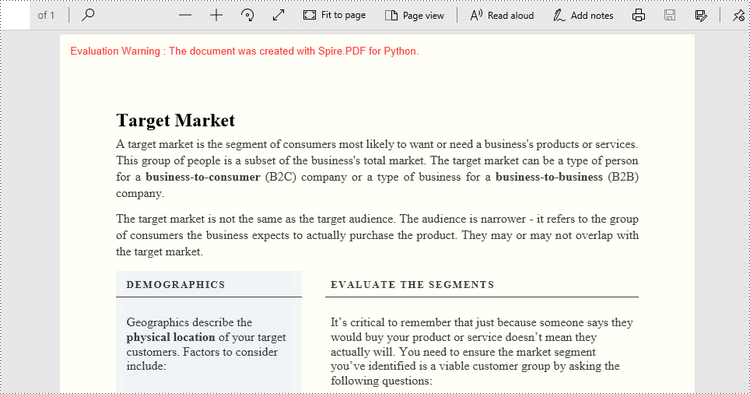
Set a Background Color for PDF in Python
Spire.PDF for Python offers the PdfPageBase.BackgroundColor property to get or set the background color of a certain page. To add a solid color to the background of each page in the document, follow the steps below.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Traverse through the pages in the document, and get a specific page through PdfDocument.Pages[index] property.
- Apply a solid color to the background through PdfPageBase.BackgroundColor property.
- Save the document to a different PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.pdf")
# Loop through the pages in the document
for i in range(doc.Pages.Count):
# Get a particular page
page = doc.Pages[i]
# Set background color
page.BackgroundColor = Color.get_LightYellow()
# Save the document to a different file
doc.SaveToFile("output/SetBackgroundColor.pdf")
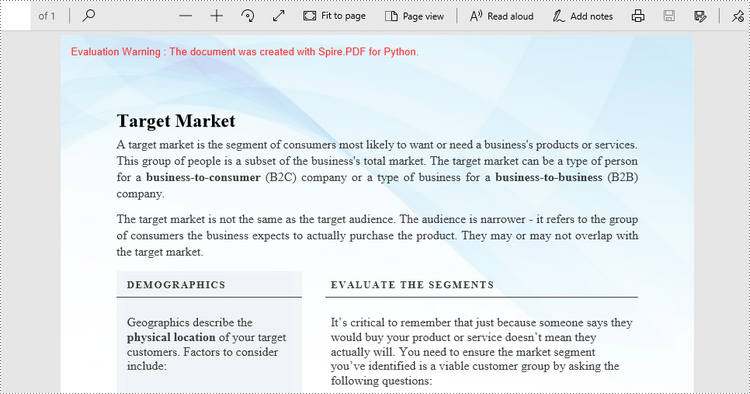
Set a Background Image for PDF in Python
Likewise, an image can be applied to the background of a specific page via PdfPageBase.BackgroundImage property. The steps to set an image background for the entire document are as follows.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Traverse through the pages in the document, and get a specific page through PdfDocument.Pages[index] property.
- Apply an image to the background through PdfPageBase.BackgroundImage property.
- Save the document to a different PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.pdf")
# Loop through the pages in the document
for i in range(doc.Pages.Count):
# Get a particular page
page = doc.Pages[i]
# Set background image
page.BackgroundImage = Stream("C:\\Users\\Administrator\\Desktop\\img.jpg")
# Save the document to a different file
doc.SaveToFile("output/SetBackgroundImage.pdf")
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
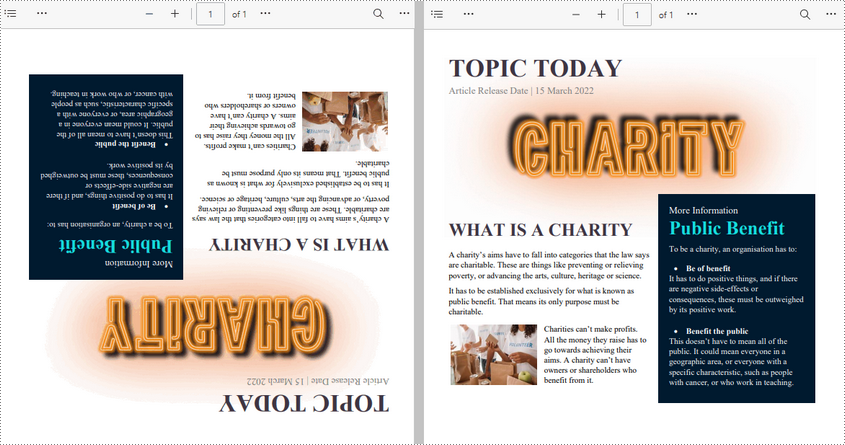
If you receive or download a PDF file and find that some of the pages are displayed in the wrong orientation (e.g., sideways or upside down), rotating the PDF file allows you to correct the page orientation for easier reading and viewing. This article will demonstrate how to programmatically rotate PDF pages using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Rotate a Specific Page in PDF in Python
Rotation is based on 90-degree increments. You can rotate a PDF page by 0/90/180/270 degrees. The following are the steps to rotate a PDF page:
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Get a specified page using PdfDocument.Pages[pageIndex] property.
- Get the original rotation angle of the page using PdfPageBase.Rotation.value property.
- Increase the original rotation angle by desired degrees.
- Apply the new rotation angle to the page using PdfPageBase.Rotation property
- Save the result document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Sample.pdf")
# Get the first page
page = pdf.Pages[0]
# Get the original rotation angle of the page
rotation = int(page.Rotation.value)
# Rotate the page 180 degrees clockwise based on the original rotation angle
rotation += int(PdfPageRotateAngle.RotateAngle180.value)
page.Rotation = PdfPageRotateAngle(rotation)
# Save the result document
pdf.SaveToFile("RotatePDFPage.pdf")
pdf.Close()
Rotate All Pages in PDF in Python
Spire.PDF for Python also allows you to loop through each page in a PDF file and then rotate them all. The following are the detailed steps.
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Loop through each page in the document.
- Get the original rotation angle of the page using PdfPageBase.Rotation.value property.
- Increase the original rotation angle by desired degrees.
- Apply the new rotation angle to the page using PdfPageBase.Rotation property.
- Save the result document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF document
pdf.LoadFromFile("Input.pdf")
# Loop through each page in the document
for i in range(pdf.Pages.Count):
page = pdf.Pages.get_Item(i)
# Get the original rotation angle of the page
rotation = int(page.Rotation.value)
# Rotate the page 180 degrees clockwise based on the original rotation angle
rotation += int(PdfPageRotateAngle.RotateAngle180.value)
page.Rotation = PdfPageRotateAngle(rotation)
# Save the result document
pdf.SaveToFile("RotatePDF.pdf")
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
