
Table of Contents
Install with Pip
pip install Spire.PDF
Related Links
Converting PDF files to editable text is a common need for researchers, analysts, and professionals who deal with large volumes of documents. Manual copying wastes time—Python offers a faster, more flexible solution. In this guide, you’ll learn how to convert PDF to text in Python efficiently, whether you want to keep the layout or extract specific content.

- Why Choose Spire.PDF for PDF to Text
- General Workflow for PDF to Text in Python
- Convert PDF to Text in Python Without Layout
- Convert PDF to Text in Python With Layout
- Convert a Specific PDF Page to Text
- To Wrap Up
- FAQs
Getting Started: Why Choose Spire.PDF for PDF to Text in Python
To convert PDF files to text using Python, you’ll need a reliable PDF processing library. Spire.PDF for Python is a powerful and developer-friendly API that allows you to read, edit, and convert PDF documents in Python applications — no need for Adobe Acrobat or other third-party software.
This library is ideal for automating PDF workflows such as extracting text, adding annotations, or merging and splitting files. It supports a wide range of PDF features and works seamlessly in both desktop and server environments. You can donwload it to install mannually or quickly install Spire.PDF via PyPI using the following command:
pip install Spire.PDFFor smaller or personal projects, a free version is available with basic functionality. If you need advanced features such as PDF signing or form filling, you can upgrade to the commercial edition at any time.
General Workflow for PDF to Text in Python
Converting a PDF to text becomes simple and efficient with the help of Spire.PDF for Python. You can easily complete the task by reusing the sample code provided in the following sections and customizing it to fit your needs. But before diving into the code, let’s take a quick look at the general workflow behind this process.
- Create an object of PdfDocument class and load a PDF file using LoadFromFile() method.
- Create an object of PdfTextExtractOptions class and set the text extracting options, including extracting all text, showing hidden text, only extracting text in a specified area, and simple extraction.
- Get a page in the document using PdfDocument.Pages.get_Item() method and create PdfTextExtractor objects based on each page to extract the text from the page using Extract() method with specified options.
- Save the extracted text as a text file and close the object.
How to Convert PDF to Text in Python Without Layout
If you only need the plain text content from a PDF and don’t care about preserving the original layout, you can use a simple method to extract text. This approach is faster and easier, especially when working with scanned documents or large batches of files. In this section, we’ll show you how to convert PDF to text in Python without preserving the layout.
To extract text without preserving layout, follow these simplified steps:
- Create an instance of PdfDocument and load the PDF file.
- Create a PdfTextExtractOptions object and configure the text extraction options.
- Set IsSimpleExtraction = True to ignore the layout and extract raw text.
- Loop through all pages of the PDF.
- Extract text from each page and write it to a .txt file.
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to use simple extraction method
extract_options.IsSimpleExtraction = True
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
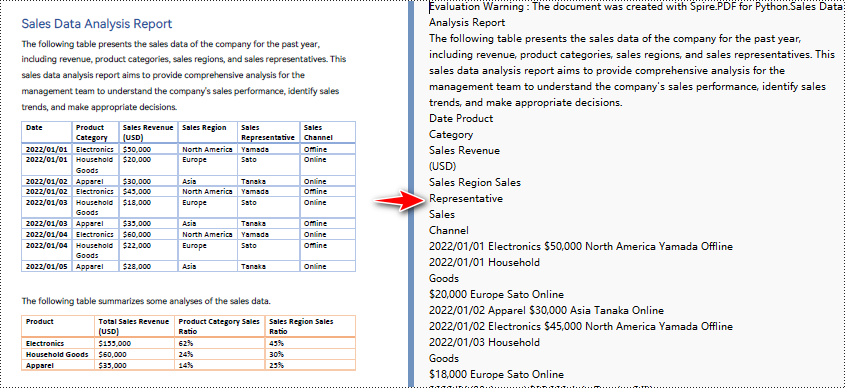
How to Convert PDF to Text in Python With Layout
To convert PDF to text in Python with layout, Spire.PDF preserves formatting like tables and paragraphs by default. The steps are similar to the general overview, but you still need to loop through each page for full-text extraction.
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
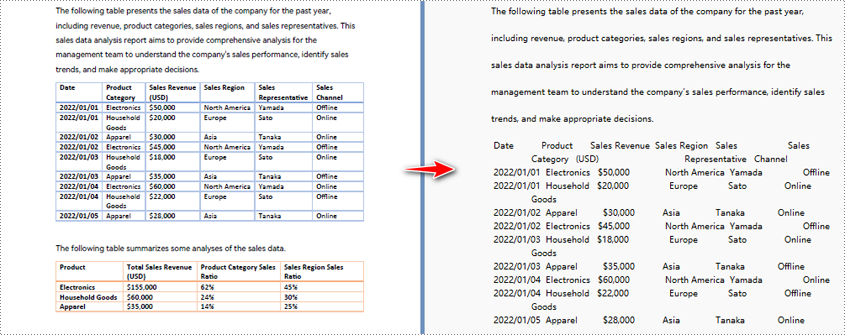
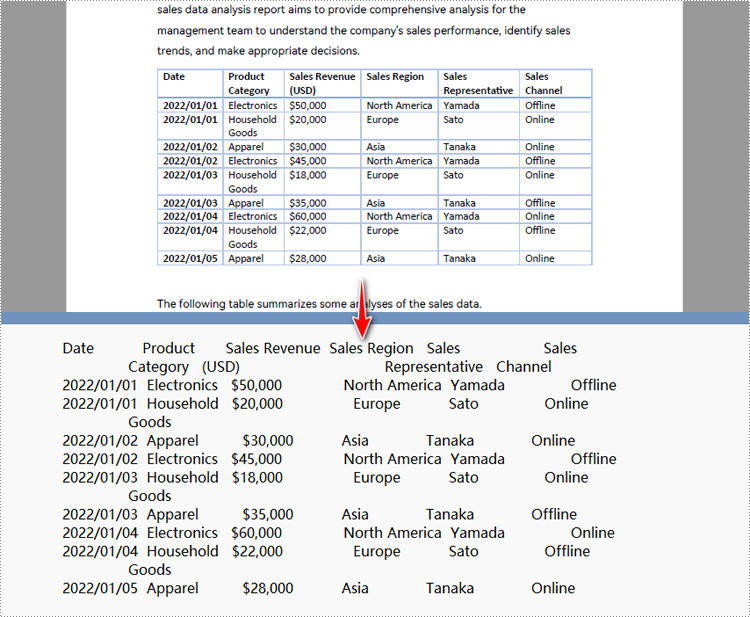
Convert a Specific PDF Page to Text in Python
Need to extract text from only one page of a PDF instead of the entire document? With Spire.PDF, the PDF to Text converter in Python, you can easily target and convert a specific PDF page to text. The steps are the same as shown in the general overview. If you're already familiar with them, just copy the code below into any Python editor and automate your PDF to text conversion!
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
from spire.pdf import RectangleF
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to extract specific page area
extract_options.ExtractArea = RectangleF(50.0, 220.0, 700.0, 230.0)
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
extracted_text = text_extractor.ExtractText(extract_options)
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
To Wrap Up
In this post, we covered how to convert PDF to text using Python and Spire.PDF, with clear steps and code examples for fast, efficient conversion. We also highlighted the benefits and pointed to OCR tools for image-based PDFs. For any issues or support, feel free to contact us.
FAQs about Converting PDF to Text
Q1: How do I convert a PDF to readable and editable text in Python?
A: You can convert a PDF to text in Python using the Spire.PDF library. It allows you to extract text from PDF files while optionally keeping the original layout. You don’t need Adobe Acrobat, and both visible and image-based PDFs are supported.
Q2: Is there a free tool to convert PDF to text?
A: Yes. Spire.PDF for Python provides a free edition that allows you to convert PDF to text without relying on Adobe Acrobat or other software. Online tools are also available, but they’re more suitable for occasional use or small files.
Q3: Can Python extract data from PDF? A: Yes, Python can extract data from PDF files. Using Spire.PDF, you can easily extract not only text but also other elements such as images, annotations, bookmarks, and even attachments. This makes it a versatile tool for working with PDF content in Python.
