How to Convert EPUB to PDF (Fast & Easy Guide)

EPUB, short for Electronic Publication, is one of the most popular eBook formats and is supported by many e-readers, offering a comfortable reading experience. However, it isn’t compatible with every device or platform. When comparing EPUB vs PDF, PDF often proves to be more versatile: it works reliably on computers, tablets, and devices that don’t support EPUB, and it maintains consistent layout for printing, sharing, and file transfer. In this guide, we’ll walk through several easy ways to convert EPUB to PDF, helping you choose the method that works best for your needs.
- How to Convert EPUB to PDF Online
- Convert an EPUB File to PDF on Windows or Mac
- How to Batch Convert EPUB to PDF in Simple Code
- The Conclusion
How to Convert EPUB to PDF Online
When it comes to how to convert EPUB to PDF, the first solution that often comes to mind is using online tools. These tools work on any device with an internet connection, whether it’s a smartphone, tablet, or computer. They are usually very easy to use, and the conversion speed depends on your network, so you typically won’t have to wait long. Most EPUB to PDF converters don’t even require signing up, making them a quick and convenient option. Here, we’ll demonstrate how to convert an EPUB file to PDF using PDFgear.
Steps to change EPUB to PDF online with PDFgear:
- Go to the PDFgear conversion page.
- Click Select Epub File to upload your file, and the conversion will start automatically.
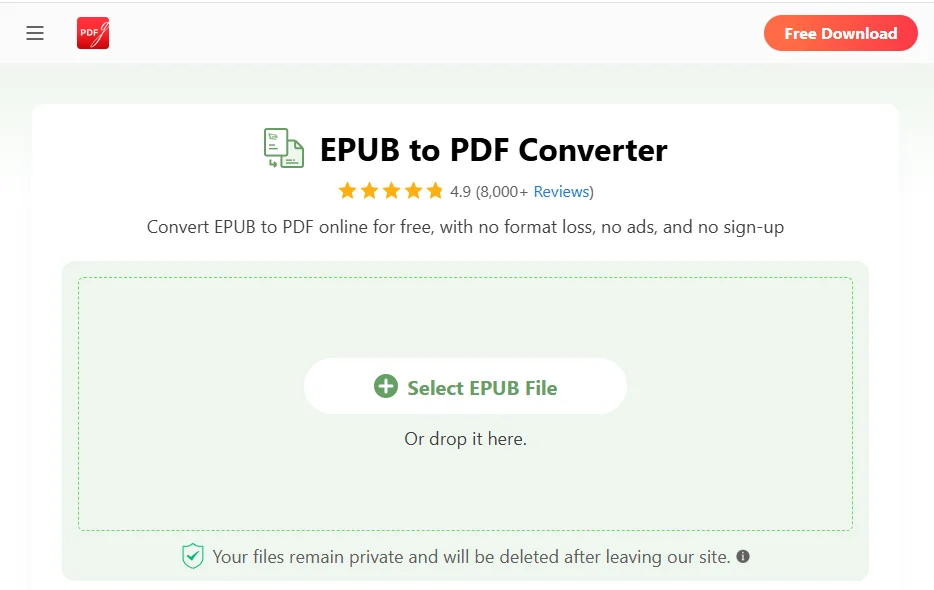
- Once the conversion is complete, click Download File to save the converted PDF to your device.
Although online EPUB-to-PDF converters are convenient, they also come with a few drawbacks—such as requiring an internet connection and posing potential privacy or data leakage risks. For these reasons, it’s best to use them only for smaller files or documents that don’t contain sensitive information.
Convert an EPUB File to PDF on Windows or Mac
If you prefer converting your files in a more secure and stable environment, using a dedicated desktop tool is a great option. One of the most popular choices is Calibre, an open-source and powerful eBook management tool. It supports converting between multiple formats—including EPUB, MOBI, and PDF. Calibre works on both Windows and macOS, making it ideal for converting large files or performing offline conversions without relying on an internet connection.
After installing the tool, you can convert EPUB to PDF by following the steps:
- Click Add books to import the EPUB files you want to convert.
- Select the imported EPUB files from your Calibre library.
- Click Convert books and choose PDF as the output format.
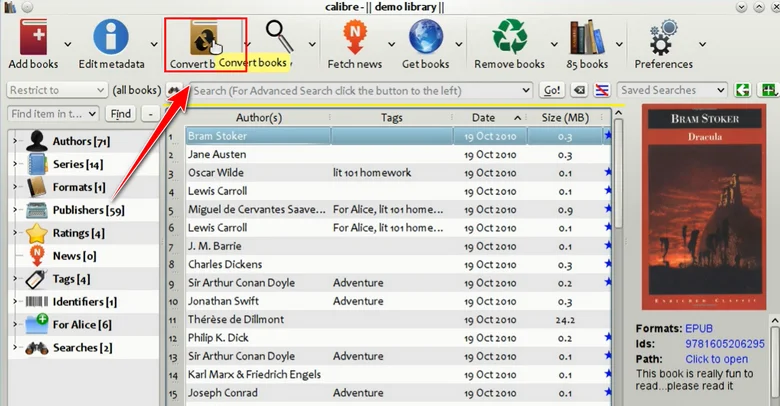
- Edit the metadata if needed, such as the title, author, or cover.
- Click OK to start the conversion and return to your Calibre library to download the generated PDF.
How to Batch Convert EPUB to PDF in Simple Code
Besides the two common methods mentioned above, you can also change EPUB to PDF with just a few lines of code. Using code not only reduces the number of steps you need to perform but also supports batch conversion and eliminates any risk of data leakage since everything runs locally on your device.
In this chapter, we'll use Free Spire.Doc for Python to show you how to convert from EPUB to PDF in Python. As a professional document-processing library, it supports many format conversions—including turning EPUB into Word or converting Word documents to PDF.

If you're looking for a more efficient, controllable, and automation-friendly way to handle document conversions, Free Spire.Doc is definitely worth considering.
Steps to Convert an EPUB File to PDF with Free Spire.Doc
- Install Free Spire.Doc
Use the following pip command to install Free Spire.Doc in your Python environment (e.g., VS Code), or download the installer for a custom setup:
pip install spire.doc
- Import the Required Modules
Import the necessary classes for document processing:
from spire.doc import Document, FileFormat
- Create a Document Object
Create a Document object to load and handle the EPUB file:
document = Document()
- Load the EPUB File
Use the LoadFromFile() method to load your EPUB file. Make sure the file path is correct:
document.LoadFromFile("E:/DownloadsNew/wasteland.epub")
- Save as PDF
Save the loaded EPUB file as a PDF:
document.SaveToFile("E:/DownloadsNew/output.pdf", FileFormat.PDF)
Full Code Example:
from spire.doc import Document, FileFormat
# Create a Document object
document = Document()
# Load an EPUB file
document.LoadFromFile("E:/DownloadsNew/wasteland.epub")
# Save the EPUB document as a PDF
document.SaveToFile("E:/DownloadsNew/output.pdf", FileFormat.PDF)
Here's the preview of the output PDF: 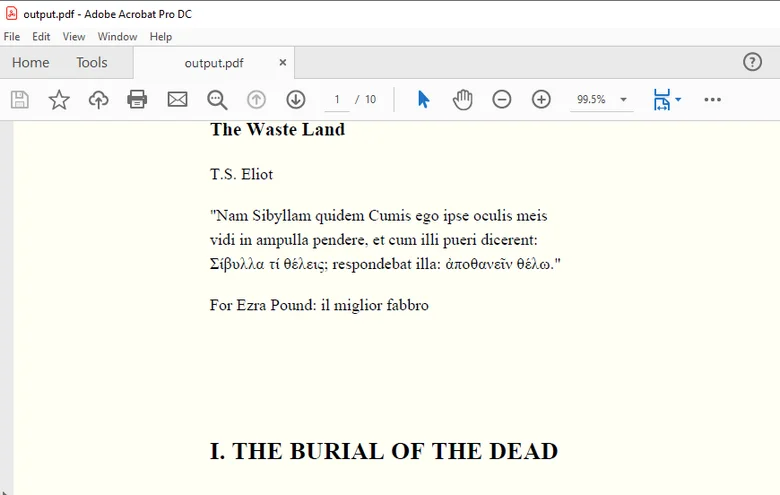
Tip: If you also need to process the converted PDF files—such as merging multiple PDFs or splitting a PDF—you can use Free Spire.PDF, a library specifically designed for handling PDF documents.
Batch Convert Multiple Epub Files to PDFs
The logic for batch conversion is the same as converting a single file, but it’s best to put all the files in the same folder to make them easier to iterate over. Here’s the sample code:
from spire.doc import Document, FileFormat
# Specify the file path
folder_path = "E:/DownloadsNew/"
# Get EPUB files to convert
epub_files = ["wasteland.epub", "sample.epub", "script.epub"]
for epub_name in epub_files:
epub_path = folder_path + epub_name
pdf_name = epub_name.replace(".epub", ".pdf")
pdf_path = folder_path + pdf_name
# Create a Document object
document = Document()
# Load each EPUB document
document.LoadFromFile(epub_path)
# Convert the EPUB file as a PDF
document.SaveToFile(pdf_path, FileFormat.PDF)
The Bottom Line
Whether you use online tools, desktop software, or code to convert EPUB files to PDFs, each method has its advantages. If you want to convert PDFs while also having the flexibility to handle document content or perform conversions between different formats, Free Spire.Doc provides a reliable local solution, making it easy to work with EPUB, Word, PDF, and other document types.
Also Read
How to Unsecure a PDF (With or Without a Password)
Table of Contents
While password protection helps keep PDF files secure, entering the password every time can slow down your workflow. For non-confidential documents, removing restrictions makes it easier to access and extract the information you need. This article introduces three ways to unsecure a PDF—whether or not you know the password.
- Unsecure a PDF with Adobe Acrobat Pro DC
- Unsecure a PDF Document Using Code
- Unsecure a PDF without Password Online
- The Conclusion
- FAQs
How to Unsecure a PDF with Adobe Acrobat Pro DC
When it comes to making a PDF unsecured, most people immediately think of Adobe Acrobat Pro DC. The software includes a built-in feature that allows users to unsecure a PDF with a password and remove its restrictions in just a few clicks. If you already have Adobe Acrobat Pro DC installed, here’s how to turn a secured PDF into an unsecured one for easier access and sharing.
Steps to Unsecure a PDF with Adobe Acrobat Pro DC
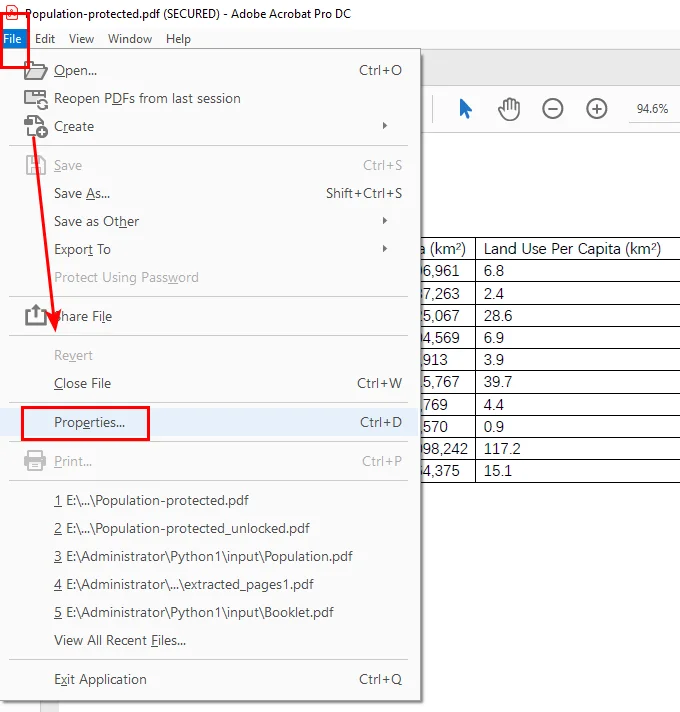
- Open the secured PDF file in Adobe Acrobat Pro DC.
- Enter the password to access the document.
- Go to the top menu and select File > Properties.
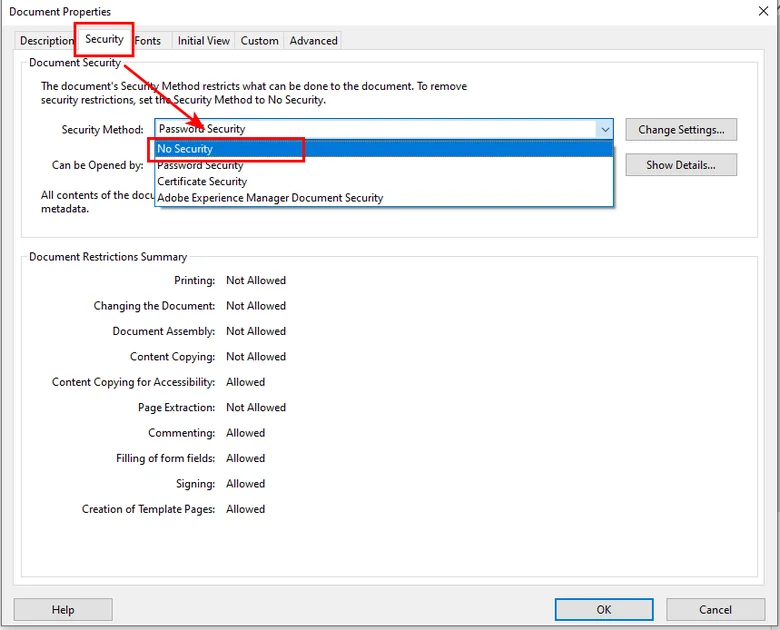
- In the Security tab, choose No Security from the “Security Method” dropdown.
- Click OK and then Save the PDF to apply the changes.
After these steps, your file becomes unsecured, allowing you to open, edit, and share it freely without entering a password each time.
How to Unsecure a PDF Document Free with Code
If you’re looking for a free and efficient way to unsecure a PDF document, Free Spire.PDF for Python is a great alternative to Adobe Acrobat. Unlike Acrobat, which requires a paid subscription, Free Spire.PDF lets you remove password protection directly through code—ideal for users who prefer automation or need to process multiple files at once.

In this part, we’ll walk you through how to use the free Python library to open an encrypted file with a known password, remove its restrictions, and save it as an unsecured version. A clear, step-by-step Python example is also included to help you get started quickly.
Steps to unsecure a PDF File Using Free Spire.PDF
- Install Free Spire.PDF for Python
You can install the library via pip:
pip install Spire.PDF.Free
Alternatively, you can download the package from the official website and install it manually.
- Import the Required Modules
Import the necessary classes from the spire.pdf package.
- Create a PdfDocument Object
Initialize a PdfDocument instance to start working with the PDF file.
- Load the Secured PDF
Use the PdfDocument.LoadFromFile() method and provide the correct open password to load the protected document.
- Remove the Password Protection
Call the PdfDocument.Security.Encrypt() method and set both passwords to empty strings. This will remove all restrictions and make the PDF fully accessible.
- Save the Unsecured PDF
Use the PdfDocument.SaveToFile() method to save the unlocked PDF to a new file.
Here’s the complete code example that shows how to unsecure a PDF protected with both an open password and a permission password.
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load a password protected PDF file
doc.LoadFromFile("/input/Population-protected.pdf", "password")
# Set the open password and permission password as empty
doc.Security.Encrypt(str(), str(), PdfPermissionsFlags.Default, PdfEncryptionKeySize.Key128Bit, "permissionpassword")
# Save the unsecured PDF file
doc.SaveToFile("/output/Unsecured.pdf", FileFormat.PDF)
doc.Close()
After running this code, you’ll have full access to the PDF — converting, printing, and editing PDFs are no longer restricted.
How to Unsecure a PDF without Password Online
Besides the two options above, if you prefer a simpler, more direct approach, you can also try online unlocking tools. These tools work in your browser as long as you have internet access. Simply search for keywords like “how to unsecure a PDF file,” “unprotect PDF,” or “remove PDF password,” and you’ll find plenty of options.
In this tutorial, we’ll take iLovePDF as an example to show how to make a PDF file unsecured online.
Steps to unsecure a PDF document using online tools
- Go to iLovePDF Unlock PDF.
- Click Select PDF File and upload your secured PDF.
- Hit Unlock PDF and wait for the process to finish. The unlocked file will be automatically downloaded to your device.
Although online tools are very convenient — some can even unsecure a secured PDF without a password — their security cannot always be guaranteed. If your document still contains confidential information, it’s safer to use Adobe Acrobat or Free Spire.PDF for Python instead of uploading it to online platforms.
The Conclusion
In short, Adobe Acrobat is ideal for quick offline operations, Free Spire.PDF for Python suits users who prefer to unsecure a PDF through code automation, while online tools are perfect for occasional use without any setup. Choose the option that best fits your needs and workflow.
FAQs about Unsecuring a PDF
1. How can I unsecure a PDF without knowing the password?
You can try online tools like iLovePDF but their success depends on the file’s encryption level. For confidential documents, avoid using online services for security reasons.
2. What’s the best way to unsecure a PDF for free?
Free Spire.PDF for Python lets you unsecure a PDF completely through code — no subscription or manual steps required.
3. How do I remove copy protection from a PDF?
Free Spire.PDF for Python can remove both open passwords and permission restrictions at once, allowing you to copy, edit, and print the file freely.
4. How do I remove password protection using Adobe Acrobat?
Open the PDF in Adobe Acrobat Pro DC, enter the password, go to File > Properties > Security, choose “No Security,” and save the file.
ALSO READ
How to Extract Pages from a PDF for Free — No Adobe Needed
Many people open Adobe Acrobat only to find that extracting pages from a PDF is a paid feature. The good news is — you don’t have to pay for it. Whether you need to keep key pages from a contract or extract a section from a report, this guide will show you three free and easy ways to extract pages from a PDF in just a few clicks.
- Extract Pages from PDF with Google Chrome
- Save One Page of a PDF Quickly with Online Tools
- Extract Pages from a PDF for Free Using Python
- The Conclusion
How to Extract Pages from PDF with Google Chrome
You don’t need any extra software — Google Chrome alone can extract specific pages from a PDF online. Using its built-in Print feature, you can choose to save all pages, only odd or even pages, or any custom page range you like. Simply select the pages you want to keep and save them as a new PDF file. Here’s how to extract pages from a PDF using Google Chrome:
- Locate the PDF file you want to extract pages from and right-click to open it in Google Chrome.
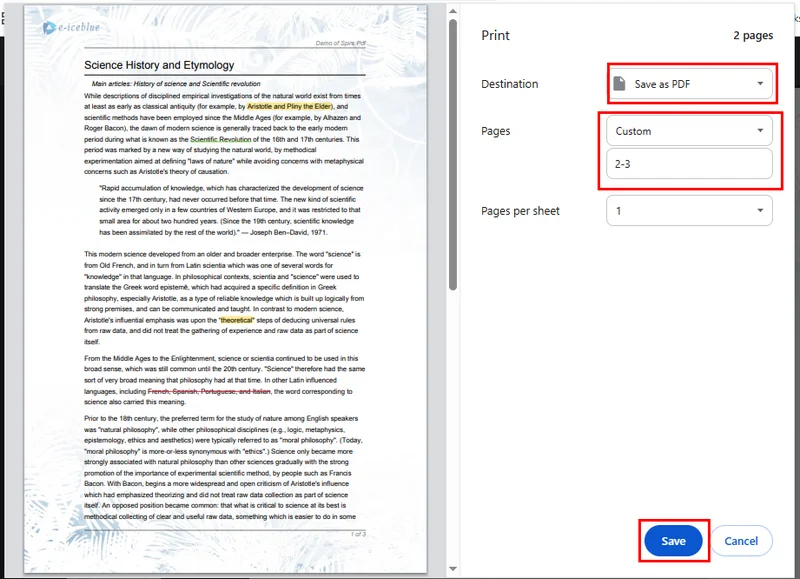
- Click the Print button in the top-right corner and change the destination printer to Save as PDF.
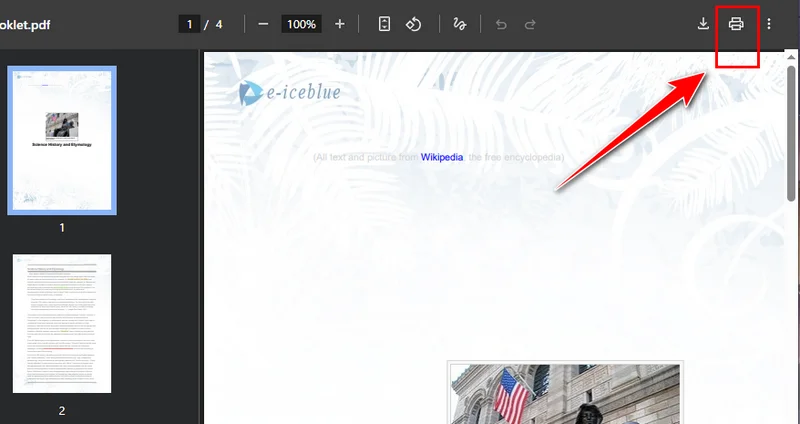
- Select the pages you want to keep, then click Save. Chrome will automatically download the new PDF to your device.
Pros
- No need to install any third-party software.
- Ideal for quickly extracting 1–2 pages.
- Smooth experience and widely accessible (almost all users have Chrome).
Cons
- Not suitable for extracting a large number of non-consecutive pages.
- Output options are quite basic.
How to Save One Page of a PDF Quickly with Online Tools
There are many ways to extract pages from a PDF. Besides using Chrome’s built-in feature, you can also use online tools to split PDF documents and save the pages you need. Since these tools are web-based, they work on both computers and mobile devices, and you don’t need to download anything or sign up. Just search for “how to extract pages from a PDF” in your browser, and you’ll find plenty of options. In this guide, we’ll demonstrate the process using Smallpdf, but don’t worry — most online tools work in a very similar way.
- Go to the PDF Extract page on Smallpdf.
- Drag your PDF file into the tool, which will automatically process it and display all the pages.
- Select the pages you want to extract, then click Finish. You can choose to export the pages as a single PDF or as separate PDF files.
- Once the extraction is complete, click the Download button to save the resulting PDF to your device.
Pros
- Can be used directly in your browser, without any downloads or installations.
- Supports extracting single pages, consecutive pages, or non-consecutive pages.
- Intuitive interface — just drag and drop, easy even for beginners.
- Works on any device with a browser and internet connection, highly compatible.
Cons
- Requires an internet connection; cannot be used offline.
- Some tools limit the file size for free users.
- Files are uploaded to the server, so be cautious with sensitive content.
- Advanced features, such as batch processing or watermark-free downloads, may require payment.
How to Extract Pages from a PDF for Free Using Python
When dealing with PDFs, both Chrome and online tools share one limitation — they can only process one file at a time. If you’re handling multiple PDFs, there’s a faster and more professional solution: Free Spire.PDF for Python.
This powerful library provides a wide range of PDF features, including extracting pages, converting formats, and editing content. With Free Spire.PDF, you can easily extract specific pages by adding them from the source PDF into a new document using the PdfDocument.InsertPage() method.
The sample code below demonstrates how to extract the 2nd and 4th pages from a PDF and merge them into a new file.
from spire.pdf import PdfDocument
# Load a PDF file
source_pdf = PdfDocument()
source_pdf.LoadFromFile("/input/Booklet.pdf")
# Create a new PdfDocument instance
new_pdf = PdfDocument()
# Extract page 2 and page 4
new_pdf.InsertPage(source_pdf, 1)
new_pdf.InsertPage(source_pdf, 3)
# Save the extracted pages
new_pdf.SaveToFile("/output/extracted_pages.pdf")
new_pdf.Close()
Here's the preview of the resulting file: 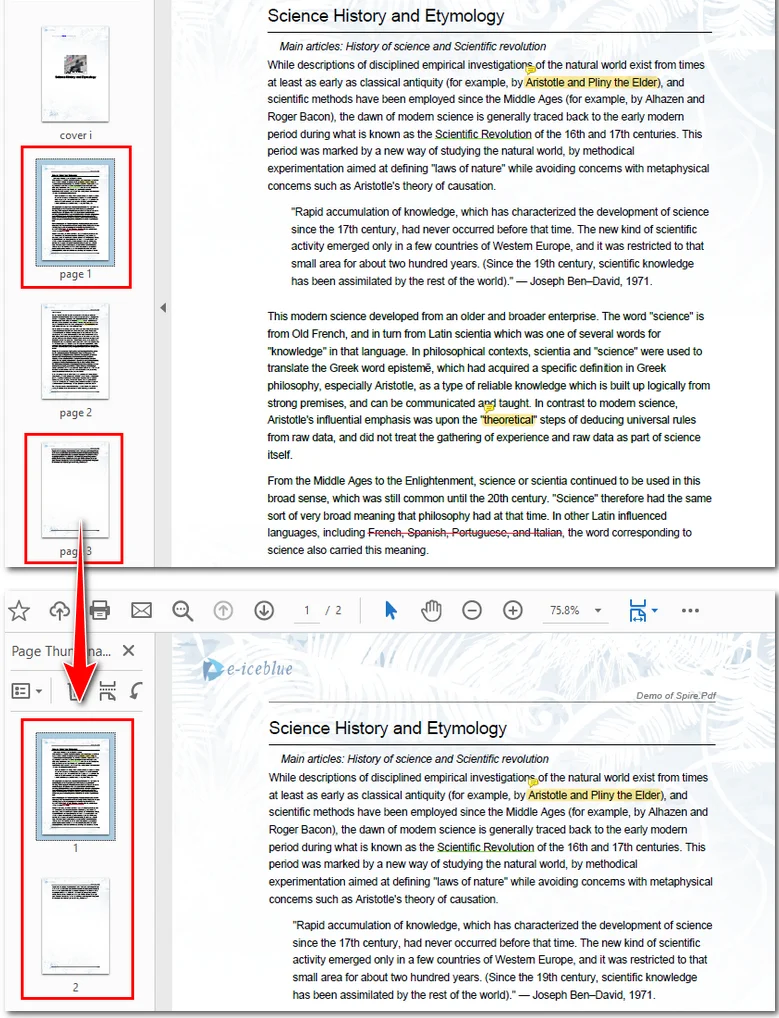
If you need to extract a large number of pages, another option is to delete the unnecessary pages instead. This approach can be just as effective when working with PDFs in Python.
The Conclusion
Whether you’re extracting a single page or managing multiple PDFs, choosing the right tool can save you a lot of time. If you prefer a more flexible and code-based solution, Free Spire.PDF for Python offers a reliable way to extract, edit, or organize PDF files efficiently. You can download it for free and explore more features on the official website.
ALSO READ