
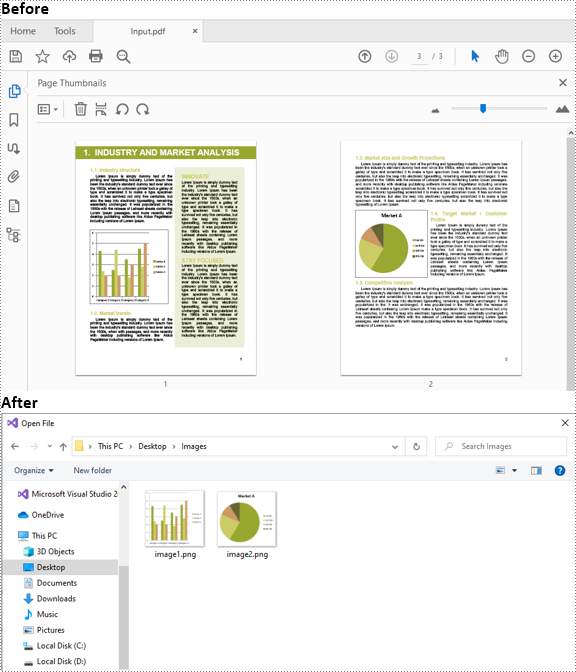
Images are often used in PDF documents to present information in an easily understandable manner. In certain cases, you may need to extract images from PDF documents. For example, when you want to use a chart image from a PDF report in a presentation or another document. This article will demonstrate how to extract images from PDF in C# and VB.NET using Spire.PDF for .NET.
Install Spire.PDF for .NET
To begin with, you need to add the DLL files included in the Spire.PDF for.NET package as references in your .NET project. The DLL files can be either downloaded from this link or installed via NuGet.
PM> Install-Package Spire.PDF
Extract Images from PDF in C# and VB.NET
The following are the main steps to extract images from a PDF document using Spire.PDF for .NET:
- Create a PdfDocument object.
- Load a PDF document using PdfDocument.LoadFromFile() method.
- Loop through all the pages in the document.
- Extract images from each page using PdfPageBase.ExtractImages() method and save them to a specified file path.
- C#
- VB.NET
using Spire.Pdf;
using System.Drawing;
namespace ExtractImages
{
class Program
{
static void Main(string[] args)
{
//Create a PdfDocument instance
PdfDocument pdf = new PdfDocument();
//Load a PDF document
pdf.LoadFromFile("Input.pdf");
int i = 1;
//Loop through all pages in the document
foreach (PdfPageBase page in pdf.Pages)
{
//Extract images from each page and save them to a specified file path
foreach (Image image in page.ExtractImages())
{
image.Save(@"C:/Users/Administrator/Desktop/Images/" + "image" + i + ".png", System.Drawing.Imaging.ImageFormat.Png);
i++;
}
}
}
}
}
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
