Python: Find and Highlight Text in Word
The text highlighting feature in MS Word allows users to easily navigate and search for specific sections or content. By highlighting key paragraphs or keywords, users can quickly locate the desired information within the document. This feature is particularly useful when dealing with large documents, as it not only saves time but also minimizes the frustration associated with manual searching, enabling users to focus on the content that truly matters. In this article, we will demonstrate how to find and highlight text in a Word document in Python using Spire.Doc for Python.
- Find and Highlight All Instances of a Specified Text in Word in Python
- Find and Highlight the First Instance of a Specified Text in Word in Python
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows
Find and Highlight All Instances of a Specified Text in Word in Python
You can use the Document.FindAllString() method provided by Spire.Doc for Python to find all instances of a specified text in a Word document. Then you can loop through these instances and highlight each of them with a bright color using TextRange.CharacterFormat.HighlightColor property. The detailed steps are as follows.
- Create an object of the Document class.
- Load a Word document using Document.LoadFromFile() method.
- Find all instances of a specific text in the document using Document.FindAllString() method.
- Loop through each found instance, and get it as a single text range using TextSelection.GetAsOneRange() method, then highlight the text range with color using TextRange.CharacterFormat.HighlightColor property.
- Save the resulting document using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Specify the input and output file paths
inputFile = "Sample.docx"
outputFile = "HighlightAllInstances.docx"
# Create an object of the Document class
document = Document()
# Load a Word document
document.LoadFromFile(inputFile)
# Find all instances of a specific text
textSelections = document.FindAllString("Spire.Doc", False, True)
# Loop through all the instances
for selection in textSelections:
# Get the current instance as a single text range
textRange = selection.GetAsOneRange()
# Highlight the text range with a color
textRange.CharacterFormat.HighlightColor = Color.get_Yellow()
# Save the resulting document
document.SaveToFile(outputFile, FileFormat.Docx2016)
document.Close()

Find and Highlight the First Instance of a Specified Text in Word in Python
You can use the Document.FindString() method to find only the first instance of a specified text and then set a highlight color for it using TextRange.CharacterFormat.HighlightColor property. The detailed steps are as follows.
- Create an object of the Document class.
- Load a Word document using Document.LoadFromFile() method.
- Find the first instance of a specific text using Document.FindString() method.
- Get the instance as a single text range using TextSelection.GetAsOneRange() method, and then highlight the text range with color using TextRange.CharacterFormat.HighlightColor property.
- Save the result document using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Specify the input and output file paths
inputFile = "Sample.docx"
outputFile = "HighlightTheFirstInstance.docx"
# Create an object of the Document class
document = Document()
# Load a Word document
document.LoadFromFile(inputFile)
# Find the first instance of a specific text
textSelection = document.FindString("Spire.Doc", False, True)
# Get the instance as a single text range
textRange = textSelection.GetAsOneRange()
# Highlight the text range with a color
textRange.CharacterFormat.HighlightColor = Color.get_Yellow()
# Save the resulting document
document.SaveToFile(outputFile, FileFormat.Docx2016)
document.Close()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Create or Edit Tables in PowerPoint Presentations
A table is a structured way of organizing and presenting data in rows and columns. It usually consists of horizontal rows and vertical columns, and each intersection can contain text, numbers, or other types of data. By inserting a table into a presentation, users can create or display structured data on slides to make the content more organized. In addition, compared to text forms, tabular data can be more intuitive to show the differences between data, which helps readers understand more, thus enhancing the professionalism and readability of the presentation. This article is going to show how to use Spire.Presentation for Python to create or edit a table in a PowerPoint Presentation in Python programs.
- Insert Tables into PowerPoint Presentations in Python
- Edit Tables in PowerPoint Presentations in Python
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.Presentation
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Presentation for Python on Windows
Insert Tables into PowerPoint Presentations in Python
Spire.Presentation for Python provides the Presentation.Slides[].Shapes.AppendTable(x: float, y: float, widths: List[float], heights: List[float]) method to add a table to a PowerPoint presentation. The detailed steps are as follows.
- Create an object of Presentation class.
- Load a sample presentation from disk using Presentation.LoadFromFile() method.
- Define the dimensions of the table.
- Add a new table to the sample presentation by calling Presentation.Slides[].Shapes.AppendTable(x: float, y: float, widths: List[float], heights: List[float]) method.
- Define the table data as a two-dimensional string array.
- Loop through the arrays and fill each cell of the table with these data by ITable[columnIndex, rowIndex].TextFrame.Text property.
- Set font name and font size for these data.
- Set the alignment of the first row in the table to center.
- Apply a built-in style to the table using ITable.StylePreset property.
- Save the result file using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
import math
from spire.presentation import *
inputFile = "C:/Users/Administrator/Desktop/Sample.pptx"
outputFile = "C:/Users/Administrator/Desktop/CreateTable.pptx"
#Create an object of Presentation class
presentation = Presentation()
#Load a sample presentation from disk
presentation.LoadFromFile(inputFile)
#Define the dimensions of the table
widths = [100, 100, 150, 100, 100]
heights = [15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15, 15]
#Add a new table to this presentation
left = math.trunc(presentation.SlideSize.Size.Width / float(2)) - 275
table = presentation.Slides[0].Shapes.AppendTable(left, 90, widths, heights)
#Define the table data as a two-dimensional string array
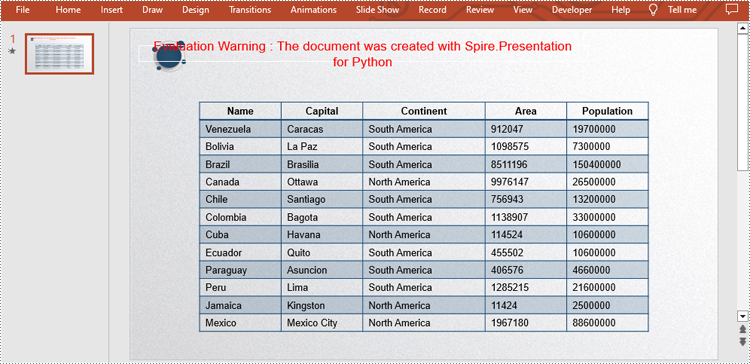
dataStr = [["Name", "Capital", "Continent", "Area", "Population"],
["Venezuela", "Caracas", "South America", "912047", "19700000"],
["Bolivia", "La Paz", "South America", "1098575", "7300000"],
["Brazil", "Brasilia", "South America", "8511196", "150400000"],
["Canada", "Ottawa", "North America", "9976147", "26500000"],
["Chile", "Santiago", "South America", "756943", "13200000"],
["Colombia", "Bagota", "South America", "1138907", "33000000"],
["Cuba", "Havana", "North America", "114524", "10600000"],
["Ecuador", "Quito", "South America", "455502", "10600000"],
["Paraguay", "Asuncion", "South America", "406576", "4660000"],
["Peru", "Lima", "South America", "1285215", "21600000"],
["Jamaica", "Kingston", "North America", "11424", "2500000"],
["Mexico", "Mexico City", "North America", "1967180", "88600000"]]
#Loop through the arrays
for i in range(0, 13):
for j in range(0, 5):
#Fill each cell of the table with these data
table[j,i].TextFrame.Text = dataStr[i][j]
#Set font name and font size
table[j,i].TextFrame.Paragraphs[0].TextRanges[0].LatinFont = TextFont("Arial")
table[j,i].TextFrame.Paragraphs[0].TextRanges[0].FontHeight = 12
#Set the alignment of the first row in the table to center
for i in range(0, 5):
table[i,0].TextFrame.Paragraphs[0].Alignment = TextAlignmentType.Center
#Apply a style to the table
table.StylePreset = TableStylePreset.LightStyle3Accent1
#Save the result file
presentation.SaveToFile(outputFile, FileFormat.Pptx2010)
presentation.Dispose()
Edit Tables in PowerPoint Presentations in Python
You are also allowed to edit tables in the presentation as needed, such as replacing data, changing styles, highlighting data, and so on. Here are the detailed steps.
- Create an object of Presentation class.
- Load a sample presentation from disk using Presentation.LoadFromFile() method.
- Store the data used for replacement in a string.
- Loop through the shapes in the first slide, and determine if a certain shape is a table. If yes, convert it to an ITable object.
- Change the style of the table using ITable.StylePreset property.
- Replace the data in a specific cell range by using ITable[columnIndex, rowIndex].TextFrame.Text property.
- Highlight the new data using ITable[columnIndex, rowIndex].TextFrame.TextRange.HighlightColor.Color property.
- Save the result file using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
inputFile = "C:/Users/Administrator/Desktop/CreateTable.pptx"
outputFile = "C:/Users/Administrator/Desktop/EditTable.pptx"
#Create an object of Presentation class
presentation = Presentation()
#Load a sample presentation from disk
presentation.LoadFromFile(inputFile)
#Store the data used in replacement in a string
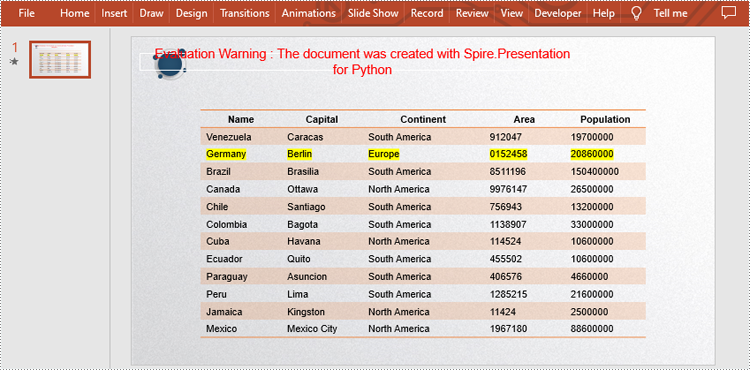
strs = ["Germany", "Berlin", "Europe", "0152458", "20860000"]
table = None
#Loop through shapes in the first slide to get the table
for shape in presentation.Slides[0].Shapes:
if isinstance(shape, ITable):
table = shape
#Change the style of the table
table.StylePreset = TableStylePreset.LightStyle1Accent2
for i, unusedItem in enumerate(table.ColumnsList):
#Replace the data in a specific cell range
table[i,2].TextFrame.Text = strs[i]
#Highlight the new data
table[i,2].TextFrame.TextRange.HighlightColor.Color = Color.get_Yellow()
#Save the result file
presentation.SaveToFile(outputFile, FileFormat.Pptx2013)
presentation.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Group or Ungroup Shapes in PowerPoint
Grouping shapes in PowerPoint can greatly simplify the shape editing process, especially when dealing with complex arrangements of shapes. It allows you to modify the entire group collectively, saving time and effort compared to adjusting each shape individually. This is particularly beneficial when you need to apply consistent formatting or positioning to a set of shapes. Ungrouping shapes provides increased flexibility and customization options. By ungrouping a set of grouped shapes, you regain individual control over each shape. This allows you to make specific modifications, resize or reposition individual shapes, and apply unique formatting or styling as needed. In this article, we will explain how to group and ungroup shapes in PowerPoint in Python using Spire.Presentation for Python.
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Presentation
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Presentation for Python on Windows
Group Shapes in PowerPoint in Python
Spire.Presentation for Python provides the ISlide.GroupShapes(shapeList: List) method to group two or more shapes on a specific slide. The detailed steps are as follows.
- Create an object of the Presentation class.
- Get the first slide using Presentation.Slides[0] property.
- Add two shapes to the slide using ISlide.Shapes.AppendShape() method.
- Create a list to store the shapes that need to be grouped.
- Add the two shapes to the list.
- Group the two shapes using ISlide.GroupShapes(shapeList: List) method.
- Save the result document using Presentation.SaveToFile() method.
- Python
from spire.presentation import *
# Create an object of the Presentation class
ppt = Presentation()
# Get the first slide
slide = ppt.Slides[0]
# Add two shapes to the slide
rectangle = slide.Shapes.AppendShape(ShapeType.Rectangle, RectangleF.FromLTRB (250, 180, 450, 220))
rectangle.Fill.FillType = FillFormatType.Solid
rectangle.Fill.SolidColor.KnownColor = KnownColors.SkyBlue
rectangle.Line.Width = 0.1
ribbon = slide.Shapes.AppendShape(ShapeType.Ribbon2, RectangleF.FromLTRB (290, 155, 410, 235))
ribbon.Fill.FillType = FillFormatType.Solid
ribbon.Fill.SolidColor.KnownColor = KnownColors.LightPink
ribbon.Line.Width = 0.1
# Add the two shapes to a list
shape_list = []
shape_list.append(rectangle)
shape_list.append(ribbon)
# Group the two shapes
slide.GroupShapes(shape_list)
# Save the resulting document
ppt.SaveToFile("GroupShapes.pptx", FileFormat.Pptx2013)
ppt.Dispose()

Ungroup Shapes in PowerPoint in Python
To ungroup the grouped shapes in a PowerPoint document, you need to iterate through all slides in the document and all shapes on each slide, find the grouped shapes and then ungroup them using ISlide.Ungroup(groupShape: GroupShape) method. The detailed steps are as follows.
- Create an object of the Presentation class.
- Load the PowerPoint document using Presentation.LoadFromFile() method.
- Iterate through all slides in the document.
- Iterate through all shapes on each slide.
- Check if the current shape is of GroupShape type. If the result is True, ungroup it using ISlide.Ungroup(groupShape: GroupShape) method.
- Save the result document using Presentation.SaveToFile() method.
- Python
from spire.presentation import *
# Create an object of the Presentation class
ppt = Presentation()
# Load a PowerPoint document
ppt.LoadFromFile("GroupShapes.pptx")
# Iterate through all slides in the document
for i in range(ppt.Slides.Count):
slide = ppt.Slides[i]
# Iterate through all shapes on each slide
for j in range(slide.Shapes.Count):
shape = slide.Shapes[j]
# Check if the shape is a grouped shape
if isinstance(shape, GroupShape):
groupShape = shape
# Ungroup the grouped shape
slide.Ungroup(groupShape)
# Save the resulting document
ppt.SaveToFile("UngroupShapes.pptx", FileFormat.Pptx2013)
ppt.Dispose()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Add Text or Image Watermarks to PowerPoint
Watermarks serve as subtle overlays placed on the slides, typically in the form of text or images, which can convey messages, copyright information, company logos, or other visual elements. By incorporating watermarks into your PowerPoint presentations, you can enhance professionalism, reinforce branding, and discourage unauthorized use or distribution of your material. In this article, you will learn how to add text or image watermarks to a PowerPoint document in Python using Spire.Presentation for Python.
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Presentation
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Presentation for Python on Windows
Add a Text Watermark to PowerPoint in Python
Unlike MS Word, PowerPoint does not have a built-in feature that allows to apply watermarks to each slide. However, you can add a shape with text or an image to mimic the watermark effect. A shape can be added to a slide using the ISlide.Shapes.AppendShape() method, and the text of the shape can be set through the IAutoShape.TextFrame.Text property. To prevent the shape from overlapping the existing content on the slide, you'd better send it to the bottom.
The following are the steps to add a text watermark to a slide using Spire.Presentation for Python.
- Create a Presentation object.
- Load a PowerPoint file using Presentation.LoadFromFile() method.
- Get a specific slide through Prentation.Slides[index] property.
- Add a shape to the slide using ISlide.Shapes.AppendShape() method.
- Add text to the shape through IAutoShape.TextFrame.Text property.
- Send the shape to back using IAutoShape.SetShapeArrange() method.
- Save the presentation to a PowerPoint file using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create a Presentation object
presentation = Presentation()
# Load a PowerPoint file
presentation.LoadFromFile("C:/Users/Administrator/Desktop/input.pptx")
# Define a rectangle
left = (presentation.SlideSize.Size.Width - 350.0) / 2
top = (presentation.SlideSize.Size.Height - 110.0) / 2
rect = RectangleF(left, top, 350.0, 110.0)
for i in range(0, presentation.Slides.Count):
# Add a rectangle shape to
shape = presentation.Slides[i].Shapes.AppendShape(
ShapeType.Rectangle, rect)
# Set the style of the shape
shape.Fill.FillType = FillFormatType.none
shape.ShapeStyle.LineColor.Color = Color.get_Transparent()
shape.Rotation = -35
shape.Locking.SelectionProtection = True
shape.Line.FillType = FillFormatType.none
# Add text to the shape
shape.TextFrame.Text = "CONFIDENTIAL"
textRange = shape.TextFrame.TextRange
# Set the style of the text range
textRange.Fill.FillType = FillFormatType.Solid
textRange.Fill.SolidColor.Color = Color.FromArgb(120, Color.get_Black().R, Color.get_HotPink().G, Color.get_HotPink().B)
textRange.FontHeight = 45
textRange.LatinFont = TextFont("Times New Roman")
# Send the shape to back
shape.SetShapeArrange(ShapeArrange.SendToBack)
# Save to file
presentation.SaveToFile("output/TextWatermark.pptx", FileFormat.Pptx2010)
presentation.Dispose()

Add an Image Watermark to PowerPoint in Python
To add an image watermark, you need first to create a rectangle with the same size as an image. Then fill the shape with this image and place the shape at the center of a slide. To prevent the shape from overlapping the existing content on the slide, you need to send it to the bottom as well. The following are the steps to add an image watermark to a slide using Spire.Presentation for Python.
- Create a Presentation object.
- Load a PowerPoint file using Presentation.LoadFromFile() method.
- Get a specific slide through Prentation.Slides[index] property.
- Load an image using Presentation.Images.AppendStream() method.
- Add a shape that has the same size with the image to the slide using ISlide.Shapes.AppendShape() method.
- Fill the shape with the image through IAuotShape.Fill.PictureFill.Picture.EmbedImage property.
- Send the shape to back using IAutoShape.SetShapeArrange() method.
- Save the presentation to a PowerPoint file using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
# Create a Presentation object
presentation = Presentation()
# Load a PowerPoint file
presentation.LoadFromFile("C:/Users/Administrator/Desktop/input.pptx")
# Load an image
stream = Stream("C:/Users/Administrator/Desktop/logo.png")
image = presentation.Images.AppendStream(stream)
stream.Close()
# Get width and height of the image
width = (float)(image.Width)
height = (float)(image.Height)
#
slideSize = presentation.SlideSize.Size
# Loop through the slides in the presentation
for i in range(0, presentation.Slides.Count):
# Get a specific slide
slide = presentation.Slides[i]
# Add a shape to slide
shape = slide.Shapes.AppendShape(ShapeType.Rectangle, RectangleF((slideSize.Width - width )/2, (slideSize.Height - height)/2, width, height))
# Fill the shape with image
shape.Line.FillType = FillFormatType.none
shape.Locking.SelectionProtection = True
shape.Fill.FillType = FillFormatType.Picture
shape.Fill.PictureFill.FillType = PictureFillType.Stretch
shape.Fill.PictureFill.Picture.EmbedImage = image
# Send the shape to back
shape.SetShapeArrange(ShapeArrange.SendToBack)
# Save to file
presentation.SaveToFile("output/ImageWatermark.pptx", FileFormat.Pptx2013)
presentation.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Add, Hide, or Remove Layers in PDF
Layers in PDF are similar to layers in image editing software, where different elements of a document can be organized and managed separately. Each layer can contain different content, such as text, images, graphics, or annotations, and can be shown or hidden independently. PDF layers are often used to control the visibility and positioning of specific elements within a document, making it easier to manage complex layouts, create dynamic designs, or control the display of information. In this article, you will learn how to add, hide, remove layers in a PDF document in Python using Spire.PDF for Python.
- Add a Layer to PDF in Python
- Set Visibility of a Layer in PDF in Python
- Remove a Layer from PDF in Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Add a Layer to PDF in Python
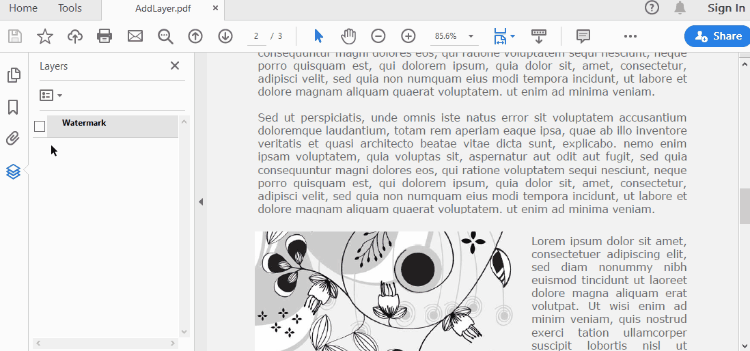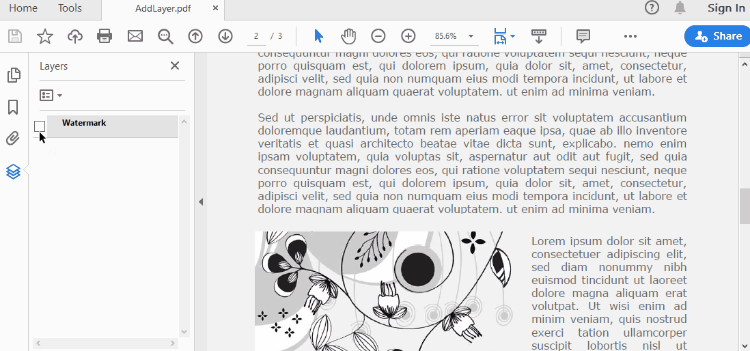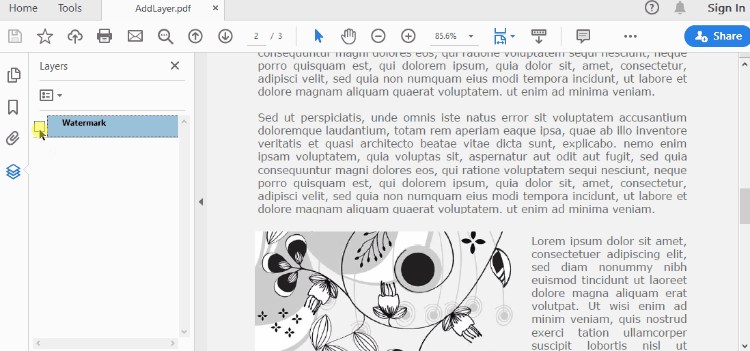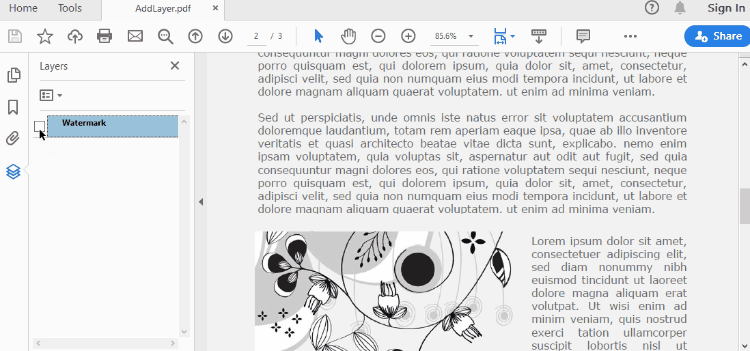
A layer can be added to a PDF document using the Document.Layers.AddLayer() method. After the layer object is created, you can draw text, images, fields, or other elements on it to form its appearance. The detailed steps to add a layer to PDF using Spire.PDF for Java are as follows.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Create a layer using Document.Layers.AddLayer() method.
- Get a specific page through PdfDocument.Pages[index] property.
- Create a canvas for the layer based on the page using PdfLayer.CreateGraphics() method.
- Draw text on the canvas using PdfCanvas.DrawString() method.
- Save the document to a different PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
def AddLayerWatermark(doc):
# Create a layer named "Watermark"
layer = doc.Layers.AddLayer("Watermark")
# Create a font
font = PdfTrueTypeFont("Bodoni MT Black", 50.0, 1, True)
# Specify watermark text
watermarkText = "DO NOT COPY"
# Get text size
fontSize = font.MeasureString(watermarkText)
# Get page count
pageCount = doc.Pages.Count
# Loop through the pages
for i in range(0, pageCount):
# Get a specific page
page = doc.Pages[i]
# Create canvas for layer
canvas = layer.CreateGraphics(page.Canvas)
# Draw sting on the graphics
canvas.DrawString(watermarkText, font, PdfBrushes.get_Gray(), (canvas.Size.Width - fontSize.Width)/2, (canvas.Size.Height - fontSize.Height)/2 )
# Create a PdfDocument instance
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\input.pdf")
# Invoke AddLayerWatermark method to add a layer
AddLayerWatermark(doc)
# Save to file
doc.SaveToFile("output/AddLayer.pdf", FileFormat.PDF)
doc.Close()
Set Visibility of a Layer in PDF in Python
To control the visibility of layers in a PDF document, you can use the PdfDocument.Layers[index].Visibility property. Set it to off to hide a layer, or set it to on to unhide a layer. The detailed steps are as follows.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Set the visibility of a certain layer through Document.Layers[index].Visibility property.
- Save the document to a different PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument instance
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Layer.pdf")
# Hide a layer by setting the visibility to off
doc.Layers[0].Visibility = PdfVisibility.Off
# Save to file
doc.SaveToFile("output/HideLayer.pdf", FileFormat.PDF)
doc.Close()
Remove a Layer from PDF in Python
If a layer is no more wanted, you can remove it using the PdfDocument.Layers.RmoveLayer() method. The following are the detailed steps.
- Create a PdfDocument object.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get a specific layer through PdfDocument.Layers[index] property.
- Remove the layer from the document using PdfDcument.Layers.RemoveLayer(PdfLayer.Name) method.
- Save the document to a different PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument instance
doc = PdfDocument()
# Load a PDF file
doc.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Layer.pdf")
# Delete the specific layer
doc.Layers.RemoveLayer(doc.Layers[0].Name)
# Save to file
doc.SaveToFile("output/RemoveLayer.pdf", FileFormat.PDF)
doc.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.XLS for Python 13.11.1 adds new methods
We are excited to announce the release of Spire.XLS for Python 13.11.1. This version adds IPivotTableOptions.ReportLayout get/set methods and ConverterSetting.ToImageWithoutMargins get/set methods. Besides, a lot of known issues are successfully fixed in this version, such as the issue that it threw an exception when initializing IOleObjects. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | - | Adds IPivotTableOptions.ReportLayout get/set methods. |
| New feature | - | Adds ConverterSetting.ToImageWithoutMargins get/set methods. |
| Bug | - | Fixes the issue that it threw an exception when the result of executing getFormula() method and getFormulaStringValue() method under XlsRange was null. |
| Bug | - | Fixes the issue that it threw an exception when executing the Workbook.IsPasswordProtected() method. |
| Bug | - | Fixes the issue that it threw an exception when executing IChartErrorBars.Border. |
| Bug | - | Fixes the issue that it threw an exception when executing XlsRange.Hyperlinks, XlsRange.Borders, XlsRange.RichText, XlsShape.Format3D, and XlsShape.LinkedCell. |
| Bug | - | Fix the issue that it threw an exception when executing ChartCategoryAxis.MajorGridLines and ChartCategoryAxis.MinorGridLines. |
| Bug | - | Fixes the issue that it threw an exception when executing ChartSerieDataFormat.AreaProperties. |
| Bug | - | Fixes the issue that it threw an exception when initializing PivotCalculatedFieldsCollection. |
| Bug | - | Fixes the issue that it threw an exception when executing PivotConditionalFormatCollection.AddPivotConditionalFormat. |
| Bug | - | Fixes the issue that it threw an exception when executing XlsChartLegendEntry.TextArea. |
| Bug | - | Fixes the issue that it threw an exception when initializing XlsChartCollection. |
| Bug | - | Fixes the issue that it threw an exception when executing XlsPivotTable.CalculatedFields, XlsPivotTable.PageFields, XlsPivotTable.RowFields, and XlsPivotTable.ColumnFields. |
| Bug | - | Fixes the issue that it threw an exception when initializing IOleObjects. |
| Bug | - | Fixes the issue that it threw an exception when executing RichTextObject.GetFont. |
| Bug | - | Fixes the issue that it threw an exception when executing XlsHyperLinksCollection.get_Item, XlsHyperLinksCollection.Add. |
| Bug | - | Fixes the issue that it threw an exception when initializing XlsPivotTablesCollection. |
| Bug | - | Fixes the issue that it threw an exception when initializing XlsWorksheetConditionalFormats. |
| Bug | - | Fixes the issue that it threw an exception when executing Worksheet.RemovePicture. |
| Bug | - | Fixes the issue that it threw an exception when executing XlsConditionalFormat. |
| Bug | - | Fixes the issue that it threw an exception when executing XlsValidationWrapper.Values. |
| Bug | - | Fixes the issue that the header image was displayed in complete black color. |
Python: Find and Highlight Text in PDF
Highlighting important text with vibrant colors is a commonly employed method for navigating and emphasizing content in PDF documents. Particularly in lengthy PDFs, emphasizing key information aids readers swiftly comprehending the document content, thereby enhancing reading efficiency. Utilizing Python programs enables document creators to effortlessly and expeditiously execute the highlighting process. This article will explain how to use Spire.PDF for Python to find and highlight text in PDF documents with Python programs.
- Find and Highlight Specific Text in PDF with Python
- Find and Highlight Text in a Specified PDF Page Area with Python
- Find and Highlight Text in PDF using Regular Expression with Python
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Find and Highlight Specific Text in PDF with Python
Spire.PDF for Python enables developers to find all occurrences of specific text on a page with PdfPageBase.FindText() method and apply highlight color to an occurrence with ApplyHighLight() method. Below is an example of using Spire.PDF for Python to highlight all occurrence of specific text:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Loop through the pages in the document.
- Get a page using PdfDocument.Pages.get_Item() method.
- Find all occurrences of specific text on the page using PdfPageBase.FindText() method.
- Loop through the occurrences and apply a highlight color to each occurrence using ApplyHighLight() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
from spire.pdf.common import*
# Create an object of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Loop through the pages in the PDF document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Find all occurrences of specific text on the page
result = page.FindText("cloud server", TextFindParameter.IgnoreCase).Finds
# Highlight all the occurrences
for text in result:
text.ApplyHighLight(Color.get_Cyan())
# Save the document
pdf.SaveToFile("output/FindHighlight.pdf")
pdf.Close()

Find and Highlight Text in a Specified PDF Page Area with Python
In addition to finding and highlighting specified text on the entire PDF page, Spire.PDF for Python also supports finding and highlighting specified text in specified areas on the page by passing a RectangleF instance as parameter to the PdfPageBase.FindText() method. The detailed steps are as follows:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Get the first page of the document using PdfDocument.Pages.get_Item() method.
- Define a rectangular area.
- Find all occurrences of specific text in the specified rectangular area on the first page using PdfPageBase.FindText() method.
- Loop through the occurrences and apply a highlight color to each occurrence using ApplyHighLight() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create an objetc of PdfDocument and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Get a page
pdfPageBase = pdf.Pages.get_Item(0)
# Define a rectangular area
rctg = RectangleF(0.0, 0.0, pdfPageBase.ActualSize.Width, 300.0)
# Find all the occurrences of specified text in the rectangular area
findCollection = pdfPageBase.FindText(rctg,"cloud server",TextFindParameter.IgnoreCase)
# Find text in the rectangle
for find in findCollection.Finds:
#Highlight searched text
find.ApplyHighLight(Color.get_Green())
# Save the document
pdf.SaveToFile("output/FindHighlightArea.pdf")
pdf.Close()

Find and Highlight Text in PDF using Regular Expression with Python
Sometimes the text that needs to be highlighted is not exactly the same words. In this case, the use of regular expressions allows more flexibility in text search. By passing TextFindParameter.Regex as parameter to the PdfPageBase.FindText() method, we can find text using regular expression in PDF documents. The detailed steps are as follows:
- Create an object of PdfDocument class and load a PDF document using PdfDocument.LoadFromFile() method.
- Specify the regular expression.
- Get a page using PdfDocument.Pages.get_Item() method.
- Find matched text with the regular expression on the page using PdfPageBase.FindText() method.
- Loop through the matched text and apply Highlight color to the text using ApplyHighLight() method.
- Save the document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf import *
from spire.pdf.common import*
# Create an object of PdfDocument class and load a PDF document
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Specify the regular expression that matches two words after *
regex = "\\*(\\w+\\s+\\w+)"
# Get the second page
page = pdf.Pages.get_Item(1)
# Find matched text on the page using regular expression
result = page.FindText(regex, TextFindParameter.Regex)
# Highlight the matched text
for text in result.Finds:
text.ApplyHighLight(Color.get_DeepPink())
# Save the document
pdf.SaveToFile("output/FindHighlightRegex.pdf")

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Apply Different Fonts in PDF
The use of appropriate fonts in PDF can greatly improve the overall readability and aesthetics of the document. In addition to the commonly used standard fonts, sometimes you may also need to embed private fonts. In this article, you will learn how to use different fonts in PDF in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Apply Different Fonts in a PDF Document in Python
Spire.PDF for Python supports standard PDF fonts, TrueType fonts, private fonts as well as CJK font. The following are the steps to draw text in PDF using these fonts.
- Create a PdfDocument instance.
- Add a page and then create a brush.
- Create an instance of the PdfFont class with a standard PDF font, and then use the PdfPageBase.getCanvas().drawString() method to draw text on the page with the standard font.
- Create an instance of the PdfTrueTypeFont class with a specified font, and then draw text on the page with the TrueType font.
- Load a private font and create an instance of the PdfTrueTypeFont class with it. Then draw text on the page with the private font.
- Create an instance of PdfCjkStandardFont class with a CJK font, and then draw text on the page with the CJK font.
- Save the result document using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
pdf = PdfDocument()
# Add a page
page = pdf.Pages.Add()
# Create a brush
brush = PdfBrushes.get_Black()
# Initialize y coordinate
y = 30.0
# Draw text using standard fonts
font = PdfFont(PdfFontFamily.Helvetica, 14.0)
page.Canvas.DrawString("Standard Font: Helvetica", font, brush, 0.0, y)
font = PdfFont(PdfFontFamily.Courier, 14.0)
page.Canvas.DrawString("Standard Font: Courier", font, brush, 0.0, (y := y + 16.0))
font = PdfFont(PdfFontFamily.TimesRoman, 14.0)
page.Canvas.DrawString("Standard Font: TimesRoman", font, brush, 0.0, (y := y + 16.0))
#Draw text using truetype font
trueTypeFont = PdfTrueTypeFont("Arial", 14.0, PdfFontStyle.Bold,True)
page.Canvas.DrawString("TrueType Font: Arial", trueTypeFont, brush, 0.0, (y := y + 30.0))
# Draw Arabic text from right to left
arabicText = "\u0627\u0644\u0630\u0647\u0627\u0628\u0021\u0020" + "\u0628\u062F\u0648\u0631\u0647\u0020\u062D\u0648\u0644\u0647\u0627\u0021\u0020" + "\u0627\u0644\u0630\u0647\u0627\u0628\u0021\u0020" + "\u0627\u0644\u0630\u0647\u0627\u0628\u0021\u0020" + "\u0627\u0644\u0630\u0647\u0627\u0628\u0021"
trueTypeFont = PdfTrueTypeFont("Arial", 14.0, PdfFontStyle.Bold,True)
rctg = RectangleF(PointF(0.0, (y := y + 16.0)), page.Canvas.ClientSize)
strformat = PdfStringFormat(PdfTextAlignment.Right)
strformat.RightToLeft = True
page.Canvas.DrawString(arabicText, trueTypeFont, brush, rctg, strformat)
# Draw text using private font
trueTypeFont = PdfTrueTypeFont("Khadija.ttf", 14.0)
page.Canvas.DrawString("Private Font - Khadija", trueTypeFont, brush, 0.0, (y := y + 30.0))
# Draw text using cjk fonts
cjkFont = PdfCjkStandardFont(PdfCjkFontFamily.MonotypeHeiMedium, 14.0)
page.Canvas.DrawString("How to say 'Font' in Chinese? \u5B57\u4F53", cjkFont, brush, 0.0, (y := y + 30.0))
cjkFont = PdfCjkStandardFont(PdfCjkFontFamily.HanyangSystemsGothicMedium, 14.0)
page.Canvas.DrawString("How to say 'Font' in Japanese? \u30D5\u30A9\u30F3\u30C8", cjkFont, brush, 0.0, (y := y + 16.0))
cjkFont = PdfCjkStandardFont(PdfCjkFontFamily.HanyangSystemsShinMyeongJoMedium, 14.0)
page.Canvas.DrawString("How to say 'Font' in Korean? \uAE00\uAF34", cjkFont, brush, 0.0, (y := y + 16.0))
#Save the result document
pdf.SaveToFile("Font.pdf")
pdf.Close()
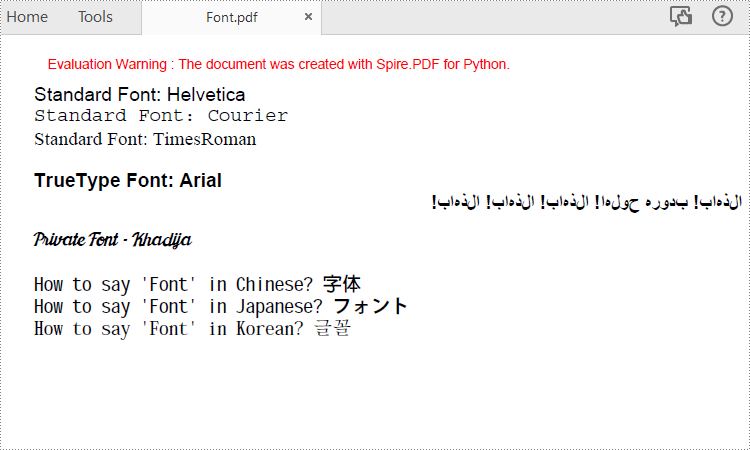
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Convert HTML to Word
While HTML is designed for online viewing, Word documents are commonly used for printing and physical documentation. Converting HTML to Word ensures that the content is optimized for printing, allowing for accurate page breaks, headers, footers, and other necessary elements for professional documentation purposes. In this article, we will explain how to convert HTML to Word in Python using Spire.Doc for Python.
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip commands.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows
Convert an HTML File to Word with Python
You can easily convert an HTML file to Word format by using the Document.SaveToFile() method provided by Spire.Doc for Python. The detailed steps are as follows.
- Create an object of the Document class.
- Load an HTML file using Document.LoadFromFile() method.
- Save the HTML file to Word format using Document.SaveToFile() method.
- Python
from spire.doc import * from spire.doc.common import * # Specify the input and output file paths inputFile = "Input.html" outputFile = "HtmlToWord.docx" # Create an object of the Document class document = Document() # Load an HTML file document.LoadFromFile(inputFile, FileFormat.Html, XHTMLValidationType.none) # Save the HTML file to a .docx file document.SaveToFile(outputFile, FileFormat.Docx2016) document.Close()

Convert an HTML String to Word with Python
To convert an HTML string to Word, you can use the Paragraph.AppendHTML() method. The detailed steps are as follows.
- Create an object of the Document class.
- Add a section to the document using Document.AddSection() method.
- Add a paragraph to the section using Section.AddParagraph() method.
- Append an HTML string to the paragraph using Paragraph.AppendHTML() method.
- Save the result document using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Specify the output file path
outputFile = "HtmlStringToWord.docx"
# Create an object of the Document class
document = Document()
# Add a section to the document
sec = document.AddSection()
# Add a paragraph to the section
paragraph = sec.AddParagraph()
# Specify the HTML string
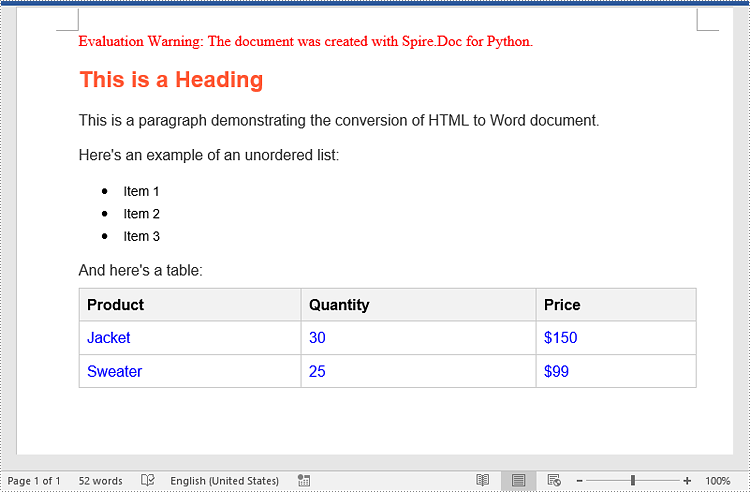
htmlString = """
<html>
<head>
<title>HTML to Word Example</title>
<style>
body {
font-family: Arial, sans-serif;
}
h1 {
color: #FF5733;
font-size: 24px;
margin-bottom: 20px;
}
p {
color: #333333;
font-size: 16px;
margin-bottom: 10px;
}
ul {
list-style-type: disc;
margin-left: 20px;
margin-bottom: 15px;
}
li {
font-size: 14px;
margin-bottom: 5px;
}
table {
border-collapse: collapse;
width: 100%;
margin-bottom: 20px;
}
th, td {
border: 1px solid #CCCCCC;
padding: 8px;
text-align: left;
}
th {
background-color: #F2F2F2;
font-weight: bold;
}
td {
color: #0000FF;
}
</style>
</head>
<body>
<h1>This is a Heading</h1>
<p>This is a paragraph demonstrating the conversion of HTML to Word document.</p>
<p>Here's an example of an unordered list:</p>
<ul>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
<p>And here's a table:</p>
<table>
<tr>
<th>Product</th>
<th>Quantity</th>
<th>Price</th>
</tr>
<tr>
<td>Jacket</td>
<td>30</td>
<td>$150</td>
</tr>
<tr>
<td>Sweater</td>
<td>25</td>
<td>$99</td>
</tr>
</table>
</body>
</html>
"""
# Append the HTML string to the paragraph
paragraph.AppendHTML(htmlString)
# Save the result document
document.SaveToFile(outputFile, FileFormat.Docx2016)
document.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Add Hyperlinks to PowerPoint Presentations
A hyperlink is a clickable element, usually embedded in text or an image. It can direct users from their current location to a specific location on another web page or document. By adding hyperlinks in PowerPoint presentations, users can easily visit other related pages or slides while presenting slides. In this article, we will demonstrate how to add hyperlinks to PowerPoint presentations in Python using Spire.Presentation for Python.
Install Spire.Presentation for Python
This scenario requires Spire.Presentation for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.Presentation
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Presentation for Python on Windows
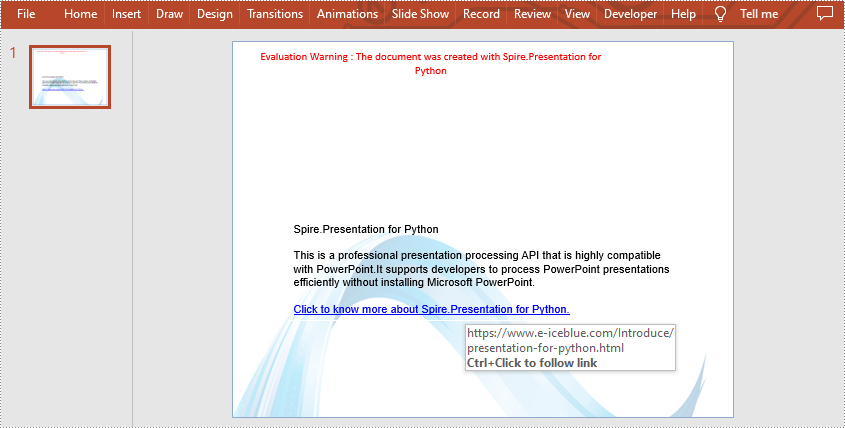
Add Hyperlink to Text on Slide in Python
Spire.Presentation for Python allows users to insert hyperlinks to text on slides easily by using TextRange.ClickAction.Address property. The following are detailed steps.
- Create a new PowerPoint presentation.
- Set the background for the first slide of the presentation by using Presentation.Slides[].Shapes.AppendEmbedImageByPath() method.
- Add a new shape to this slide using Presentation.Slides[].Shapes.AppendShape() method.
- Add some paragraphs to it by calling TextParagraph.TextRanges.Append() method.
- Create another TextRange instance to represent a text range and set link address for it by TextRange.ClickAction.Address property.
- Set the font for these paragraphs.
- Save the result file using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
import math
outputFile = "C:/Users/Administrator/Desktop/AddHyperlinkToText.pptx"
#Create a new PowerPoint presentation
presentation = Presentation()
#Set the background for the first slide
ImageFile = "C:/Users/Administrator/Desktop/background.png"
rect = RectangleF.FromLTRB (0, 0, presentation.SlideSize.Size.Width, presentation.SlideSize.Size.Height)
presentation.Slides[0].Shapes.AppendEmbedImageByPath (ShapeType.Rectangle, ImageFile, rect)
#Add a new shape to the first slide
shape = presentation.Slides[0].Shapes.AppendShape(ShapeType.Rectangle, RectangleF.FromLTRB (80, 250, 650, 400))
shape.Fill.FillType = FillFormatType.none
shape.ShapeStyle.LineColor.Color = Color.get_White()
#Add some paragraphs to the shape
para1 = TextParagraph()
tr = TextRange("Spire.Presentation for Python")
tr.Fill.FillType = FillFormatType.Solid
tr.Fill.SolidColor.Color = Color.get_Black()
para1.TextRanges.Append(tr)
para1.Alignment = TextAlignmentType.Left
shape.TextFrame.Paragraphs.Append(para1)
shape.TextFrame.Paragraphs.Append(TextParagraph())
para2 = TextParagraph()
tr1 = TextRange("This is a professional presentation processing API that is highly compatible with PowerPoint."
+"It supports developers to process PowerPoint presentations efficiently without installing Microsoft PowerPoint.")
tr1.Fill.FillType = FillFormatType.Solid
tr1.Fill.SolidColor.Color = Color.get_Black()
para2.TextRanges.Append(tr1)
shape.TextFrame.Paragraphs.Append(para2)
shape.TextFrame.Paragraphs.Append(TextParagraph())
#Add text with a hyperlink
para3 = TextParagraph()
tr2 = TextRange("Click to know more about Spire.Presentation for Python.")
tr2.ClickAction.Address = "https://www.e-iceblue.com/Introduce/presentation-for-python.html"
para3.TextRanges.Append(tr2)
shape.TextFrame.Paragraphs.Append(para3)
shape.TextFrame.Paragraphs.Append(TextParagraph())
#Set the font for those paragraphs
for para in shape.TextFrame.Paragraphs:
if len(para.Text) != 0:
para.TextRanges[0].LatinFont = TextFont("Arial")
para.TextRanges[0].FontHeight = 16
#Save the result file
presentation.SaveToFile(outputFile, FileFormat.Pptx2010)
presentation.Dispose()
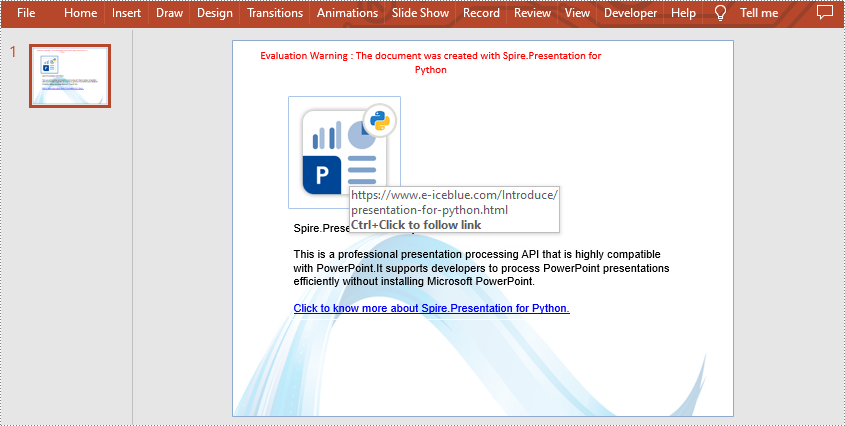
Add Hyperlink to Image on Slide in Python
Spire.Presentation for Python also supports adding a hyperlink to an image. You can create a hyperlink by ClickHyperlink class and then add it to the image using the IEmbedImage.Click property. The related steps are as follows.
- Create a new PowerPoint presentation.
- Load a PowerPoint file using Presentation.LoadFromFile() method.
- Get the first slide by using Presentation.Slides[] property.
- Add an image to this slide using ISlide.Shapes.AppendEmbedImageByPath() method.
- Create a ClickHyperlink object and append the hyperlink to the added image using IEmbedImage.Click property.
- Save the result file using Presentation.SaveToFile() method.
- Python
from spire.presentation.common import *
from spire.presentation import *
inputFile = "C:/Users/Administrator/Desktop/AddHyperlinkToText.pptx"
outputFile = "C:/Users/Administrator/Desktop/AddHyperlinkToImage.pptx"
#Create a new PowerPoint presentation
presentation = Presentation()
#Load a sample file from disk
presentation.LoadFromFile(inputFile)
#Get the first slide
slide = presentation.Slides[0]
#Add an image to this slide
rect = RectangleF.FromLTRB (80, 80, 240, 240)
image = slide.Shapes.AppendEmbedImageByPath (ShapeType.Rectangle, "image.png", rect)
#Add a hyperlink to the image
hyperlink = ClickHyperlink("https://www.e-iceblue.com/Introduce/presentation-for-python.html")
image.Click = hyperlink
#Save the result file
presentation.SaveToFile(outputFile, FileFormat.Pptx2013)
presentation.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.