Spire.Office for C++ 8.11.0 is released
We are delighted to announce the release of Spire.Office for C++ 8.11.0. This version adds support for the Linux platform. Spire.PDF for C++ supports the PdfMarker type. In addition, some known issues are fixed in this version. More details are listed below.
Here is a list of changes made in this release
Spire.PDF for C++
| Category | ID | Description |
| New feature | SPIREPDF-5945 | Supports the PdfMarker type.
intrusive_ptr<PdfDocument> doc = new PdfDocument(); intrusive_ptr<PdfNewPage> page = Object::Dynamic_cast<PdfNewPage>(doc->GetPages()->Add()); intrusive_ptr<PdfMarker> marker = new PdfMarker(PdfUnorderedMarkerStyle::CustomImage); marker->SetImage(PdfImage::FromFile(inputFile_Img.c_str())); std::wstring listContent = L"Data Structure\n"; listContent += L"Algorithm\n"; listContent += L"Computer Newworks\n"; listContent += L"Operating System\n"; listContent += L"C Programming\n"; listContent += L"Computer Organization and Architecture"; intrusive_ptr<PdfList> list = new PdfList(listContent.c_str()); list->SetIndent(2); list->SetTextIndent(4); list->SetMarker(marker); ((intrusive_ptr<PdfLayoutWidget>)list)->Draw(page, 100, 100); doc->SaveToFile(outputFile.c_str(), FileFormat::PDF); doc->Close(); |
| Bug | SPIREPDF-6052 | Fixes the issue that the first-level bookmark navigation function failed when performing linearized conversion of PDF documents. |
| Bug | SPIREPDF-6173 | Fixes the issue that the validation of signatures was incorrect. |
| Bug | SPIREPDF-6191 | Removes doc->GetXmpMetaData() method. |
| Bug | SPIREPDF-6242 | Fixes the issue that reading properties of PDF documents failed. |
| Bug | SPIREPDF-6257 | Fixes the issue that the program threw an exception System.InvalidCastException when converting PDF documents to XPS documents multiple times. |
| Bug | SPIREPDF-6270 | Fixes the issue that compressing PDF documents failed. |
| Bug | SPIREPDF-6344 | Fixes the issue that the program threw an exception System.TypeInitializationException when converting a PDF document to a PowerPoint document. |
Spire.PDF for C++ 9.11.0 supports the PdfMarker type
We are excited to announce the release of Spire.PDF for C++ 9.11.0. This version supports the PdfMarker type. It also enhances the conversion from PDF to XPS and PowerPoint files. Moreover, some known issues are fixed successfully in this version, such as the issue that compressing PDF documents failed. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPDF-5945 | Supports the PdfMarker type.
intrusive_ptr<PdfDocument> doc = new PdfDocument(); intrusive_ptr<PdfNewPage> page = Object::Dynamic_cast<PdfNewPage>(doc->GetPages()->Add()); intrusive_ptr<PdfMarker> marker = new PdfMarker(PdfUnorderedMarkerStyle::CustomImage); marker->SetImage(PdfImage::FromFile(inputFile_Img.c_str())); std::wstring listContent = L"Data Structure\n"; listContent += L"Algorithm\n"; listContent += L"Computer Newworks\n"; listContent += L"Operating System\n"; listContent += L"C Programming\n"; listContent += L"Computer Organization and Architecture"; intrusive_ptr<PdfList> list = new PdfList(listContent.c_str()); list->SetIndent(2); list->SetTextIndent(4); list->SetMarker(marker); ((intrusive_ptr<PdfLayoutWidget>)list)->Draw(page, 100, 100); doc->SaveToFile(outputFile.c_str(), FileFormat::PDF); doc->Close(); |
| Bug | SPIREPDF-6052 | Fixes the issue that the first-level bookmark navigation function failed when performing linearized conversion of PDF documents. |
| Bug | SPIREPDF-6173 | Fixes the issue that the validation of signatures was incorrect. |
| Bug | SPIREPDF-6191 | Removes doc->GetXmpMetaData() method. |
| Bug | SPIREPDF-6242 | Fixes the issue that reading properties of PDF documents failed. |
| Bug | SPIREPDF-6257 | Fixes the issue that the program threw an exception System.InvalidCastException when converting PDF documents to XPS documents multiple times. |
| Bug | SPIREPDF-6270 | Fixes the issue that compressing PDF documents failed. |
| Bug | SPIREPDF-6344 | Fixes the issue that the program threw an exception System.TypeInitializationException when converting a PDF document to a PowerPoint document. |
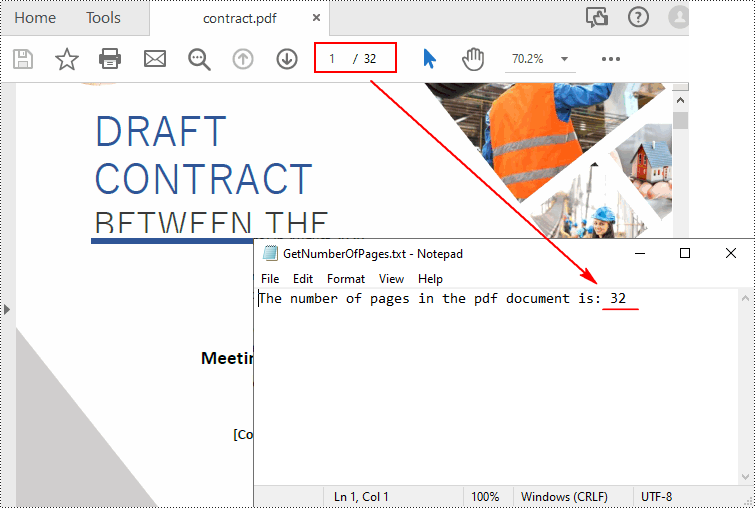
Python: Count the Number of Pages in a PDF File
To get the number of pages in a PDF file, you can open the file in a PDF viewer such as Adobe, which has a built-in page count feature. However, when there is a batch of PDF files, opening each file to check how many pages it contains is a time-consuming task. In this article, you will learn how to quicky count the number of pages in a PDF file through programming using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Count the Number of Pages in a PDF File in Python
Spire.PDF for Python offers the PdfDocument.Pages.Count property to quickly count the number of pages in a PDF file without opening it. The following are the detailed steps.
- Create a PdfDocument object.
- Load a sample PDF document using PdfDocument.LoadFromFile() method.
- Count the number of pages in the PDF document using PdfDocument.Pages.Count property.
- Write the result to a TXT file or print it out directly.
- Python
from spire.pdf.common import *
from spire.pdf import *
def AppendText(fname: str, text: str):
fp = open(fname, "w")
fp.write(text + "\n")
fp.close()
# Specify the input and output files
inputFile = "contract.pdf"
outputFile = "GetNumberOfPages.txt"
# Create a PdfDocument object
pdf = PdfDocument()
# Load a PDF document from disk
pdf.LoadFromFile(inputFile)
# Count the number of pages in the document
count = pdf.Pages.Count
# Print the result
print("Total Pages:", count)
# Write the result to a TXT file
AppendText(
outputFile, "The number of pages in the pdf document is: " + str(count))
pdf.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Add Hyperlinks to PDF
Hyperlinks in PDF are interactive elements that, when clicked, can jump to a specific location in the document, to an external website, or to other resources. By inserting hyperlinks in a PDF document, you can provide supplementary information and enhance the overall integrity of the document. This article will demonstrate how to add hyperlinks to PDF files in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
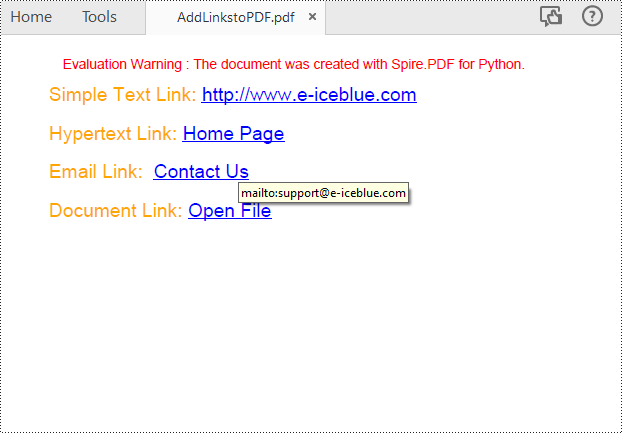
Add Hyperlinks to a PDF Document in Python
With Spire.PDF for Python, you can add web links, email links and file links to a PDF document. The following are the detailed steps:
- Create a pdf document and add a page to it.
- Specify a URL address and draw it directly on the page using PdfPageBase.Canvas.DrawString() method.
- Create a PdfTextWebLink object.
- Set the link's display text, URL address, and the font and brush used to draw it using properties of PdfTextWebLink class.
- Draw the link on the page using PdfTextWebLink.DrawTextWebLink() method.
- Create a PdfFileLinkAnnotation object and with a specified file.
- Add the file link to the page annotations using PdfPageBase.AnnotationsWidget.Add(PdfFileLinkAnnotation) method.
- Draw hypertext of the file link using PdfPageBase.Canvas.DrawString() method.
- Save the result file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument instance
pdf = PdfDocument()
# Add a page
page = pdf.Pages.Add()
# Initialize x, y coordinates
y = 30.0
x = 10.0
# Create true type fonts
font = PdfTrueTypeFont("Arial", 14.0,PdfFontStyle.Regular,True)
font1 = PdfTrueTypeFont("Arial", 14.0, PdfFontStyle.Underline,True)
# Add a simply link
label = "Simple Text Link: "
format = PdfStringFormat()
format.MeasureTrailingSpaces = True
page.Canvas.DrawString(label, font, PdfBrushes.get_Orange(), 0.0, y, format)
x = font.MeasureString(label, format).Width
url = "http://www.e-iceblue.com"
page.Canvas.DrawString(url, font1, PdfBrushes.get_Blue(), x, y)
y = y + 28
# Add a hypertext link
label = "Hypertext Link: "
page.Canvas.DrawString(label, font, PdfBrushes.get_Orange(), 0.0, y, format)
x = font.MeasureString(label, format).Width
webLink = PdfTextWebLink()
webLink.Text = "Home Page"
webLink.Url = url
webLink.Font = font1
webLink.Brush = PdfBrushes.get_Blue()
webLink.DrawTextWebLink(page.Canvas, PointF(x, y))
y = y + 28
# Add an Email link
label = "Email Link: "
page.Canvas.DrawString(label, font, PdfBrushes.get_Orange(), 0.0, y, format)
x = font.MeasureString(label, format).Width
link = PdfTextWebLink()
link.Text = "Contact Us"
link.Url = "mailto:support@e-iceblue.com"
link.Font = font1
link.Brush = PdfBrushes.get_Blue()
link.DrawTextWebLink(page.Canvas, PointF(x, y))
y = y + 28
# Add a file link
label = "Document Link: "
page.Canvas.DrawString(label, font, PdfBrushes.get_Orange(), 0.0, y, format)
x = font.MeasureString(label, format).Width
text = "Open File"
location = PointF(x, y)
size = font1.MeasureString(text)
linkBounds = RectangleF(location, size)
fileLink = PdfFileLinkAnnotation(linkBounds,"C:\\Users\\Administrator\\Desktop\\Report.xlsx")
fileLink.Border = PdfAnnotationBorder(0.0)
page.AnnotationsWidget.Add(fileLink)
page.Canvas.DrawString(text, font1, PdfBrushes.get_Blue(), x, y)
#Save the result pdf file
pdf.SaveToFile("AddLinkstoPDF.pdf")
pdf.Close()
Insert Hyperlinks into Existing Text in PDF in Python
Adding a hyperlink to existing text in a PDF document requires locating the text first. Once the location has been obtained, an object of PdfUriAnnotation class with the link can be created and added to the position. The following are the detailed steps:
- Create a PdfDocument instance.
- Load a PDF file using PdfDocument.LoadFromFile() method.
- Get the first page using PdfDocument.Pages property.
- Find all occurrences of the specified text on the page using PdfPageBase.FindText() method.
- Loop through all occurrences of the found text and create a PdfUriAnnotation instance based on the text bounds of each occurrence.
- Set the hyperlink URL, border, and border color using properties under PdfUriAnnotation class.
- Insert the hyperlink to the page annotations using PdfPageBase.AnnotationsWidget.Add(PdfUriAnnotation) method.
- Save the PDF file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument instance
pdf = PdfDocument()
# Load a PDF file
pdf.LoadFromFile("input.pdf")
# Get the first page
page = pdf.Pages[0]
# Find all occurrences of the specified text on the page
collection = page.FindText("big O notation", TextFindParameter.IgnoreCase)
# Loop through all occurrences of the specified text
for find in collection.Finds:
# Create a hyperlink annotation
uri = PdfUriAnnotation(find.Bounds)
# Set the URL of the hyperlink
uri.Uri = "https://en.wikipedia.org/wiki/Big_O_notation"
# Set the border of the hyperlink annotation
uri.Border = PdfAnnotationBorder(1.0)
# Set the color of the border
uri.Color = PdfRGBColor(Color.get_Blue())
# Add the hyperlink annotation to the page
page.AnnotationsWidget.Add(uri)
#Save the result file
pdf.SaveToFile("SearchTextAndAddHyperlink.pdf")
pdf.Close()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.Office for Java 8.11.3 is released
We are delighted to announce the release of Spire.Office for Java 8.11.3. In this version, Spire.XLS for Java supports retrieving comments from the Name Manager; Spire.PDF for Java enhances the conversion from PDF to Word documents and PPTX files; Spire.Presentation for Java enhances the conversion from slides to SVG. In addition, many known issues are fixed in this version. More details are listed below.
Here is a list of changes made in this release
Spire.XLS for Java
| Category | ID | Description |
| New feature | SPIREXLS-4919 | Supports retrieving comments from the Name Manager.
Workbook workbook = new Workbook();
workbook.loadFromFile(inputFile);
INameRanges nameManager = workbook.getNameRanges();
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < nameManager.getCount(); i++) {
XlsName name = (XlsName) nameManager.get(i);
stringBuilder.append("Name: " + name.getName() + ", Comment: " + name.getCommentValue() + "\r\n");
}
workbook.dispose();
|
| Bug | SPIREXLS-4911 | Improves the speed of converting Excel to PDF on Linux. |
| Bug | SPIREXLS-4860 | Fixes the issue that the page size setting failed after setting the setSheetFitToPage method when converting Excel to PDF. |
| Bug | SPIREXLS-4894 | Fixes the issue that removing pivot table borders failed. |
| Bug | SPIREXLS-4906 | Fixes the issue that text was reversed and cropped after converting Excel to PDF. |
| Bug | SPIREXLS-4923 | Fixes the issue that the program threw "Invalid ValidationAlertType" when reading an Excel file. |
| Bug | SPIREXLS-4924 | Fixes the issue that the program threw "Input string was not in the correct format" when reading an Excel file. |
| Bug | SPIREXLS-4966 | Fixes the issue that the application threw the "java.lang.NullPointerException" exception when converting worksheets to HTML documents. |
| Bug | SPIREXLS-4967 | Fixes the issue that excessive "0" characters occurred in the text content when converting Excel documents to HTML documents. |
| Bug | SPIREXLS-4968 | Fixes the issue that the cell content was partially lost when converting Excel to PDF after setting the cell to auto-fit row height. |
| Bug | SPIREXLS-4970 | Fixes the issue that incorrect content was obtained from merged cells. |
| Bug | SPIREXLS-4975 | Fixes the issue that incorrect results were returned by string searches. |
| Bug | SPIREXLS-4977 | Fixes the issue that the chart references were updated incorrectly when copying worksheets. |
| Bug | SPIREXLS-4990 | Fixes the issue that incorrect DisplayedText values were obtained. |
Spire.PDF for Java
| Category | ID | Description |
| Bug | SPIREPDF-5830 | Fixes the issue that extracting the contents of tables in PDF failed. |
| Bug | SPIREPDF-6315 | Fixes the issue that the content was drawn repeatedly when converting PDF to PPTX on Ubuntu system. |
| Bug | SPIREPDF-6323 | Fixes the issue that the program threw "No 'DCWGQU+CambriaMath' font found!" when converting PDF to Word on Linux system. |
| Bug | SPIREPDF-6359 | Fixes the issue that the binding direction of the cover was incorrect when creating a booklet. |
| Bug | SPIREPDF-6364 | Fixes the issue that the program threw "PDF file structure is not valid" exception when loading PDF. |
| Bug | SPIREPDF-6389 | Fixes the issue that the program threw "NullPointerException" when using the appendPage() method to merge PDF documents. |
Spire.Presentation for Java
| Category | ID | Description |
| Bug | SPIREPPT-2114 | Fixes the issue that the content was incorrect after converting slides to SVG. |
| Bug | SPIREPPT-2140 SPIREPPT-2373 |
Fixes the issue that the gradient background color was incorrect after converting slides to SVG. |
| Bug | SPIREPPT-2380 | Fixes the issue that the content became blurry after converting slides to SVG. |
| Bug | SPIREPPT-2381 | Fixes the issue that the "Indent Text When Overflow" setting was ineffective. |
| Bug | SPIREPPT-2383 | Fixes the issue that the underline of the inserted HTML text missed. |
| Bug | SPIREPPT-2386 | Fixes the issue where the "Resize Shape to Fit Text" setting was ineffective. |
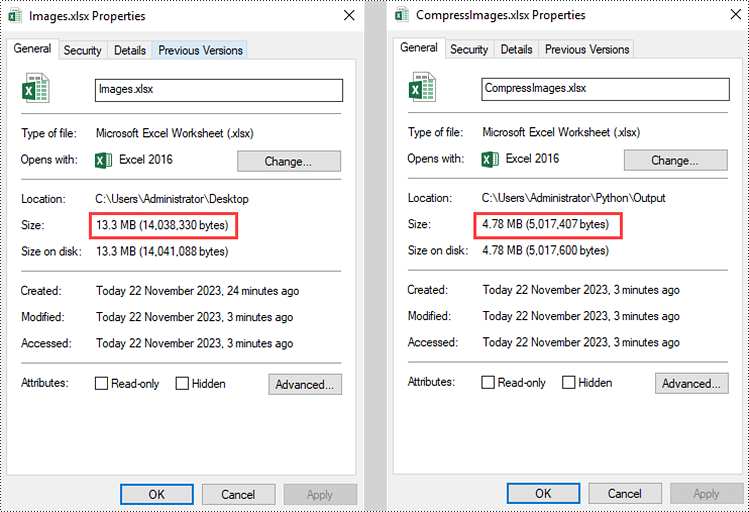
Python: Compress, Resize, or Move Images in Excel
Excel provides various options to compress, resize, or move images, allowing users to effectively manage and optimize their spreadsheets. By utilizing these features, you can significantly reduce file size, adjust image dimensions to fit within cells, and effortlessly reposition images to enhance the visual appeal of your Excel documents. This article introduces how to programmatically compress, resize or move images in an Excel document in Python using Spire.XLS for Python.
- Compress Images in an Excel Document in Python
- Resize an Image in an Excel Worksheet in Python
- Move an Image within the Same Worksheet in Python
- Move an Image from a Worksheet to Another in Python
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your Windows through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
Compress Images in an Excel Document in Python
To compress the quality of an image, Spire.XLS for Python offers the ExcelPicture.Compress() method. The following are the steps to compress images in an Excel document using Spire.XLS for Python.
- Create a Workbook object.
- Load an Excel file using Workbook.LoadFromFile() method.
- Iterate through the worksheets in the document, and get the images from a specific sheet through Worksheet.Pictures property.
- Get a specific image from the image collection and compress it using ExcelPicture.Compress() method.
- Save the workbook to a different Excel file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel document
workbook.LoadFromFile("C:/Users/Administrator/Desktop/Images.xlsx")
# Loop through the worksheets in the document
for sheet in workbook.Worksheets:
# Loop through the images in the worksheet
for picture in sheet.Pictures:
# Compress a specific image
picture.Compress(50)
# Save the file
workbook.SaveToFile("output/CompressImages.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Resize an Image in an Excel Worksheet in Python
The width and height of an image can be set or get through the ExcelPicture.Width property and the ExcelPicture.Height property. To resize an image in Excel, follow the steps below.
- Create a Workbook object.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet though Workbook.Worksheets[index] property.
- Get a specific image from the worksheet through Worksheet.Pictures[index] property.
- Reset the size of the image through ExcelPicture.Width property and ExcelPicture.Height property.
- Save the workbook to a different Excel file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load the Excel document
workbook.LoadFromFile("C:/Users/Administrator/Desktop/Image.xlsx")
# Get a specific worksheet
sheet = workbook.Worksheets[0]
# Get a specific picture from the worksheet
picture = sheet.Pictures[0]
# Resize the picture
picture.Width = (int)(picture.Width / 2)
picture.Height = (int)(picture.Height / 2)
# Save to file
workbook.SaveToFile("output/ResizeImage.xlsx", ExcelVersion.Version2016)
workbook.Dispose()

Move an Image within the Same Worksheet in Python
The start position of an image can be set or get through the ExcelPicture.TopRow property and the ExcelPicture.LetColumn property. To move an image within the same worksheet, follow the steps below.
- Create a Workbook object.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet though Workbook.Worksheets[index] property.
- Get a specific image from the worksheet through Worksheet.Pictures[index] property.
- Reset the position of the image in the worksheet through ExcelPicture.TopRow property and ExcelPicture.LeftColumn property.
- Save the workbook to a different Excel file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load the Excel document
workbook.LoadFromFile("C:/Users/Administrator/Desktop/Image.xlsx")
# Get a specific worksheet
sheet = workbook.Worksheets[0]
# Get a specific picture from the worksheet
picture = sheet.Pictures[0]
# Reset the position of the picture
picture.TopRow = 5
picture.LeftColumn = 6
# Save to file
workbook.SaveToFile("output/MoveImage.xlsx", ExcelVersion.Version2016)
workbook.Dispose()

Move an Image from a Worksheet to Another in Python
Besides moving images in the same worksheet, you can also move images in different worksheets of the workbook. First, you need to get the desired image from a worksheet and add it to a different worksheet using the Worksheet.Pictures.Add() method, and then delete the original image using the ExcelPicture.Remove() method. The detailed steps are as follows.
- Create a Workbook object.
- Load an Excel file using Workbook.LoadFromFile() method.
- Get a specific worksheet though Workbook.Worksheets[index] property.
- Get a specific image from the worksheet through Worksheet.Pictures[index] property.
- Get another worksheet though Workbook.Worksheets[index] property.
- Add the image to the target worksheet using Worksheet.Pictures.Add() method.
- Remove the image from the source worksheet using ExcelPicture.Remove() method.
- Save the workbook to a different Excel file using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load the Excel document
workbook.LoadFromFile("C:/Users/Administrator/Desktop/Image.xlsx")
# Get the first worksheet
sheet = workbook.Worksheets[0]
# Get the first picture from the worksheet
picture = sheet.Pictures[0]
# Get the second worksheet
sheet_two = workbook.Worksheets[1]
# Add the picture to the second worksheet
sheet_two.Pictures.Add(1, 1, picture.Picture)
# Remove the picture in the first worksheet
picture.Remove()
# Save to file
workbook.SaveToFile("output/MoveImage.xlsx", ExcelVersion.Version2016)
workbook.Dispose()

Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.XLS for Java 13.11.6 enhances the conversions from Excel to Html
We're pleased to announce the release of Spire.XLS for Java 13.11.6. This version mainly fixes some issues that occurred when converting Excel to Html/PDF and copying worksheets. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| Bug | SPIREXLS-4966 | Fixes the issue that the application threw the "java.lang.NullPointerException" exception when converting worksheets to HTML documents. |
| Bug | SPIREXLS-4967 | Fixes the issue that excessive "0" characters occurred in the text content when converting Excel documents to HTML documents. |
| Bug | SPIREXLS-4968 | Fixes the issue that the cell content was partially lost when converting Excel to PDF after setting the cell to auto-fit row height. |
| Bug | SPIREXLS-4970 | Fixes the issue that incorrect content was obtained from merged cells. |
| Bug | SPIREXLS-4975 | Fixes the issue that incorrect results were returned by string searches. |
| Bug | SPIREXLS-4977 | Fixes the issue that the chart references were updated incorrectly when copying worksheets. |
| Bug | SPIREXLS-4990 | Fixes the issue that incorrect DisplayedText values were obtained. |
Spire.XLS 13.11.4 enhances the conversion from Excel to HTML
We're pleased to announce the release of Spire.XLS 13.11.4. This version mainly fixes the issues occurring when convert Excel to HTML or PDF. In addition, some known issues are fixed, such as the function SHEET(A3) did not auto calculate, and the watermark was incorrect after copying a worksheet. More details are as follows.
Here is a list of changes made in this release
| Category | ID | Description |
| Bug | SPIREXLS-4876 | Fixed the issue that some cells were missing when convert Excel to HTML. |
| Bug | SPIREXLS-4880 | Fixed the issue that the font directory did not take effective when converting Excel to PDF. |
| Bug | SPIREXLS-4904 | Fixed the issue that the function SHEET(A3) did not auto calculate. |
| Bug | SPIREXLS-4922 | Fixed the problem that the encryption information obtained from a worksheet was incorrect. |
| Bug | SPIREXLS-4925 | Fixed the issue that the watermark was incorrect after copying a worksheet. |
| Bug | SPIREXLS-4931 | Fixed the issue that the pagination was incorrect when converting Excel to PDF. |
| Bug | SPIREXLS-4933 | Fixed the issue that the System.FormatException exception was thrown when loading an Excel document. |
| Bug | SPIREXLS-4942 | Fixed the issue that the parentheses were not recognized when converting Excel to images |
| Bug | SPIREXLS-4963 | Fixed the issue that some content got lost when copying a custom shape created by Excel 365 to another worksheet. |
Spire.Doc 11.11.8 publicizes the enumeration of Spire.Doc.Publics.Drawing.FontStyle
We are pleased to announce the release of Spire.Doc 11.11.8. This version publicizes the enumeration of Spire.Doc.Publics.Drawing.FontStyle. What's more, the namespace of the "FontStyle" in the "PrivateFontPath" structure has also been changed to "Spire.Doc.Publics.Drawing". More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | - | Publicizes the enumeration Spire.Doc.Publics.Drawing.FontStyle. |
| New feature | - | Changes the namespace of the "FontStyle" in the "PrivateFontPath" structure to "Spire.Doc.Publics.Drawing".
Instructions:
Changes the method "public PrivateFontPath(string fontName, System.Drawing.FontStyle fontStyle, string fontPath)" to "public PrivateFontPath(string fontName, Spire.Doc.Publics.Drawing.FontStyle fontStyle, string fontPath)". Changes the method "public PrivateFontPath(string fontName, System.Drawing.FontStyle fontStyle, string fontPath, bool useArabicConcatenationRules)" to "public PrivateFontPath(string fontName, Spire.Doc.Publics.Drawing.FontStyle fontStyle, string fontPath, bool useArabicConcatenationRules)". |
Spire.PDF for Java 9.11.3 enhances the conversion from PDF to Word and PowerPoint
We are delighted to announce the release of Spire.PDF for Java 9.11.3. This version enhances the conversion from PDF to Word documents and PPTX files. Besides, some known issues are fixed successfully in this version, such as the issue that extracting the contents of tables in PDF failed. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| Bug | SPIREPDF-5830 | Fixes the issue that extracting the contents of tables in PDF failed. |
| Bug | SPIREPDF-6315 | Fixes the issue that the content was drawn repeatedly when converting PDF to PPTX on Ubuntu system. |
| Bug | SPIREPDF-6323 | Fixes the issue that the program threw "No 'DCWGQU+CambriaMath' font found!" when converting PDF to Word on Linux system. |
| Bug | SPIREPDF-6359 | Fixes the issue that the binding direction of the cover was incorrect when creating a booklet. |
| Bug | SPIREPDF-6364 | Fixes the issue that the program threw "PDF file structure is not valid" exception when loading PDF. |
| Bug | SPIREPDF-6389 | Fixes the issue that the program threw "NullPointerException" when using the appendPage() method to merge PDF documents. |