Python: Convert HTML to PDF
HTML is the standard markup language for creating web pages, while PDF is a widely accepted format for sharing and preserving documents with consistent formatting across different platforms. By converting HTML to PDF, you can create printable documents, share web content offline, or generate reports with ease. In this article, you will learn how to convert a HTML file or a HTML string to PDF in Python using Spire.Doc for Python.
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your VS Code through the following pip command.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows
Convert an HTML File to PDF in Python
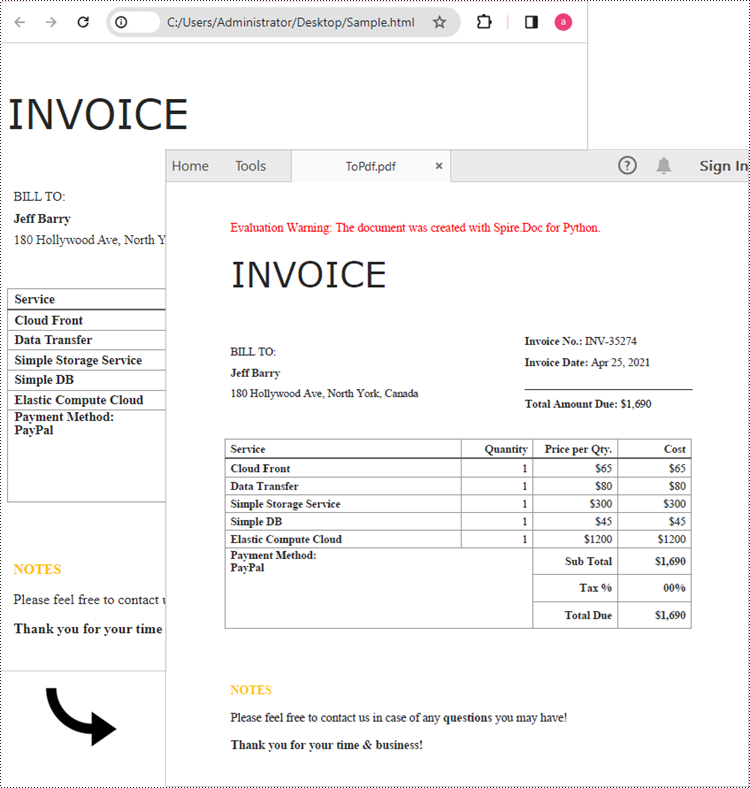
The Document.LoadFromFile method supports loading not only Doc or Docx files, but also HTML files. You can load an HTML file using this method and save it as a PDF file using the Document.SaveToFile() method. The following are the steps to convert an HTML file to PDF in Python.
- Create a Document object.
- Load an HTML file using Document.LoadFromFile() method.
- Convert it to PDF using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
document = Document()
# Load an HTML file
document.LoadFromFile("C:\\Users\\Administrator\\Desktop\\Sample.html", FileFormat.Html, XHTMLValidationType.none)
# Save the HTML file to a pdf file
document.SaveToFile("output/ToPdf.pdf", FileFormat.PDF)
document.Close()
Convert an HTML String to PDF in Python
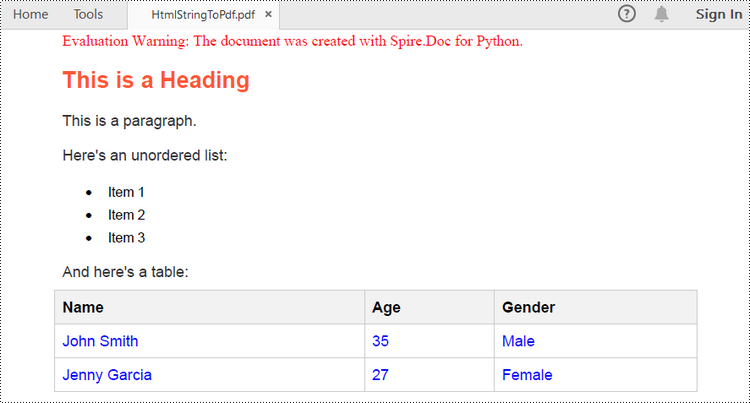
To render uncomplicated HTML strings (usually text and its formatting) on Word pages, you can use the Paragraph.AppendHTML() method. The Word document can be then saved as a PDF file using the Document.SaveToFile() method. The following are the steps to convert an HTML string to PDF in Python.
- Create a Document object.
- Add a section using Document.AddSection() method.
- Add a paragraph using Section.AddParagraph() method.
- Specify the HTML string.
- Add the HTML string to the paragraph using Paragraph.AppendHTML() method.
- Save the document as a PDF file using Document.SaveToFile() method.
- Python
from spire.doc import *
from spire.doc.common import *
# Create a Document object
document = Document()
# Add a section to the document
sec = document.AddSection()
# Add a paragraph to the section
paragraph = sec.AddParagraph()
# Specify the HTML string
htmlString = """
<html>
<head>
<title>HTML to Word Example</title>
<style>
body {
font-family: Arial, sans-serif;
}
h1 {
color: #FF5733;
font-size: 24px;
margin-bottom: 20px;
}
p {
color: #333333;
font-size: 16px;
margin-bottom: 10px;
}
ul {
list-style-type: disc;
margin-left: 20px;
margin-bottom: 15px;
}
li {
font-size: 14px;
margin-bottom: 5px;
}
table {
border-collapse: collapse;
width: 100%;
margin-bottom: 20px;
}
th, td {
border: 1px solid #CCCCCC;
padding: 8px;
text-align: left;
}
th {
background-color: #F2F2F2;
font-weight: bold;
}
td {
color: #0000FF;
}
</style>
</head>
<body>
<h1>This is a Heading</h1>
<p>This is a paragraph.</p>
<p>Here's an unordered list:</p>
<ul>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
<p>And here's a table:</p>
<table>
<tr>
<th>Name</th>
<th>Age</th>
<th>Gender</th>
</tr>
<tr>
<td>John Smith</td>
<td>35</td>
<td>Male</td>
</tr>
<tr>
<td>Jenny Garcia</td>
<td>27</td>
<td>Female</td>
</tr>
</table>
</body>
</html>
"""
# Append the HTML string to the paragraph
paragraph.AppendHTML(htmlString)
# Save the document as a pdf file
document.SaveToFile("output/HtmlStringToPdf.pdf", FileFormat.PDF)
document.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Insert or Remove Page Breaks in Excel
A page break is a markup that divides the content of a document or spreadsheet into multiple pages for printing or display. This feature can be used to adjust the page layout of a document to ensure that each page contains the appropriate information. By placing page breaks appropriately, you can also ensure that your document is presented in a better format and layout when printed. This article will explain how to insert or remove horizontal/vertical page breaks in Excel on the Python platform by using Spire.XLS for Python.
- Insert Horizontal Page Breaks in Excel Using Python
- Insert Vertical Page Breaks in Excel Using Python
- Remove Horizontal Page Breaks from Excel Using Python
- Remove Vertical Page Breaks from Excel Using Python
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your VS Code through the following pip commands.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
Insert Horizontal Page Breaks in Excel Using Python
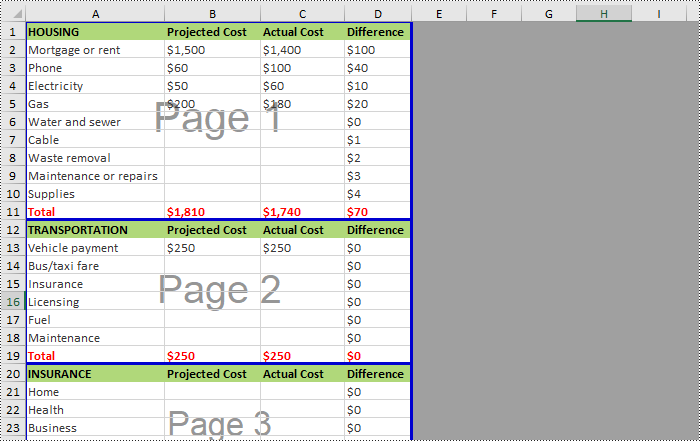
Spire.XLS for Python supports inserting horizontal page breaks to specified cell ranges by calling Worksheet.HPageBreaks.Add(CellRange) method. The following are detailed steps.
- Create a Workbook instance.
- Load an Excel file from disk using Workbook.LoadFromFile() method.
- Get a specified worksheet using Workbook.Worksheets[] property.
- Insert horizontal page breaks to specified cell ranges using Worksheet.HPageBreaks.Add(CellRange) method.
- Set view mode to Preview mode by Worksheet.ViewMode property.
- Save the result file using Workbook.SaveToFile() method.
- Python
from spire.xls import * from spire.xls.common import * inputFile = "C:/Users/Administrator/Desktop/Sample.xlsx" outputFile = "C:/Users/Administrator/Desktop/InsertHPageBreak.xlsx" #Create a Workbook instance workbook = Workbook() #Load an Excel file from disk workbook.LoadFromFile(inputFile) #Get the first worksheet of this file sheet = workbook.Worksheets[0] #Insert horizontal page breaks to specified cell ranges sheet.HPageBreaks.Add(sheet.Range["A12"]) sheet.HPageBreaks.Add(sheet.Range["A20"]) #Set view mode to Preview mode sheet.ViewMode = ViewMode.Preview #Save the result file workbook.SaveToFile(outputFile, ExcelVersion.Version2013) workbook.Dispose()
Insert Vertical Page Breaks in Excel Using Python
Spire.XLS for Python also supports inserting vertical page breaks to specified cell ranges by calling Worksheet.VPageBreaks.Add(CellRange) method. The following are detailed steps.
- Create a Workbook instance.
- Load an Excel file from disk using Workbook.LoadFromFile() method.
- Get a specified worksheet using Workbook.Worksheets[] property.
- Insert vertical page breaks to specified cell ranges using Worksheet.VPageBreaks.Add(CellRange) method.
- Set view mode to Preview mode using Worksheet.ViewMode property.
- Save the result file using Workbook.SaveToFile() method.
- Python
from spire.xls import * from spire.xls.common import * inputFile = "C:/Users/Administrator/Desktop/Sample.xlsx" outputFile = "C:/Users/Administrator/Desktop/InsertVPageBreak.xlsx" #Create a Workbook instance workbook = Workbook() #Load an Excel file from disk workbook.LoadFromFile(inputFile) #Get the first worksheet of this file sheet = workbook.Worksheets[0] #Insert vertical page breaks to specified cell ranges sheet.VPageBreaks.Add(sheet.Range["B1"]) sheet.VPageBreaks.Add(sheet.Range["D3"]) #Set view mode to Preview mode sheet.ViewMode = ViewMode.Preview #Save the result file workbook.SaveToFile(outputFile, ExcelVersion.Version2013) workbook.Dispose()
Remove Horizontal Page Breaks from Excel Using Python
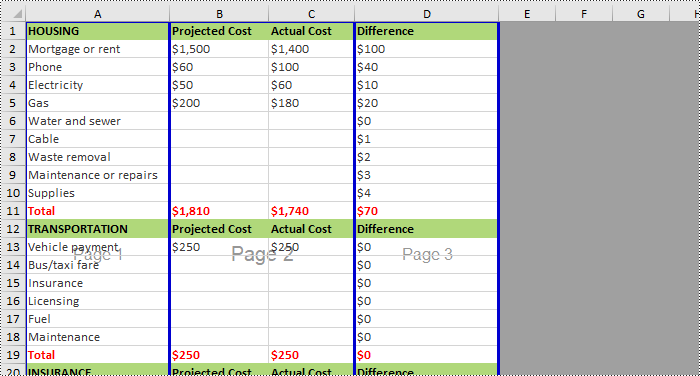
If you want to remove horizontal page breaks from Excel, call the Worksheet.HPageBreaks.RemoveAt() or Worksheet.HPageBreaks.Clear() methods. The following are detailed steps.
- Create a Workbook instance.
- Load an Excel file from disk using Workbook.LoadFromFile() method.
- Get a specified worksheet using Workbook.Worksheets[] property.
- Remove all the horizontal page breaks by calling Worksheet.HPageBreaks.Clear() method or remove a specific horizontal page break by calling Worksheet.HPageBreaks.RemoveAt() method.
- Set view mode to Preview mode using Worksheet.ViewMode property.
- Save the result file using Workbook.SaveToFile() method.
- Python
from spire.xls import * from spire.xls.common import * inputFile = "C:/Users/Administrator/Desktop/InsertHPageBreak.xlsx" outputFile = "C:/Users/Administrator/Desktop/RemoveHPageBreak.xlsx" #Create a Workbook instance workbook = Workbook() #Load an Excel file from disk workbook.LoadFromFile(inputFile) #Get the first worksheet from this file sheet = workbook.Worksheets[0] #Clear all the horizontal page breaks #sheet.HPageBreaks.Clear() #Remove the first horizontal page break sheet.HPageBreaks.RemoveAt(0) #Set view mode to Preview mode sheet.ViewMode = ViewMode.Preview #Save the result file workbook.SaveToFile(outputFile, ExcelVersion.Version2013) workbook.Dispose()
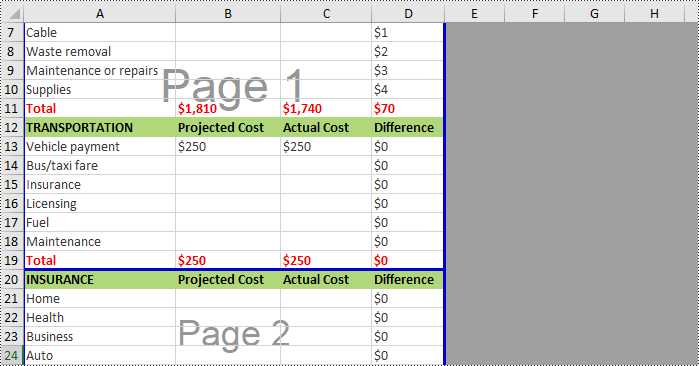
Remove Vertical Page Breaks from Excel Using Python
If you want to remove vertical page breaks from Excel, call the Worksheet.VPageBreaks.RemoveAt() or Worksheet.VPageBreaks.Clear() methods. The following are detailed steps.
- Create a Workbook instance.
- Load an Excel file from disk using Workbook.LoadFromFile() method.
- Get a specified worksheet using Workbook.Worksheets[] property.
- Remove all the vertical page breaks by calling Worksheet.VPageBreaks.Clear() method or remove a specific vertical page break by calling Worksheet.VPageBreaks.RemoveAt() method.
- Set view mode to Preview mode using Worksheet.ViewMode property.
- Save the result file using Workbook.SaveToFile() method.
- Python
from spire.xls import * from spire.xls.common import * inputFile = "C:/Users/Administrator/Desktop/InsertVPageBreak.xlsx" outputFile = "C:/Users/Administrator/Desktop/RemoveVPageBreak.xlsx" #Create a Workbook instance workbook = Workbook() #Load an Excel file from disk workbook.LoadFromFile(inputFile) #Get the first worksheet from this file sheet = workbook.Worksheets[0] #Clear all the vertical page breaks #sheet.VPageBreaks.Clear() #Remove the first vertical page break sheet.VPageBreaks.RemoveAt(0) #Set view mode to Preview mode sheet.ViewMode = ViewMode.Preview #Save the result file workbook.SaveToFile(outputFile, ExcelVersion.Version2013) workbook.Dispose()
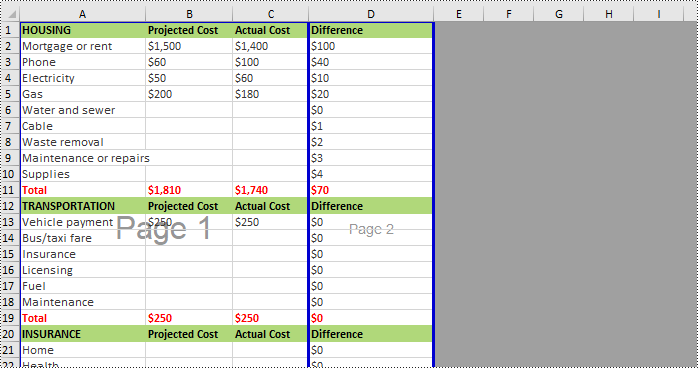
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Convert Word to EPUB
EPUB, short for Electronic Publication, is a widely used standard format for eBooks. It is an open and free format based on web standards, enabling compatibility with various devices and software applications. EPUB files are designed to provide a consistent reading experience across different platforms, including e-readers, tablets, smartphones, and computers. By converting your Word document to EPUB, you can ensure that your content is accessible and enjoyable to a broader audience, regardless of the devices and software they use. In this article, we will demonstrate how to convert Word documents to EPUB format in Python using Spire.Doc for Python.
Install Spire.Doc for Python
This scenario requires Spire.Doc for Python and plum-dispatch v1.7.4. They can be easily installed in your VS Code through the following pip commands.
pip install Spire.Doc
If you are unsure how to install, please refer to this tutorial: How to Install Spire.Doc for Python on Windows
Convert Word to EPUB in Python
The Document.SaveToFile(fileName:str, fileFormat:FileFormat) method provided by Spire.Doc for Python supports converting a Word document to EPUB format. The detailed steps are as follows.
- Create an object of the Document class.
- Load a Word document using Document.LoadFromFile() method.
- Save the Word document to EPUB format using Document.SaveToFile(fileName:str, fileFormat:FileFormat) method.
- Python
from spire.doc import * from spire.doc.common import * # Specify the input Word document and output EPUB file paths inputFile = "Sample.docx" outputFile = "ToEpub.epub" # Create an object of the Document class doc = Document() # Load a Word document doc.LoadFromFile(inputFile) # Save the Word document to EPUB format doc.SaveToFile(outputFile, FileFormat.EPub) # Close the Document object doc.Close()
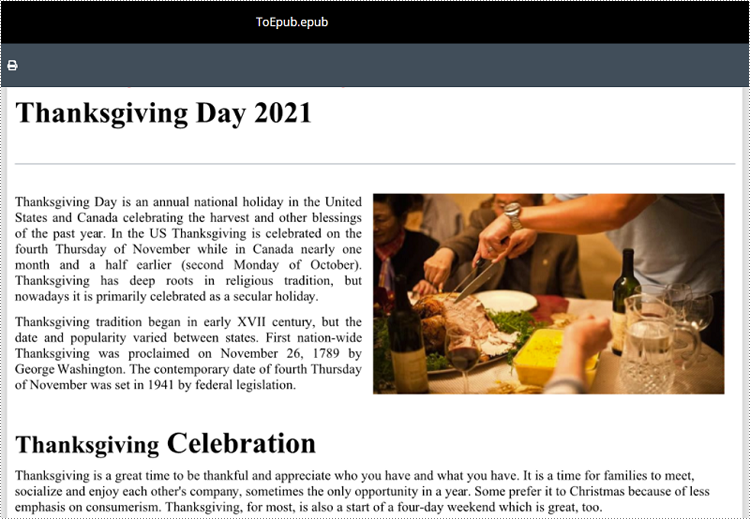
Convert Word to EPUB with a Cover Image in Python
Spire.Doc for Python enables you to convert a Word document to EPUB format and set a cover image for the resulting EPUB file by using the Document.SaveToEpub(fileName:str, coverImage:DocPicture) method. The detailed steps are as follows.
- Create an object of the Document class.
- Load a Word document using Document.LoadFromFile() method.
- Create an object of the DocPicture class, and then load an image using DocPicture.LoadImage() method.
- Save the Word document as an EPUB file and set the loaded image as the cover image of the EPUB file using Document.SaveToEpub(fileName:str, coverImage:DocPicture) method.
- Python
from spire.doc import * from spire.doc.common import * # Specify the input Word document and output EPUB file paths inputFile = "Sample.docx" outputFile = "ToEpubWithCoverImage.epub" # Specify the file path for the cover image imgFile = "Cover.png" # Create a Document object doc = Document() # Load the Word document doc.LoadFromFile(inputFile) # Create a DocPicture object picture = DocPicture(doc) # Load the cover image file picture.LoadImage(imgFile) # Save the Word document as an EPUB file and set the cover image doc.SaveToEpub(outputFile, picture) # Close the Document object doc.Close()
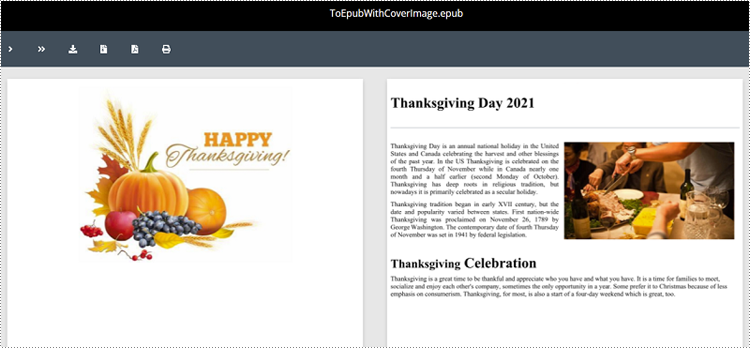
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Spire.Presentation for Java 8.12.1 supports loading encrypted stream files
We are excited to announce the release of Spire.Presentation for Java 8.12.1. This version improves the speed of converting PowerPoint to SVG. Moreover, it supports loading encrypted stream files, creating irregular polygons using coordinates, and drawing lines using two points. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | SPIREPPT-2395 | Improves the speed of converting PowerPoint to SVG. |
| New feature | SPIREPPT-2400 | Adds a method to load encrypted stream files.
presentation.loadFromStream(inputStream, FileFormat.AUTO,"password"); |
| New feature | SPIREPPT-2405 | Supports creating irregular polygons using coordinates.
Presentation ppt = new Presentation();
ISlide slide = ppt.getSlides().get(0);
List<Point2D> points = new ArrayList<>();
points.add(new Point2D.Float(50f, 50f));
points.add(new Point2D.Float(50f, 150f));
points.add(new Point2D.Float(60f, 200f));
points.add(new Point2D.Float(200f, 200f));
points.add(new Point2D.Float(220f, 150f));
points.add(new Point2D.Float(150f, 90f));
points.add(new Point2D.Float(50f, 50f));
IAutoShape autoShape = slide.getShapes().appendFreeformShape(points);
autoShape.getFill().setFillType(FillFormatType.NONE);
ppt.saveToFile("out.pptx", FileFormat.PPTX_2013);
ppt.dispose();
|
| New feature | SPIREPPT-2406 | Supports drawing lines using two points.
Presentation ppt = new Presentation(); ppt.getSlides().get(0).getShapes().appendShape(ShapeType.LINE, new Point2D.Float(50, 70), new Point2D.Float(150, 120)); ppt.saveToFile( "result.pptx ,FileFormat.PPIX_2013), ppt.dispose(). |
Converting Image to PDF with Python: 4 Code Examples
Table of Contents
Install with Pip
pip install Spire.PDF
Converting an image to PDF is a convenient and efficient way to transform a visual file into a portable, universally readable format. Whether you're working with a scanned document, a photo, or a digital image, converting it to PDF provides numerous benefits. It maintains the image's original quality and guarantees compatibility across diverse devices and operating systems. Moreover, converting images to PDF allows for easy sharing, printing, and archiving, making it a versatile solution for various professional, educational, and personal purposes. This article provides several examples showing you how to convert images to PDF using Python.
- Convert an Image to a PDF Document in Python
- Convert Multiple Images to a PDF Document in python
- Create a PDF from Multiple Images Customizing Page Margins in Python
- Create a PDF with Several Images per Page in Python
PDF Converter API for Python
If you want to turn image files into PDF format in a Python application, Spire.PDF for Python can help with this. It enables you to build a PDF document with custom page settings (size and margins), add one or more images to every single page, and save the final document as a PDF file. Various image forms are supported which include PNG, JPEG, BMP, and GIF images.
In addition to the conversion from images to PDF, this library supports converting PDF to Word, PDF to Excel, PDF to HTML, PDF to PDF/A with high quality and precision. As an advanced Python PDF library, it also provides a rich API for developers to customize the conversion options to meet a variety of conversion requirements.
The library can be installed by running the following pip command.
pip install Spire.PDF
Steps to Convert an Image to PDF in Python
- Initialize PdfDocument class.
- Load an image file from path using FromFile method.
- Add a page with the specified size to the document.
- Draw the image on the page at the specified location using DrawImage method.
- Save the document to a PDF file using SaveToFile method.
Convert an Image to a PDF Document in Python
This code example converts an image file to a PDF document using the Spire.PDF for Python library by creating a blank document, adding a page with the same dimensions as the image, and drawing the image onto the page.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Load a particular image
image = PdfImage.FromFile("C:\\Users\\Administrator\\Desktop\\Images\\img-1.jpg")
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page that has the same size as the image
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile("output/ImageToPdf.pdf")
doc.Dispose()

Convert Multiple Images to a PDF Document in python
This example illustrates how to convert a collection of images into a PDF document using Spire.PDF for Python. The following code snippet reads images from a specified folder, creates a PDF document, adds each image to a separate page in the PDF, and saves the resulting PDF file.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the page margins to 0
doc.PageSettings.SetMargins(0.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for file in files:
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, file))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Add a page that has the same size as the image
page = doc.Pages.Add(SizeF(width, height))
# Draw image at (0, 0) of the page
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile('output/ImagesToPdf.pdf')
doc.Dispose()

Create a PDF from Multiple Images Customizing Page Margins in Python
This code example creates a PDF document and populates it with images from a specified folder, adjusts the page margins and saves the resulting document to a file.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the left, top, right, bottom page margin
doc.PageSettings.SetMargins(30.0, 30.0, 30.0, 30.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for file in files:
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, file))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Specify page size
size = SizeF(width + doc.PageSettings.Margins.Left + doc.PageSettings.Margins.Right, height + doc.PageSettings.Margins.Top+ doc.PageSettings.Margins.Bottom)
# Add a page with the specified size
page = doc.Pages.Add(size)
# Draw image on the page at (0, 0)
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
# Save to file
doc.SaveToFile('output/CustomizeMargins.pdf')
doc.Dispose()

Create a PDF with Several Images per Page in Python
This code demonstrates how to use the Spire.PDF library in Python to create a PDF document with two images per page. The images in this example are the same size, if your image size is not consistent, then you need to adjust the code to achieve a desired result.
- Python
from spire.pdf.common import *
from spire.pdf import *
import os
# Create a PdfDocument object
doc = PdfDocument()
# Set the left, top, right, bottom page margins
doc.PageSettings.SetMargins(15.0, 15.0, 15.0, 15.0)
# Get the folder where the images are stored
path = "C:\\Users\\Administrator\\Desktop\\Images\\"
files = os.listdir(path)
# Iterate through the files in the folder
for root, dirs, files in os.walk(path):
for i in range(len(files)):
# Load a particular image
image = PdfImage.FromFile(os.path.join(root, files[i]))
# Get the image width and height
width = image.PhysicalDimension.Width
height = image.PhysicalDimension.Height
# Specify page size
size = SizeF(width + doc.PageSettings.Margins.Left + doc.PageSettings.Margins.Right, height*2 + doc.PageSettings.Margins.Top+ doc.PageSettings.Margins.Bottom + 15.0)
if i % 2 == 0:
# Add a page with the specified size
page = doc.Pages.Add(size)
# Draw first image on the page at (0, 0)
page.Canvas.DrawImage(image, 0.0, 0.0, width, height)
else :
# Draw second image on the page at (0, height + 15)
page.Canvas.DrawImage(image, 0.0, height + 15.0, width, height)
# Save to file
doc.SaveToFile('output/SeveralImagesPerPage.pdf')
doc.Dispose()
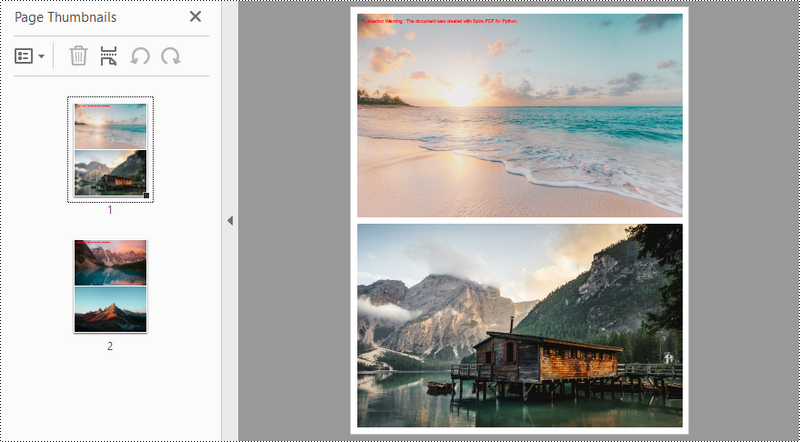
Conclusion
In this blog post, we explored how to use Spire.PDF for python to create PDF documents from images, containing one or more images per page. Additionally, we demonstrated how to customize the PDF page size and the margins around the images. For more tutorials, please check out our online documentation. If you have any questions, feel free to contact us by email or on the forum.
Spire.OCR for Java 1.9.2 fixes the issue that the the program threw exception when running under JDK17 and JDK21
We are happy to announce the release of Spire.OCR for Java 1.9.2. This version fixes the issue that the program threw exception when running under JDK17 and JDK21. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| Bug | - | Fixes the issue that the program threw “java.lang.NoClassDefFoundError” exception when running under JDK17 and JDK21. |
Spire.XLS for Python 13.12.6 adds the custom exception class SpireException
We are delighted to announce the release of Spire.XLS for Python 13.12.6. This version adds the custom exception class SpireException and changes the ArgumentError class to the SpireException class. More details are listed below.
Here is a list of changes made in this release
| Category | ID | Description |
| New feature | - | Adds the custom exception class SpireException and changes the ArgumentError class to the SpireException class. |
Python PDF to Text Conversion: Retrieve Text from PDFs
Table of Contents
Install with Pip
pip install Spire.PDF
Related Links
In today's digital age, the ability to extract information from PDF documents quickly and efficiently is crucial for various industries and professionals. Whether you're a researcher, data analyst, or simply dealing with a large volume of PDF files, being able to convert PDFs to editable text format can save you valuable time and effort. This is where Python, a versatile and powerful programming language, comes to the rescue with its extensive features for converting PDF to text in Python.

In this article, we will explore how to use Python for PDF to text conversion, unleashing the power of Python in PDF file processing. This article includes the following topics:
- Python API for PDF to Text Conversion
- Guide for Converting PDF to Text in Python
- Python to Convert PDF to Text Without Keeping Layout
- Python to Convert PDF to Text and Keep Layout
- Python to Convert a Specified PDF Page Area to Text
- Get a Free License for the API to Convert PDF to Text in Python
- Learn More About PDF Processing with Python
Python API for PDF to Text Conversion
To use Python for PDF to text conversion, a PDF processing API – Spire.PDF for Python is needed. This Python library is designed for PDF document manipulation in Python programs, which empowers Python programs with various PDF processing abilities.
We can download Spire.PDF for Python and add it to our project, or simply install it through PyPI with the following code:
pip install Spire.PDF
Guide for Converting PDF to Text in Python
Before we proceed with converting PDF to text using Python, let's take a look at the main advantages it can offer us:
- Editability: Converting PDF to text enables you to edit the document more easily, as text files can be opened and edited on most devices.
- Accessibility: Text files are generally more accessible than PDFs. Whether it's a desktop or mobile phone, text files can be viewed on devices with ease.
- Integration with other applications: Text files can be seamlessly integrated into various applications and workflows.
Steps for converting PDF documents to text files in Python:
- Install Spire.PDF for Python.
- Import modules.
- Create an object of PdfDocument class and load a PDF file using LoadFromFile() method.
- Create an object of PdfTextExtractOptions class and set the text extracting options, including extracting all text, showing hidden text, only extracting text in a specified area, and simple extraction.
- Get a page in the document using PdfDocument.Pages.get_Item() method and create PdfTextExtractor objects based on each page to extract the text from the page using Extract() method with specified options.
- Save the extracted text as a text file and close the PdfDocument object.
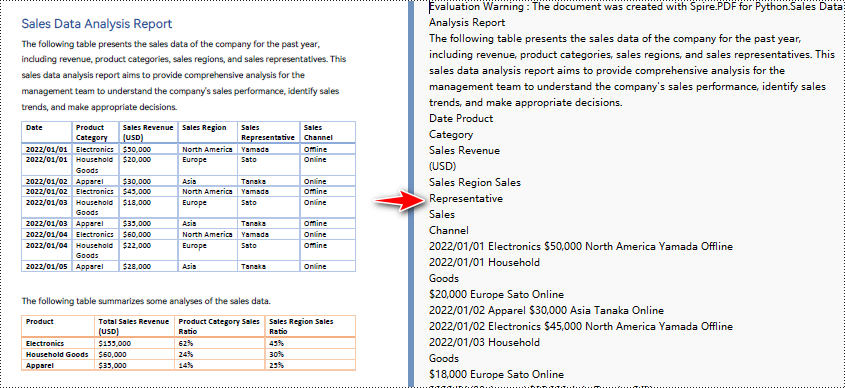
Python to Convert PDF to Text Without Keeping Layout
When using the simple extraction method to extract text from PDF, the program will not retain the blank areas and keep track of the current Y position of each string and insert a line break into the output if the Y position has changed.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to use simple extraction method
extract_options.IsSimpleExtraction = True
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
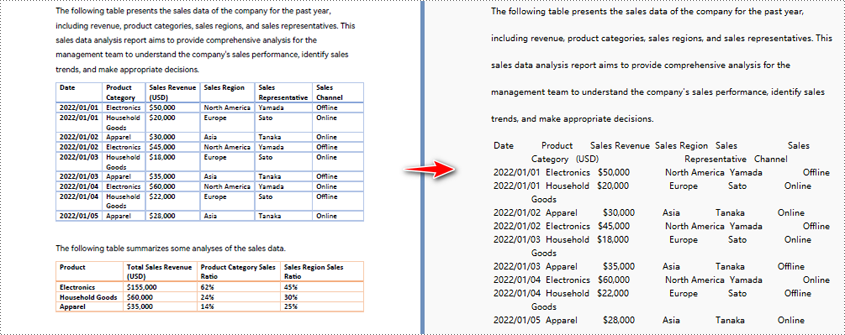
Python to Convert PDF to Text and Keep Layout
When using the default extraction method to extract text from PDF, the program will extract text line by line including blanks.
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create a string object to store the text
extracted_text = ""
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Loop through the pages in the document
for i in range(pdf.Pages.Count):
# Get a page
page = pdf.Pages.get_Item(i)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
text = text_extractor.ExtractText(extract_options)
# Add the extracted text to the string object
extracted_text += text
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
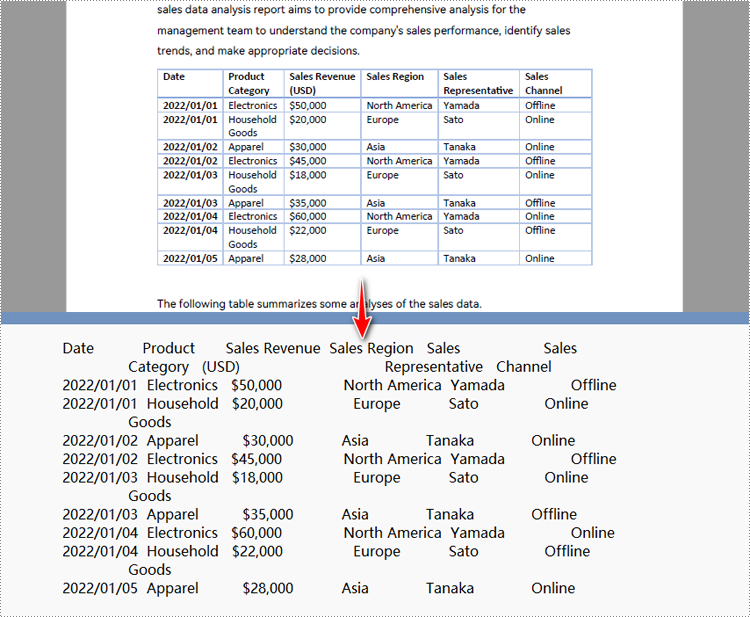
Python to Convert a Specified PDF Page Area to Text
- Python
from spire.pdf import PdfDocument
from spire.pdf import PdfTextExtractOptions
from spire.pdf import PdfTextExtractor
from spire.pdf import RectangleF
# Create an object of PdfDocument class and load a PDF file
pdf = PdfDocument()
pdf.LoadFromFile("Sample.pdf")
# Create an object of PdfExtractor
extract_options = PdfTextExtractOptions()
# Set to extract specific page area
extract_options.ExtractArea = RectangleF(50.0, 220.0, 700.0, 230.0)
# Get a page
page = pdf.Pages.get_Item(0)
# Create an object of PdfTextExtractor passing the page as paramter
text_extractor = PdfTextExtractor(page)
# Extract the text from the page
extracted_text = text_extractor.ExtractText(extract_options)
# Write the extracted text to a text file
with open("output/ExtractedText.txt", "w") as file:
file.write(extracted_text)
pdf.Close()
Get a Free License for the API to Convert PDF to Text in Python
Users can apply for a free temporary license to try Spire.PDF for Python and evaluate the Python PDF to Text Conversion features without any limitations.
Learn More About PDF Processing with Python
Apart from converting PDF to text with Python, we can also explore more PDF processing features of this API through the following sources:
- How to Extract Text from PDF Documents with Python
- Tutorials for PDF Processing with Python
- Converting Image-Based PDF Documents to Text (OCR)
Conclusion
In this blog post, we have explored Python in PDF to text conversion. By following the operational steps and referring to the code examples in the article, we can achieve fast PDF to text conversion in Python programs. Additionally, the article provides insights into the benefits of converting PDF documents to text files. More importantly, we can gain further knowledge on handling PDF documents with Python and methods to convert image-based PDF documents to text through OCR tools from the references in the article. If any issues arise during the usage of Spire.PDF for Python, technical support can be obtained by reaching out to our team via the Spire.PDF forum or email.
Python: Convert SVG to PDF
SVG files are commonly used for web graphics and vector-based illustrations because they can be scaled and adjusted easily. PDF, on the other hand, is a versatile format widely supported across different devices and operating systems. Converting SVG to PDF allows for easy sharing of graphics and illustrations, ensuring that recipients can open and view the files without requiring specialized software or worrying about browser compatibility issues. In this article, we will demonstrate how to convert SVG files to PDF format in Python using Spire.PDF for Python.
Install Spire.PDF for Python
This scenario requires Spire.PDF for Python and plum-dispatch v1.7.4. They can be easily installed in your VS Code through the following pip command.
pip install Spire.PDF
If you are unsure how to install, please refer to this tutorial: How to Install Spire.PDF for Python on Windows
Convert SVG to PDF in Python
Spire.PDF for Python provides the PdfDocument.LoadFromSvg() method, which allows users to load an SVG file. Once loaded, users can use the PdfDocument.SaveToFile() method to save the SVG file as a PDF file. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load an SVG file using PdfDocument.LoadFromSvg() method.
- Save the SVG file to PDF format using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc = PdfDocument()
# Load an SVG file
doc.LoadFromSvg("Sample.svg")
# Save the SVG file to PDF format
doc.SaveToFile("ConvertSvgToPdf.pdf", FileFormat.PDF)
# Close the PdfDocument object
doc.Close()
Add SVG to PDF in Python
In addition to converting SVG to PDF directly, Spire.PDF for Python also supports adding SVG files to specific locations in PDF. The detailed steps are as follows.
- Create an object of the PdfDocument class.
- Load an SVG file using PdfDocument.LoadFromSvg() method.
- Create a template based on the content of the SVG file using PdfDocument. Pages[].CreateTemplate() method.
- Get the width and height of the template.
- Create another object of the PdfDocument class and load a PDF file using PdfDocument.LoadFromFile() method.
- Draw the template with a custom size at a specific location in the PDF file using PdfDocument.Pages[].Canvas.DrawTemplate() method.
- Save the result file using PdfDocument.SaveToFile() method.
- Python
from spire.pdf.common import *
from spire.pdf import *
# Create a PdfDocument object
doc1 = PdfDocument()
# Load an SVG file
doc1.LoadFromSvg("Sample.svg")
# Create a template based on the content of the SVG
template = doc1.Pages[0].CreateTemplate()
# Get the width and height of the template
width = template.Width
height = template.Height
# Create another PdfDocument object
doc2 = PdfDocument()
# Load a PDF file
doc2.LoadFromFile("Sample.pdf")
# Draw the template with a custom size at a specific location on the first page of the loaded PDF file
doc2.Pages[0].Canvas.DrawTemplate(template, PointF(10.0, 100.0), SizeF(width*0.8, height*0.8))
# Save the result file
doc2.SaveToFile("AddSvgToPdf.pdf", FileFormat.PDF)
# Close the PdfDocument objects
doc2.Close()
doc1.Close()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.
Python: Convert Excel to Open XML or Open XML to Excel
In the context of Excel, Open XML refers to the underlying file format used by Excel to store spreadsheet data, formatting, formulas, and other related information. It provides a powerful and flexible basis for working with Excel files programmatically.
By converting Excel to Open XML, developers gain greater control and automation when working with spreadsheet-related tasks. In turn, you can also generate Excel files from Open XML to take advantage of Excel's built-in capabilities to perform advanced data operations. In this article, you will learn how to convert Excel to Open XML or Open XML to Excel in Python using Spire.XLS for Python.
Install Spire.XLS for Python
This scenario requires Spire.XLS for Python and plum-dispatch v1.7.4. They can be easily installed in your VS Code through the following pip command.
pip install Spire.XLS
If you are unsure how to install, please refer to this tutorial: How to Install Spire.XLS for Python on Windows
Convert Excel to Open XML in Python
Spire.XLS for Python offers the Workbook.SaveAsXml() method to save an Excel file in Open XML format. The following are the detailed steps.
- Create a Workbook object.
- Load an Excel file using Workbook.LoadFromFile() method.
- Save the Excel file in Open XML format using Workbook.SaveAsXml() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Excel file
workbook.LoadFromFile("sample.xlsx")
# Save the Excel file in Open XML file format
workbook.SaveAsXml("ExcelToXML.xml")
workbook.Dispose()
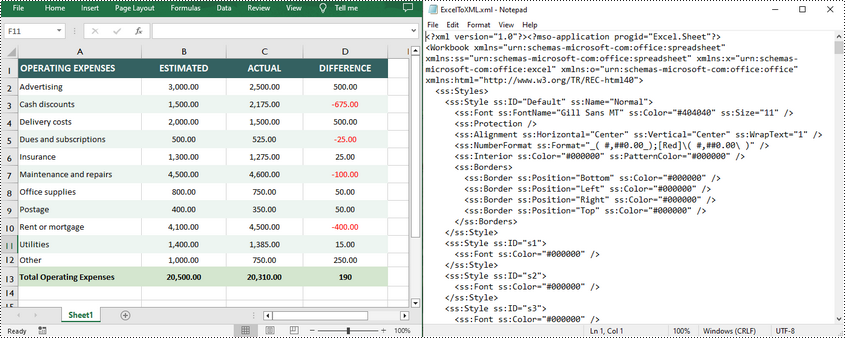
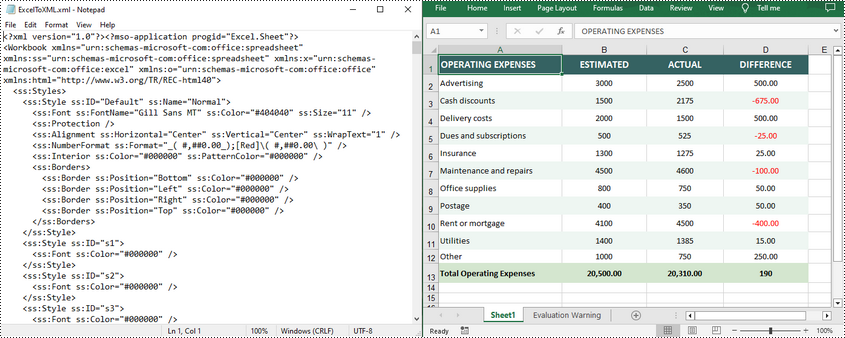
Convert Open XML to Excel in Python
To convert an Open XML file to Excel, you need to load the Open XML file through the Workbook.LoadFromXml() method, and then call the Workbook.SaveToFile() method to save it as an Excel file. The following are the detailed steps.
- Create a Workbook object.
- Load an Open XML file using Workbook.LoadFromXml() method.
- Save the Open XML file to Excel using Workbook.SaveToFile() method.
- Python
from spire.xls import *
from spire.xls.common import *
# Create a Workbook object
workbook = Workbook()
# Load an Open XML file
workbook.LoadFromXml("ExcelToXML.xml")
# Save the Open XML file to Excel XLSX format
workbook.SaveToFile("XMLToExcel.xlsx", ExcelVersion.Version2016)
workbook.Dispose()
Apply for a Temporary License
If you'd like to remove the evaluation message from the generated documents, or to get rid of the function limitations, please request a 30-day trial license for yourself.