Spire.PDF for .NET is a PDF library which enables users to handle the whole PDF document with wide range of tasks in C#, VB.NET. Spire.PDF supports to create PDF links, extract PDF links, update PDF links and remove PDF links from a PDF file. This article mainly shows how to extract and update link from a PDF file in C#.
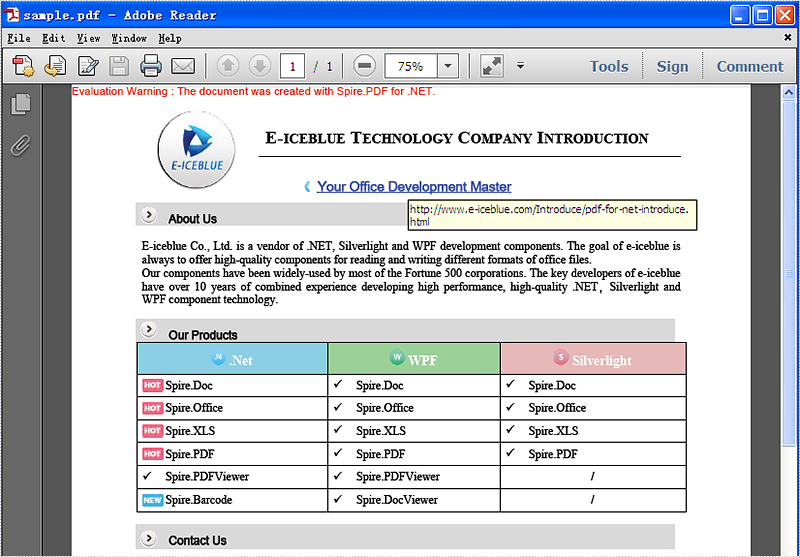
Before the steps and codes, please check the original PDF file at first:
Firstly we need to create a new Document object and load a PDF file which needs to extract and update the links. The links are represented as annotations in a PDF file. Before extract and update the link from a PDF file, we need to extract all the AnnotationsWidget objects.
The following code snippet shows you how to extract links from the PDF file.
//Load an existing PDF file
PdfDocument document = new PdfDocument();
document.LoadFromFile(@"..\..\output.pdf");
//Get the first page
PdfPageBase page = document.Pages[0];
//Get the annotation collection
PdfAnnotationCollection widgetCollection = page.AnnotationsWidget;
//Verify whether widgetCollection is not null or not
if (widgetCollection.Count > 0)
{
foreach (var obj in widgetCollection)
{
//Get the TextWebLink Annotation
if (obj is PdfTextWebLinkAnnotationWidget)
{
PdfTextWebLinkAnnotationWidget link = obj as PdfTextWebLinkAnnotationWidget;
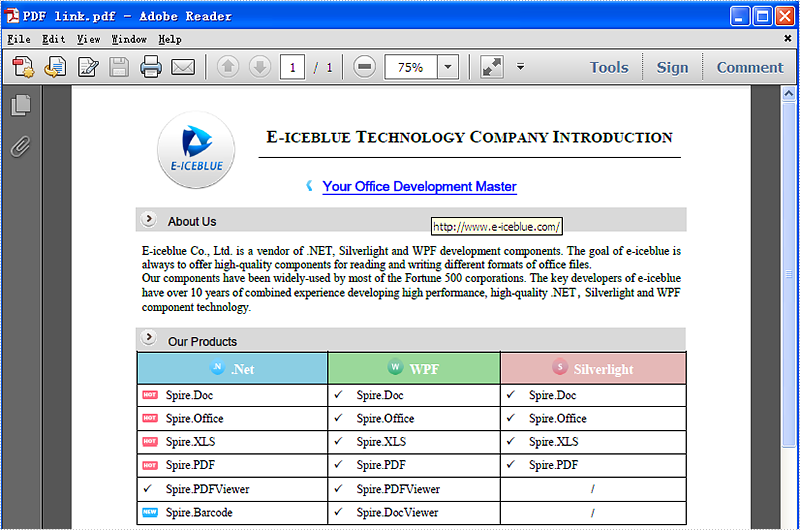
The following code snippet shows you how to update the link in PDF file
//Change the url of TextWebLink Annotation
link.Url = "http://www.e-iceblue.com/Introduce/pdf-for-net-introduce.html";
//Saves PDF document to file.
document.SaveToFile("sample.pdf");
This picture will show you the link has been updated in the PDF file.